wordpress插件 stock爱站网站长seo综合查询
体育竞技分析
问题分析
体育竞技分析
需求:毫厘是多少?
如何科学分析体育竞技比赛?
输入:球员的水平
输出:可预测的比赛成绩
体育竞技分析:模拟N场比赛
计算思维:抽象 + 自动化
模拟:抽象比赛过程 + 自动化执行N场比赛
当N越大时,比赛结果分析会越科学
比赛规则
双人击球比赛:A & B,回合制,5局3胜
开始时一方先发球,直至判分,接下来胜者发球
球员只能在发球局得分,15分胜一局
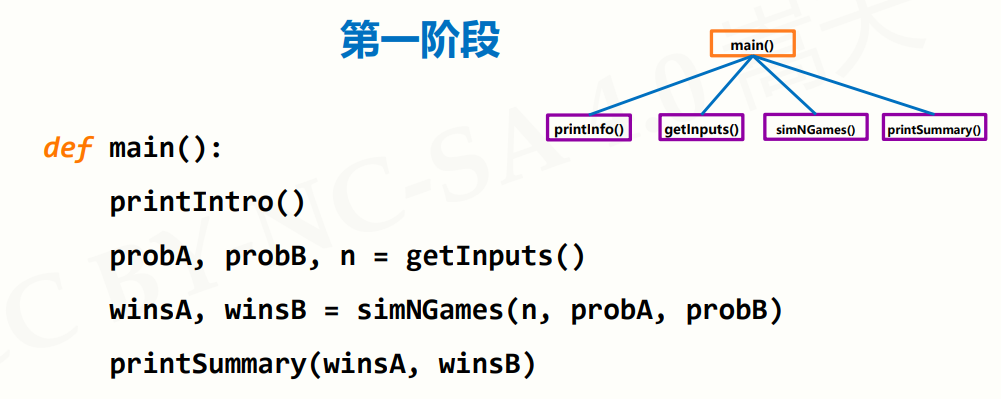
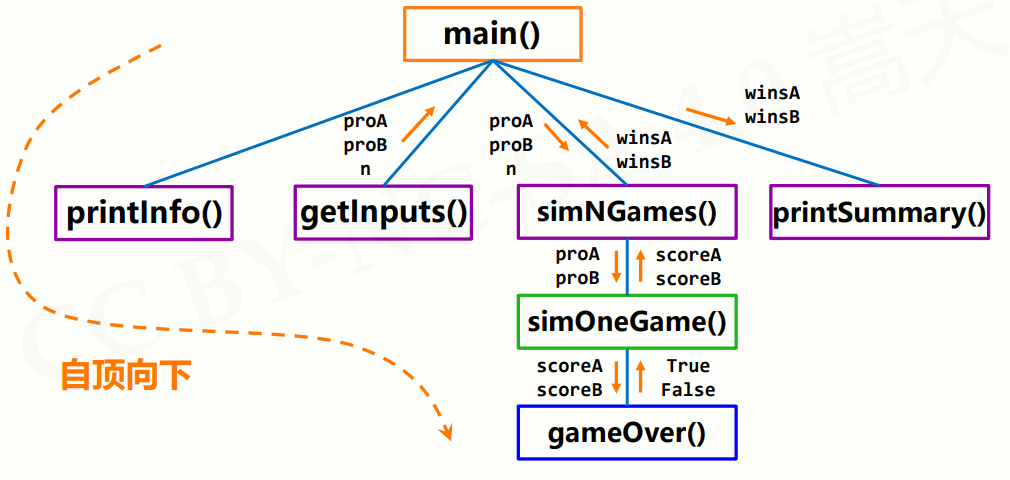
这要说到俩个概念,自顶向下的设计和自底向上的执行
自顶向下 解决复杂问题的有效方法
将一个总问题表达为若干个小问题组成的形式
使用同样方法进一步分解小问题
直至,小问题可以用计算机简单明了的解决
自底向上(执行)
逐步组建复杂系统的有效测试方法
分单元测试,逐步组装
按照自顶向下相反的路径操作
直至,系统各部分以组装的思路都经过测试和验证






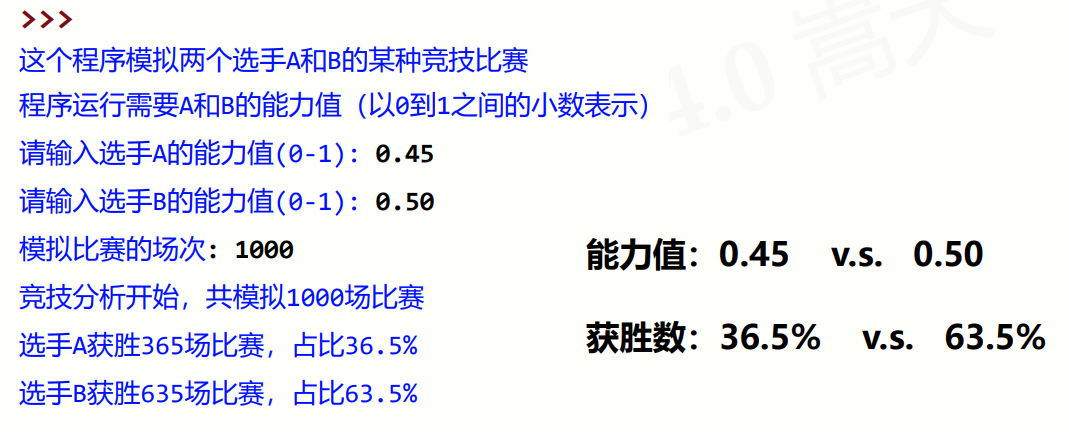
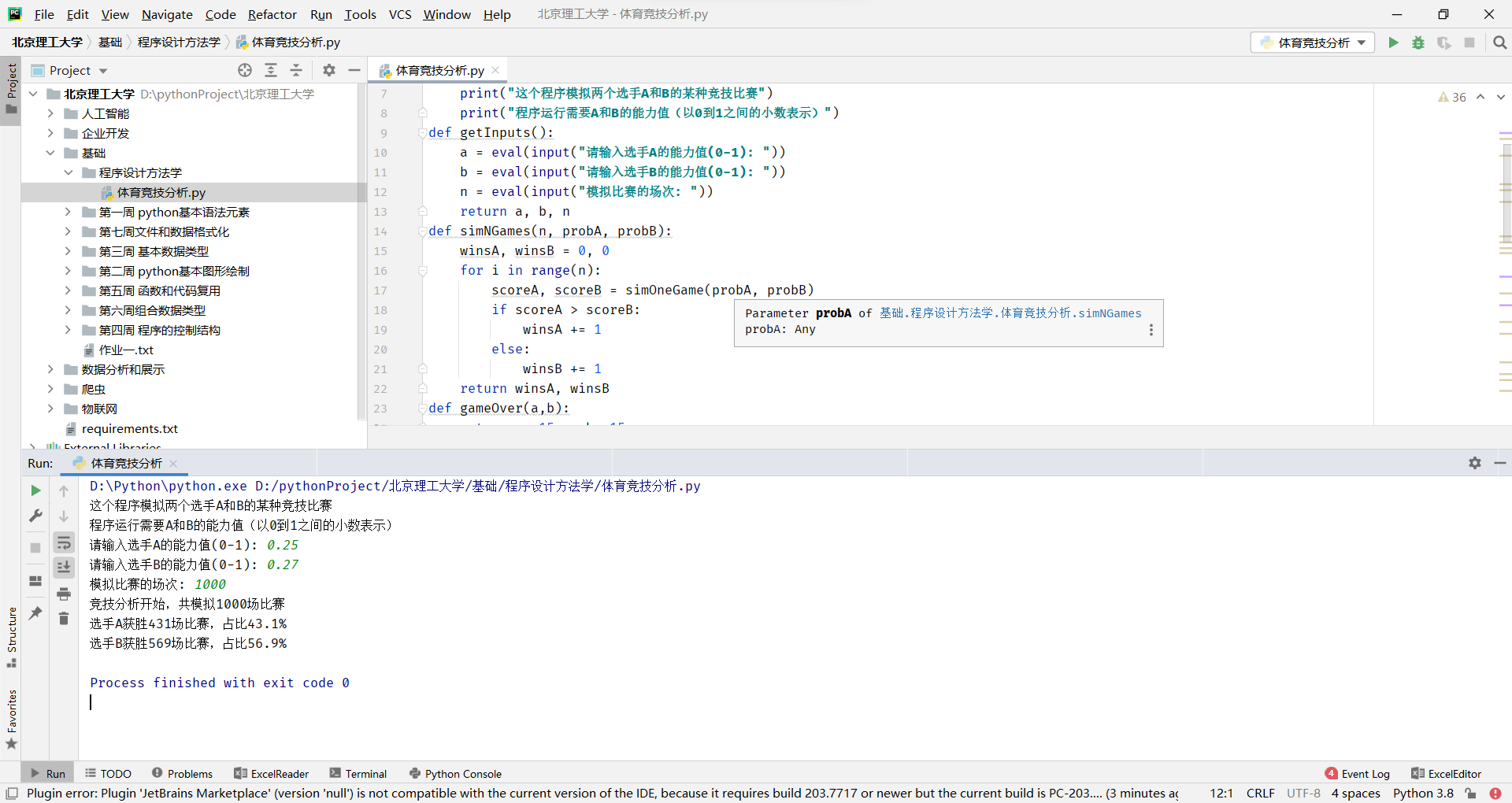
这是一个Python程序,用于模拟两个选手A和B进行某种竞技比赛的结果,并给出比赛结果的统计分析。
首先,程序定义了几个函数:
- printIntro():用于打印程序的简要介绍。
- getInputs():用于获取用户输入的选手A和B的能力值,以及模拟比赛的场次。
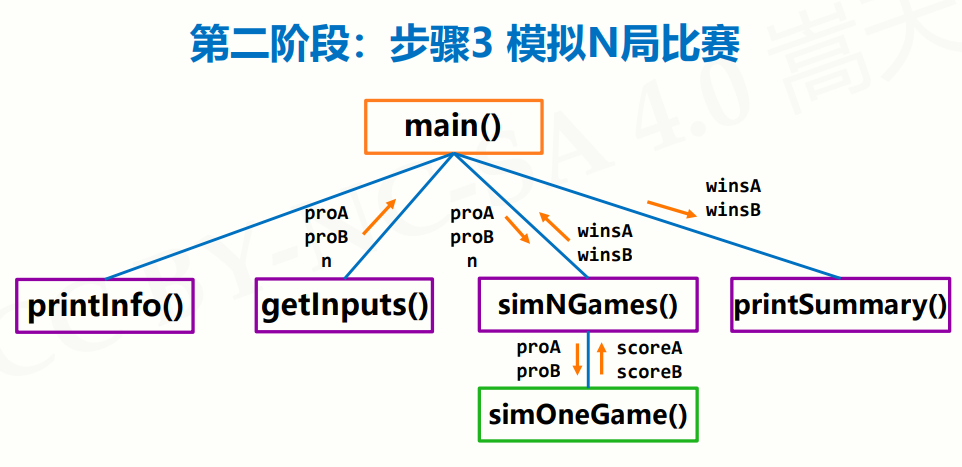
- simNGames(n, probA, probB):用于模拟n场比赛,并返回选手A和B的胜场数。
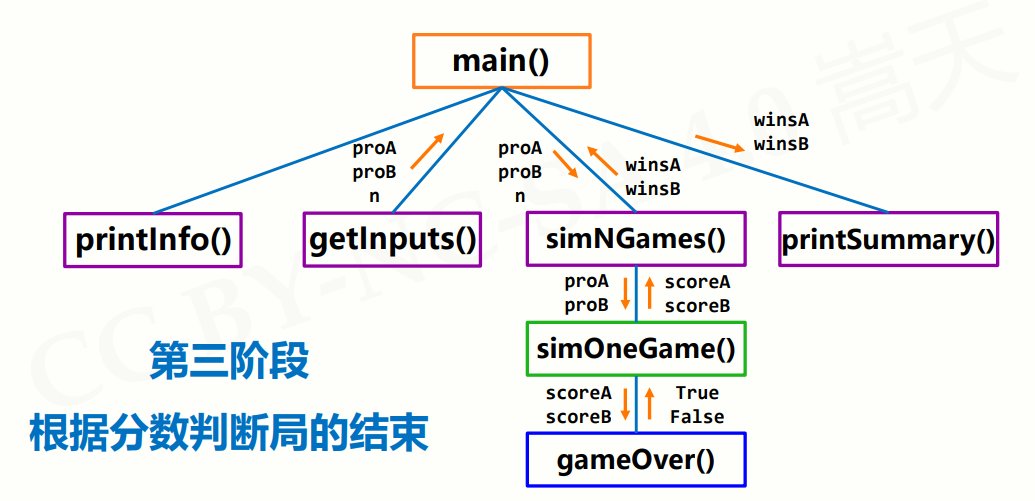
- gameOver(a,b):用于判断比赛是否结束,当选手A或B的得分达到15分时比赛结束。
- simOneGame(probA, probB):用于模拟一场比赛的结果,返回选手A和B的得分。
- printSummary(winsA, winsB):用于打印竞技分析结果,包括模拟比赛的场次、选手A和B的获胜场次及占比。
然后,程序调用main()函数,依次执行以下操作:
- 打印程序的简要介绍。
- 获取用户输入的选手A和B的能力值,以及模拟比赛的场次。
- 模拟n场比赛,并返回选手A和B的胜场数。
- 打印竞技分析结果,包括模拟比赛的场次、选手A和B的获胜场次及占比。
总体来说,该程序是一个简单的竞技分析模拟程序,通过随机数模拟比赛结果,并对比赛结果进行统计分析,得出选手A和B的胜率。
#!/usr/bin/env python
# -- coding: utf-8 --
# @Time : 2023/4/11 16:50
# @File : 体育竞技分析.py
from random import random
def printIntro():print("这个程序模拟两个选手A和B的某种竞技比赛")print("程序运行需要A和B的能力值(以0到1之间的小数表示)")
