网站制作的核心技术多梦主题建设的网站
作者:billy
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
前言
目前能下载到的最新版本是 PyCharm 2021.1。
请注意对应 Python 的版本:
- Python 2: 2.7
- Python 3: >=3.6, <=3.11
资源下载
百度网盘
提取码:wk9g
其中包含了 PyCharm 2021.1 的安装包以及2个版本的 python 安装包

安装教程
1. 安装 python-3.9.13-amd64.exe
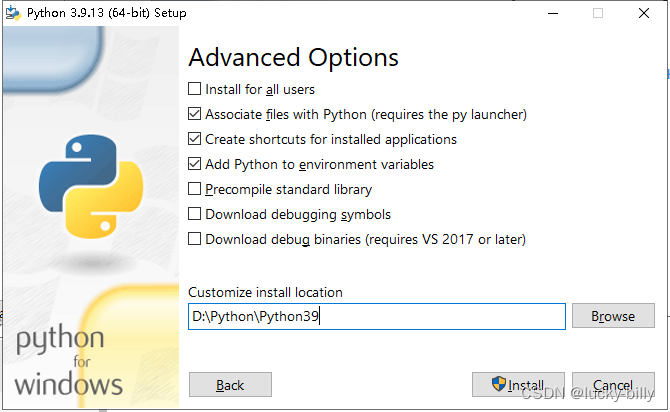
- 1)选择添加到环境变量,并选择自定义目录安装

- 2)自己选择安装目录
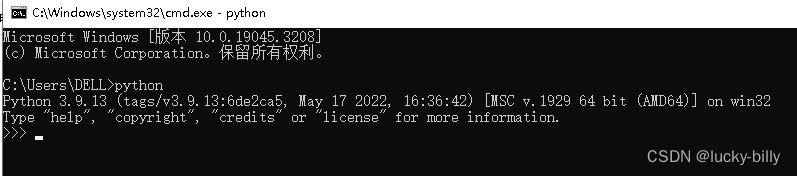
- 3)在命令行中输入 python 可以看到版本号,即为安装成功
2. 安装 PyCharm 2021.1
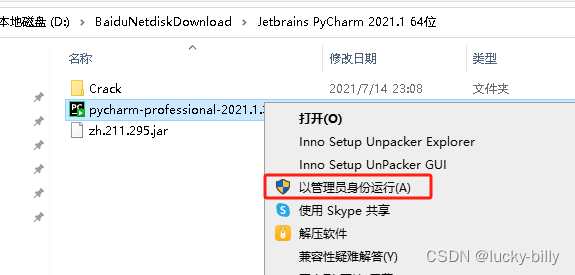
- 1)解压完成后,右键以管理员运行 pycharm-professional-2021.1.3.exe
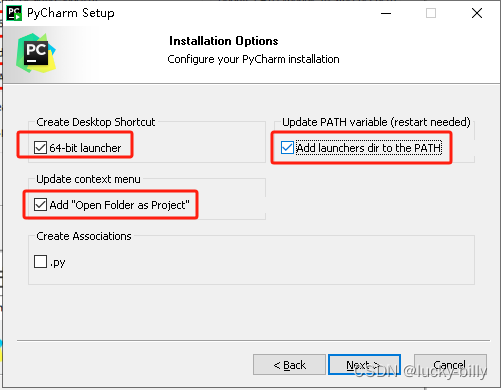
- 2)勾选3个选项
- 3)右键以管理员运行 Jetbrains PyCharm 2021.1 64位\Crack\Block Host [ Run Administrator ].cmd
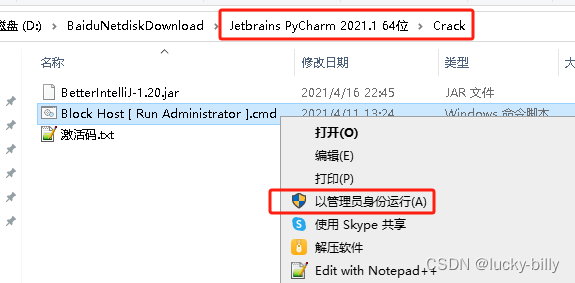
- 4)拷贝 BetterIntelliJ-1.20.jar 文件到 C 盘根目录。注意:拷贝过去之后这个文件不能删除,删除之后 PyCharm 就无法打开了
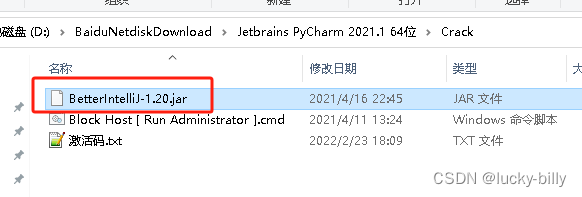
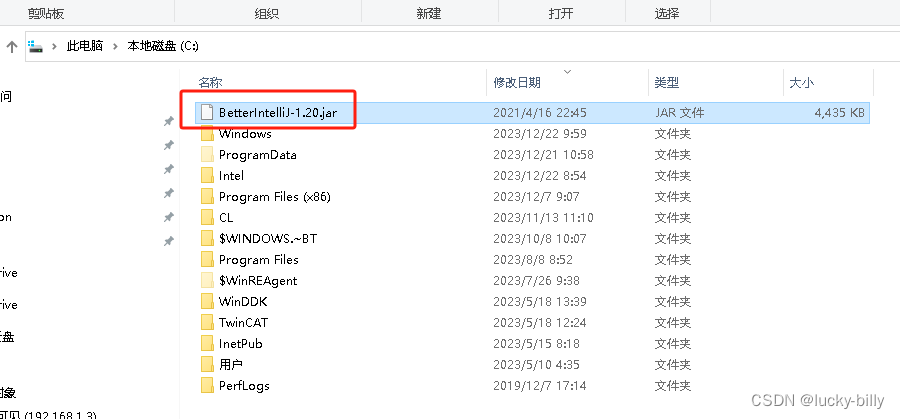
- 5)把中文包拷贝到 PyCharm 的安装目录下的 lib 文件夹中
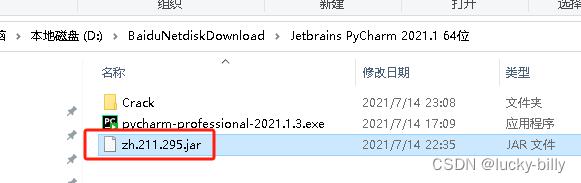
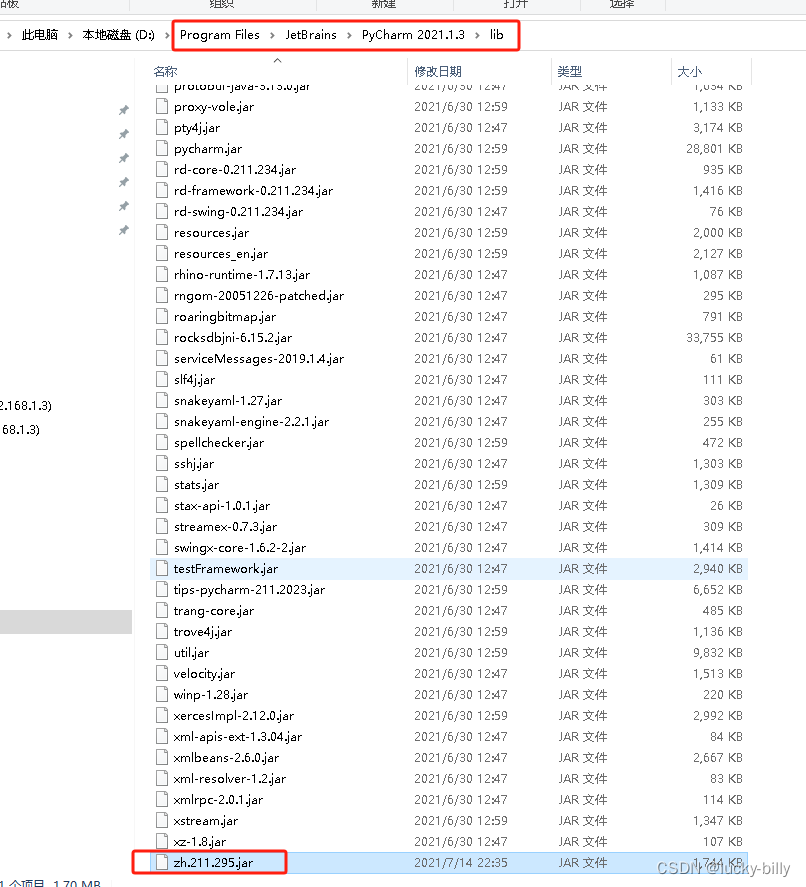
