数据交易网站源码襄阳南漳县城乡建设局网站
目录
摘要:
代码主要内容:
研究背景:
微电网模型:
粒子群算法:
运行结果:
Matlab代码分享:
摘要:
提出了一种经济与环保相协调的微电网优化调度模型,针对光伏电池、风机、微型燃气轮机、柴油发电机以及蓄电池组成的微电网系统的优化问题进行研究,在满足系统约束条件下,建立了包含运行成本的微电网经济性目标优化调度模型,并利用粒子群算法(PSO)求解微电网优化调度问题,仿真结果表明该模型对微电网优化调度具有一定的指导作用。
代码主要内容:
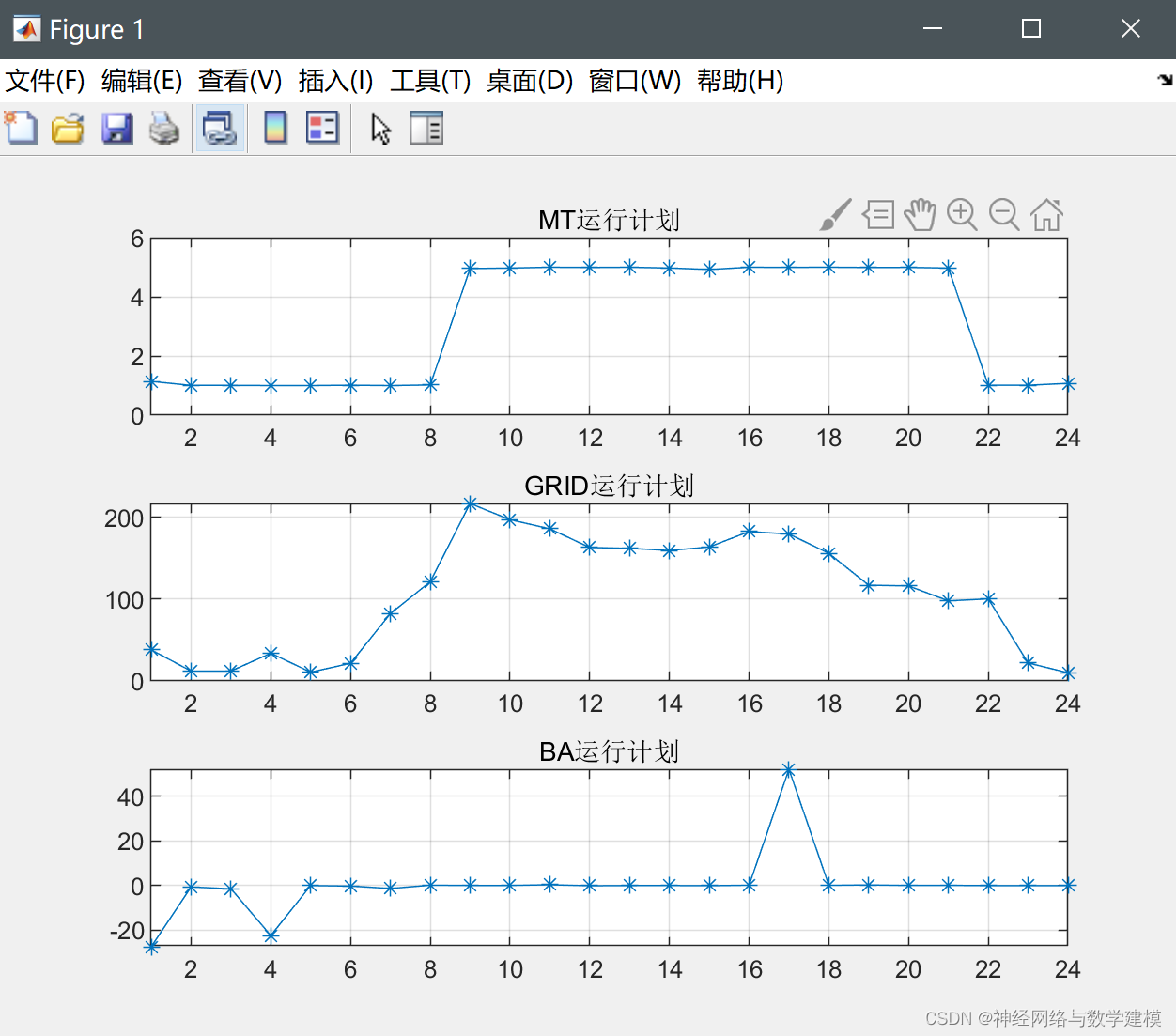
代码主要构建了含风电机组、光伏机组、燃气轮机组以及储能机组的微网日前调度模型,其中考虑了微网与上级电网的交易,采用粒子群算法给出最优调度结果,结果展示了各机组的出力水平,适合初学者学习使用代码属于精品代码。
研究背景:
随着我国工业和社会经济的快速发展,一次能源生产量与需求量逐渐上升,2020年我国全年能源消费总量已达到了49.8亿吨标准煤,相较于2019年增长了 2.2%。煤炭消费量占能源消费总量的 56.8%,核电、风电、太阳能等清洁能源消费量占能源消费总量的 24.3%。目前,我国在一次能源消费量上远远超过美国和印度,然而传统的煤炭、天然气等能源日益紧缺,逐渐影响我国社会经济的可持续发展。在此背景之下,我国提出了“碳达峰及碳中和”的能源结构转型战略需要。相比于化石能源,以风电为代表的可再生能源具有无污染、可再生的特点,大力发展风力发电技术将有效解决资源短缺和环境污染问题。但由于风电本身具有的随机性和波动性,给风电并网的调度运行带来严峻的安全问题。如何合理利用可再生能源发电、提高综合能量利用效率、降低对传统化石能源的依赖是目前重要的研究方向。
微电网(Microgrid,MG)作为一种能够灵活、高效地应用各类分布式电源,促进风电等可再生能源的利用,因此被认为是促进分布式可再生能源接入大电网的一种有效技术手段。微电网具体是一种由多种分布式能源、储能系统、能量转换设备、负荷以及相应保护系统集成的电力系统,在一定地理区域范围内进行小规模发电,减少上层电网电力传输损失并保持不间断的电力供应,具有孤岛运行和并网运行两种运行方式,也可与主电网进行单边和双边交易,拥有灵活改变运行方式的能力同时具有可调度属性。微电网不仅可以作为单一的可控子系统接入上层电网进行功率交互,而运行也可受到用户侧的控制和管理。