def getInputs():a = eval(input("请输入选手A的能力值(0-1): "))b = eval(input("请输入选手B的能力值(0-1): "))n = eval(input("模拟比赛的场次: "))return a, b, n
def simNGames(n, probA, probB):winsA, winsB = 0, 0for i in range(n):scoreA, scoreB = simOneGame(probA, probB)if scoreA > scoreB:winsA += 1else:winsB += 1return winsA, winsB
def gameOver(a,b):return a==15 or b==15
def simOneGame(probA, probB):scoreA, scoreB = 0, 0serving = "A"while not gameOver(scoreA, scoreB):if serving == "A":if random() < probA:scoreA += 1else:serving="B"else:if random() < probB:scoreB += 1else:serving="A"return scoreA, scoreB
def printSummary(winsA, winsB):n = winsA + winsBprint("竞技分析开始,共模拟{}场比赛".format(n))print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA, winsA/n))print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB, winsB/n))
def main():printIntro()probA, probB, n = getInputs()winsA, winsB = simNGames(n, probA, probB)printSummary(winsA, winsB)
main()python程序设计思维
计算思维与程序设计
第3种人类思维特征
逻辑思维:推理和演绎,数学为代表,A->B B->C A->C -
实证思维:实验和验证,物理为代表,引力波<-实验 -
计算思维:设计和构造,计算机为代表,汉诺塔递归
抽象和自动化
计算思维:Computational Thinking
抽象问题的计算过程,利用计算机自动化求解
计算思维是基于计算机的思维方式
 以前就是实证思维,通过查询当地的历史天气的数据,并且根据这样的经验,来猜测第二天的温度。实证思维通过物理,经验的东西来构造未来的值
以前就是实证思维,通过查询当地的历史天气的数据,并且根据这样的经验,来猜测第二天的温度。实证思维通过物理,经验的东西来构造未来的值
计算思维,就是通过计算机来演算天气,这样数据更加精确
计算生态与python语言

优质的计算生态Python123 - 编程更简单
用户体验与软件产品





应用开发的四个步骤


注:内容来自慕课--嵩天老师