- 6)打开桌面上的 PyCharm 软件,开始配置。注意:操作有点多,请耐心一步步跟着做
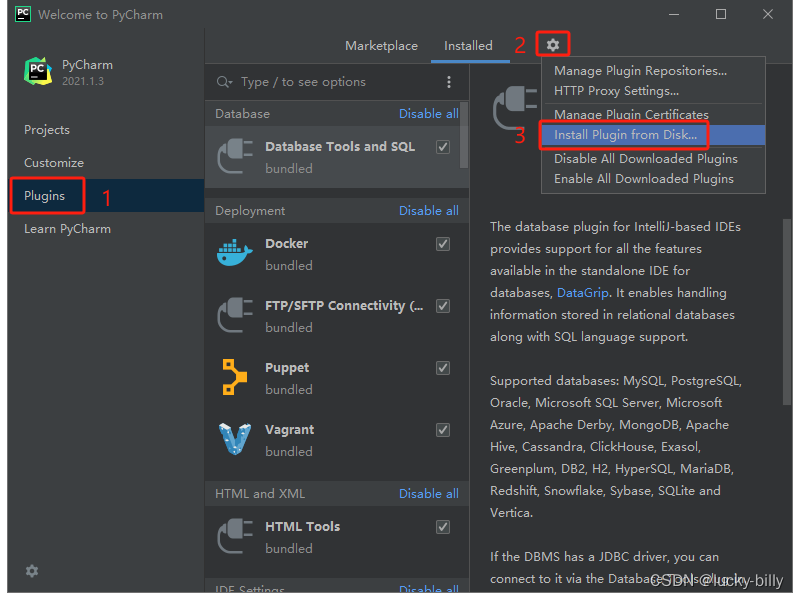
选择安装插件
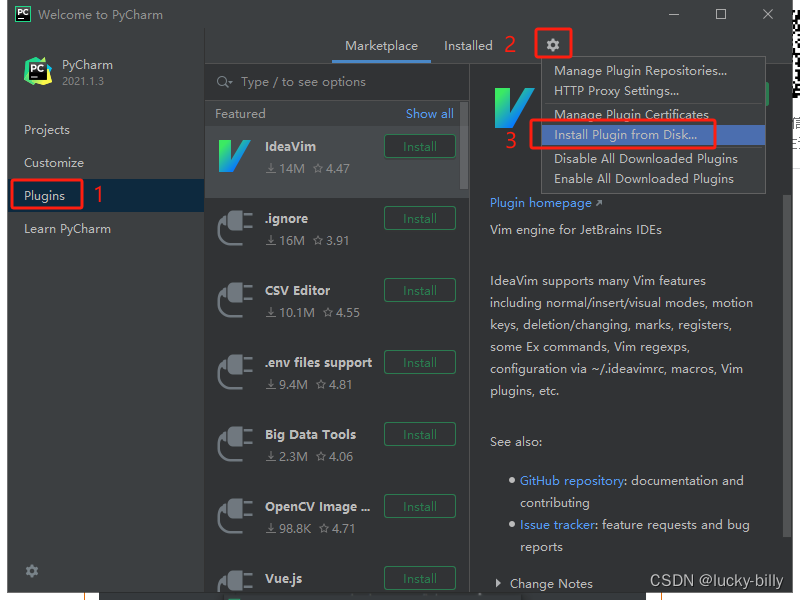
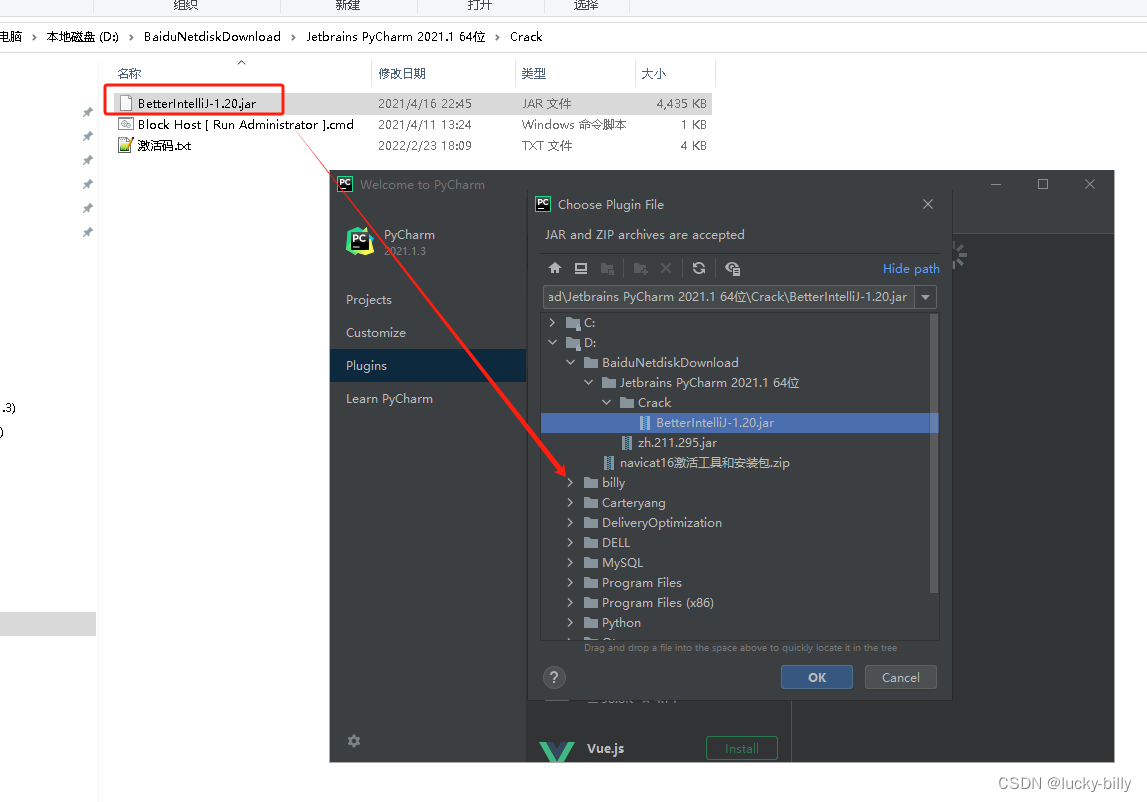
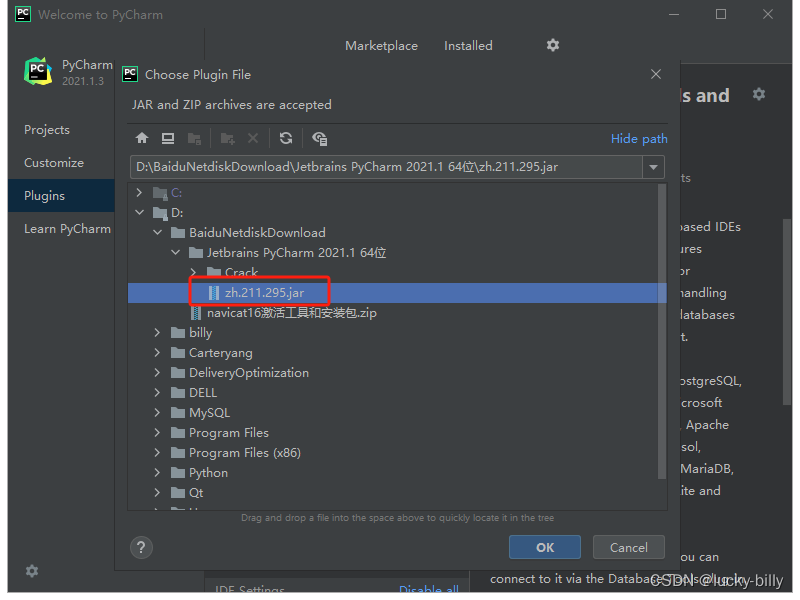
选择 BetterIntelliJ-1.20.jar 的路径,或者直接把文件拖拽到软件界面中,会自动显示路径。点击 OK 确认