微电网中接入储能、光伏、风电等可调度能源能有效应对恶劣天气造成的连锁停电事故,利用可再生能源减少化石燃料燃烧产生的有害污染物,提高微电网运行经济效益。对含风柴储的微电网进行的优化调度研究一方面可以满足人们对可再生能源资源高效利用的需求,另一方面可以有效降低我国电力网络对于传统化石能源的依赖性、提升电力网络运行经济性,所以此研究在我们的实际生产生活中非常有必要。
微电网模型:
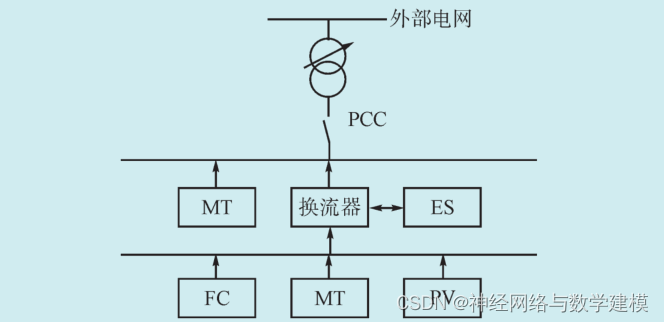
采用如图1所示的微电网系统,该系统中包含了光伏电池(Photovoltaic Cell,PV)、风机(Wind
Turbine,WT)等清洁不可控发电单元,柴油发电机(Diesel Generator,DE)、微型燃气轮机(Micro Turbine,MT) 等清洁可控发电单元以及储能单元(EnergyStorage Elements,ES)。本文微电网处于孤岛运行,由微电源对微电网内部负荷进行供电。
粒子群算法:
利用改进的惯性权重线性递减粒子群算法对微电网经济运行与优化调度问题进行求解的具体方法为:
(1)粒子群初始化,设置优化求解过程中的相关基本参数:粒子群个数N,最大迭代次数kmax,惯性权重系数ω的以及两个学习因子c1、c2等。
(2)在规定的上下限值之内生成初始粒子,配置每一个粒子的位置和速度,每一个粒子的维度表示微电网系统中微电源的个数,每一个粒子每一维度上的位置则表示该微电源在系统实际运行时的输出(或输入)功率。每一个粒子都表示为经济运行与优化调度问题的一个可行解,也就是微电网正常运行时各微源的一个出力配置方案。
(3)求出每个粒子的目标函数的值,并将这些值同自身曾经历过的最优位置进行比较,若现有粒子目标函数值比后者更优,则用现有粒子位置替代曾经历过的最优位置,将其作为该粒子个体最优值。然后将整个粒子群所有粒子的目标函数值进行比较,并将其中最优的位置同整个粒子群曾经历过的最优位置进行比较,若前者优于后者,则替代之。在第一次进行迭代时(k=0),无个体最优值和群体最优值,将本粒子所在位置设为个体最优值,将群体中的最优位置设为群体最优值。
(4)更新每个粒子的速度以及位置,生成新一代粒子和粒子群。
(5)判断当前迭代次数是否达到规定的最大次数,若未达到,则迭代次数加1(k=k+1),更新惯性权重ω的值,并进行下一次迭代;若达到了最大迭代次数,则退出循环,输出求得的最优解。
运行结果:
Matlab代码分享:
