维护网站英语网站图片怎么做白色背景
RK3588是一款低功耗、高性能的处理器,适用于基于arm的PC和Edge计算设备、个人移动互联网设备等数字多媒体应用,RK3588支持8K视频编解码,内置GPU可以完全兼容OpenGLES 1.1、2.0和3.2。RK3588引入了新一代完全基于硬件的最大4800万像素ISP,内置NPU,支持INT4/INT8/INT16/FP16混合运算能力,支持安卓12和、Debian11、Build root、Ubuntu20和22版本登系统。了解更多信息可点击迅为官网
【粉丝群】258811263
【实验平台】:迅为RK3588开发板
【内容来源】《iTOP-3588开发板手册》
【全套资料及网盘获取方式】联系淘宝客服加入售后技术支持群内下载
【视频介绍】:【强者之芯】 新一代AIOT高端应用芯片 iTOP -3588人工智能工业AI主板
第6章 安装Samba
Samba最大的功能就是可以用于Linux与windows系统共享文件夹,搭建SMB服务首先要保证windows和ubuntu网络互通,然后在ubuntu下载安装:
sudo apt-get install samba
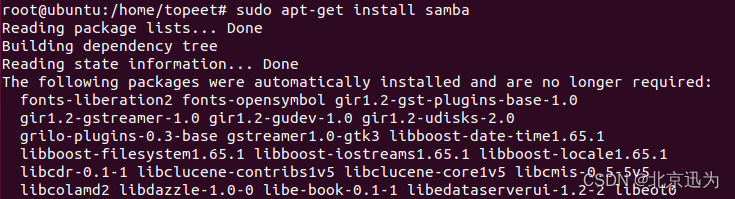
安装完成之后,在home目录下使用以下命令创建共享文件夹samba如下图所示:
mkdir samba
然后使用以下命令赋予samba文件权限,如下图所示:

使用以下命令进入samba文件夹内并创建topeet文件夹,如下图所示:
cd samba
touch topeet

然后使用以下命令对samba的配置文件进行内容的修改:
vim /etc/samba/smb.conf
添加内容如下图所示:
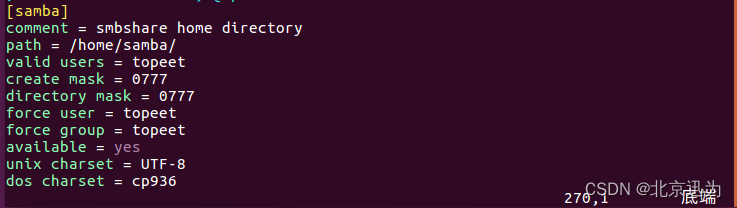
[samba]
comment = smbshare home directory
path = /home/samba/ #输入自己的路径
valid users = topeet #用户名
create mask = 0777
directory mask = 0777
force user = topeet #当前ubuntu用户名
force group = topeet #当前用户名所在的组
available = yes
unix charset = UTF-8
dos charset = cp936
完成后如下图:
 每个参数对应的说明表如下所示:
每个参数对应的说明表如下所示:
| [samba]: | 整体环境 |
| Comment: | samba注释说明 |
| Path: | 共享目录的说明 |
| public : | 是否公开共享: |
| Writeable | :可读写 |
| valid users: | 允许登陆的用户名 |
| create mask: | 设置创建文件设定的权限 |
| directory mask: | 设置创建文件夹设定的权限 |
| force user: | 设置强制设定新建文件所属 |
| force group: | 用户组 |
| Available: | 指定该共享资源是否可用 |
改完配置文件后保存,然后使用命令设置用户密码:
smbpasswd -a topeet

然后使用以下命令重启samba服务,如下图所示:
service smbd restart
至此ubuntu虚拟机的samba服务就搭建完成了,接下来在windows系统访问Samba文件夹进行测试。
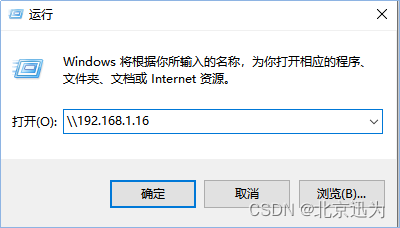
在windows上输入“win+r”弹出运行窗口,然后输入ubuntu的IP如下图所示:
\\192.168.1.16
点击确定后会弹出设置好的共享文件夹:
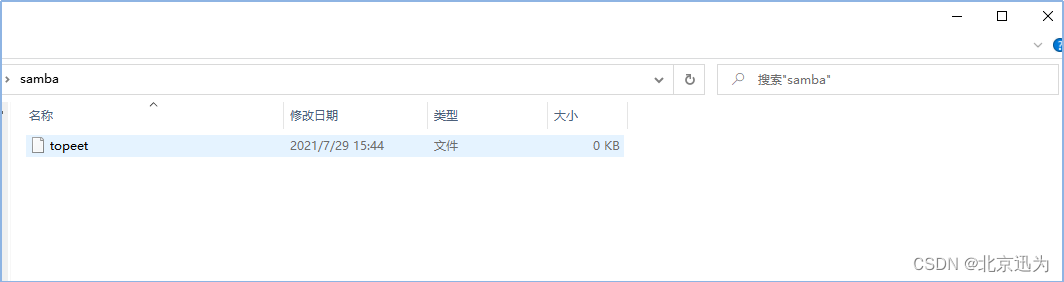
 双击进入,输入设置好的密码,进入后即可看到共享的文件topeet:
双击进入,输入设置好的密码,进入后即可看到共享的文件topeet:
 到这里Samba服务的测试就完成了。
到这里Samba服务的测试就完成了。