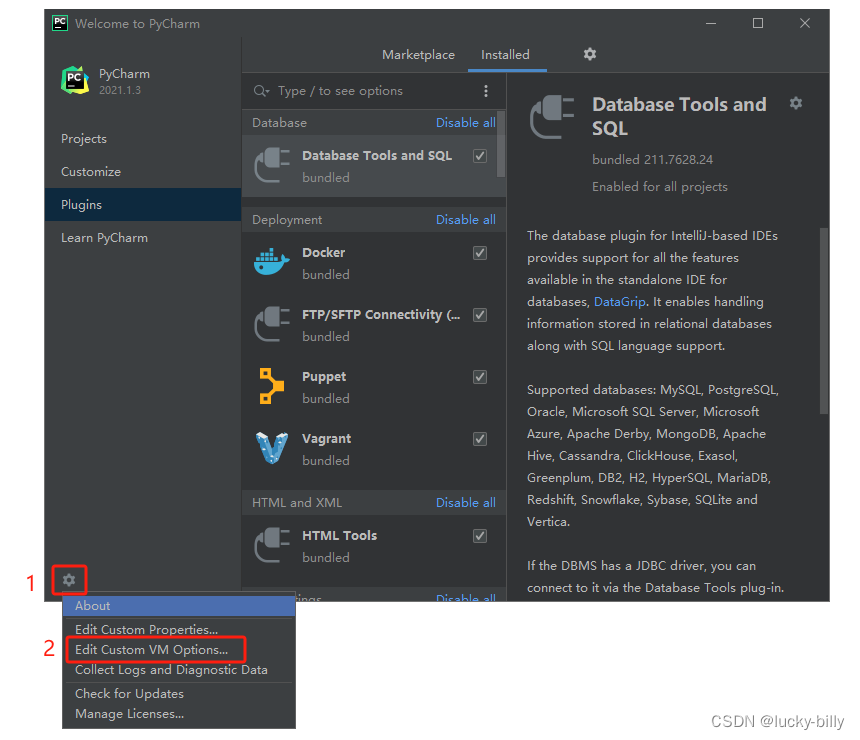
点击左下角的设置按钮,选择 Edit Custom VM Options…
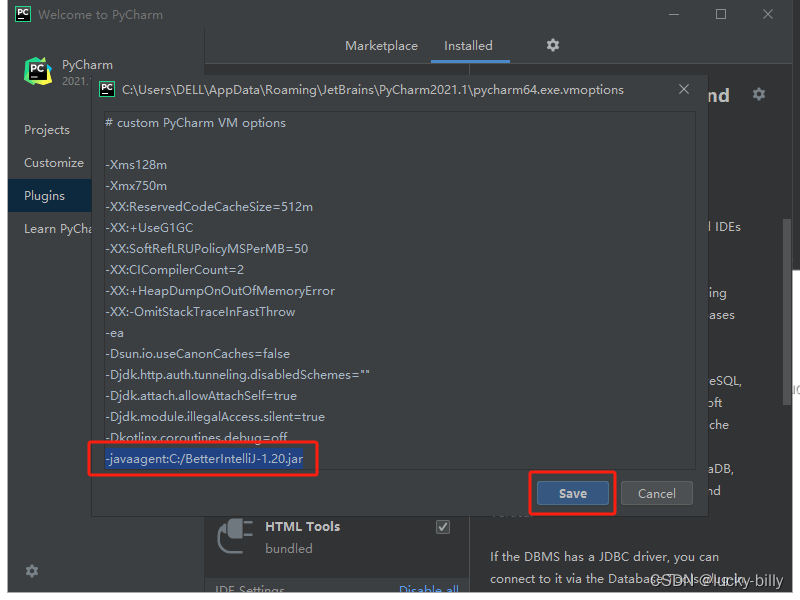
输入 -javaagent:C:/BetterIntelliJ-1.20.jar 然后保存
再来一次安装插件,这次选择中文包
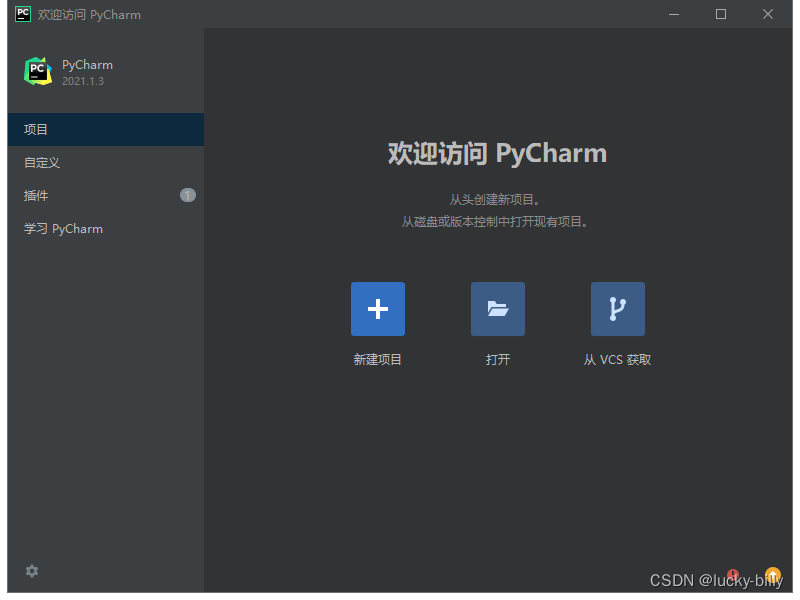
关闭 PyCharm 软件,重新打开会变成中文界面
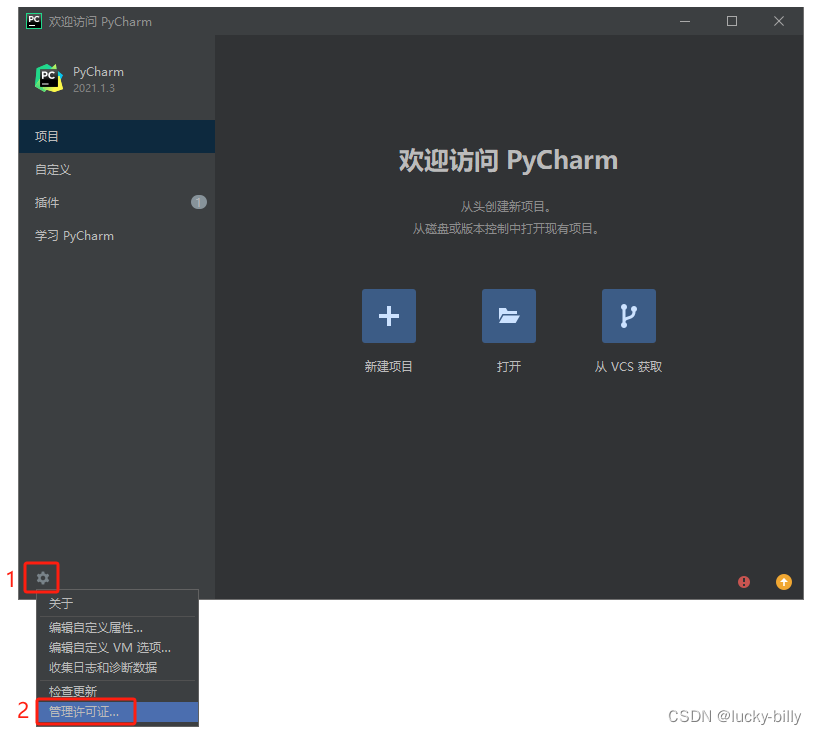
点击左下角设置,选择管理许可证
选择添加新许可证
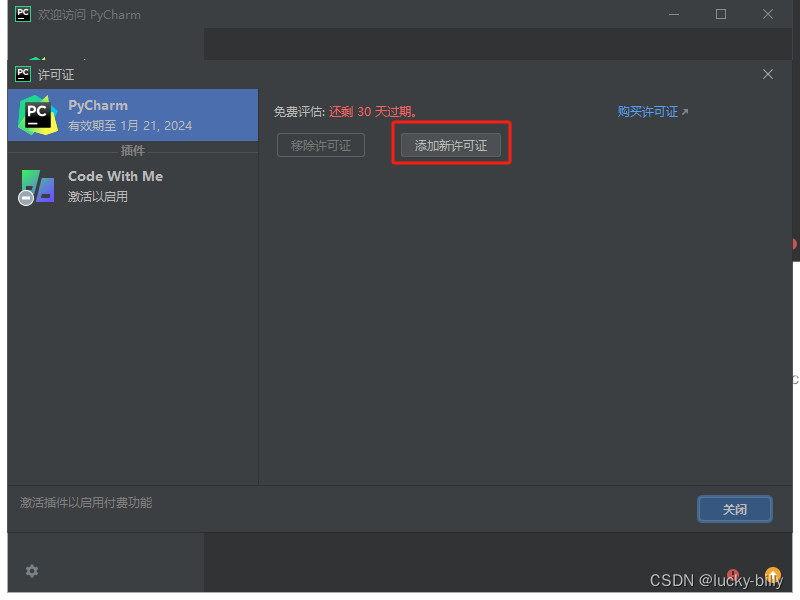
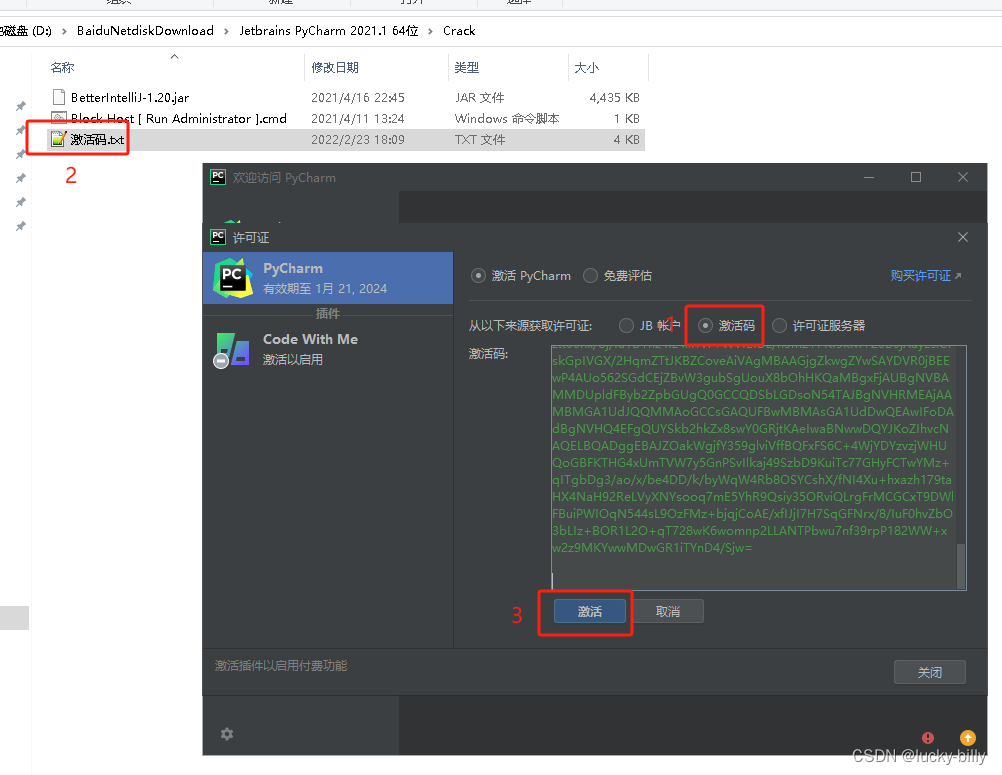
选择激活码,把激活码拖拽或复制过来,选择激活
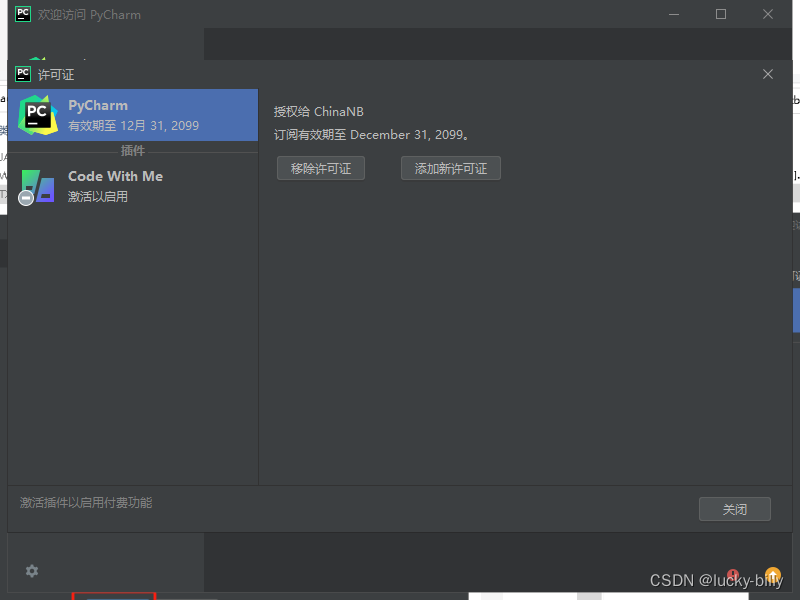
至此大功告成 !!!
更多请参考
- Python 进阶之路