陵水网站建设介绍苏州网站开发外包公司
检查器(Hierarchy)面板中的所有东西都是组件。日后多数工作都是和组件打交道,包括调参、自定义脚本组件。
文章目录
- 12 游戏的灵魂,脚本组件
- 13 玩转脚本组件
- 14 尽职的一生,了解组件的生命周期
- 15 不能插队!脚本的执行顺序问题
- 16 别搞错了,给游戏物体做个标记
12 游戏的灵魂,脚本组件
所有物体都能看成是一个空物体+组件
每一个物体都是一个空物体,之所以会表现出不同的形式是因为它的不同的组件
添加自定义组件方法:创建->拖拽
13 玩转脚本组件
空物体的成长历程
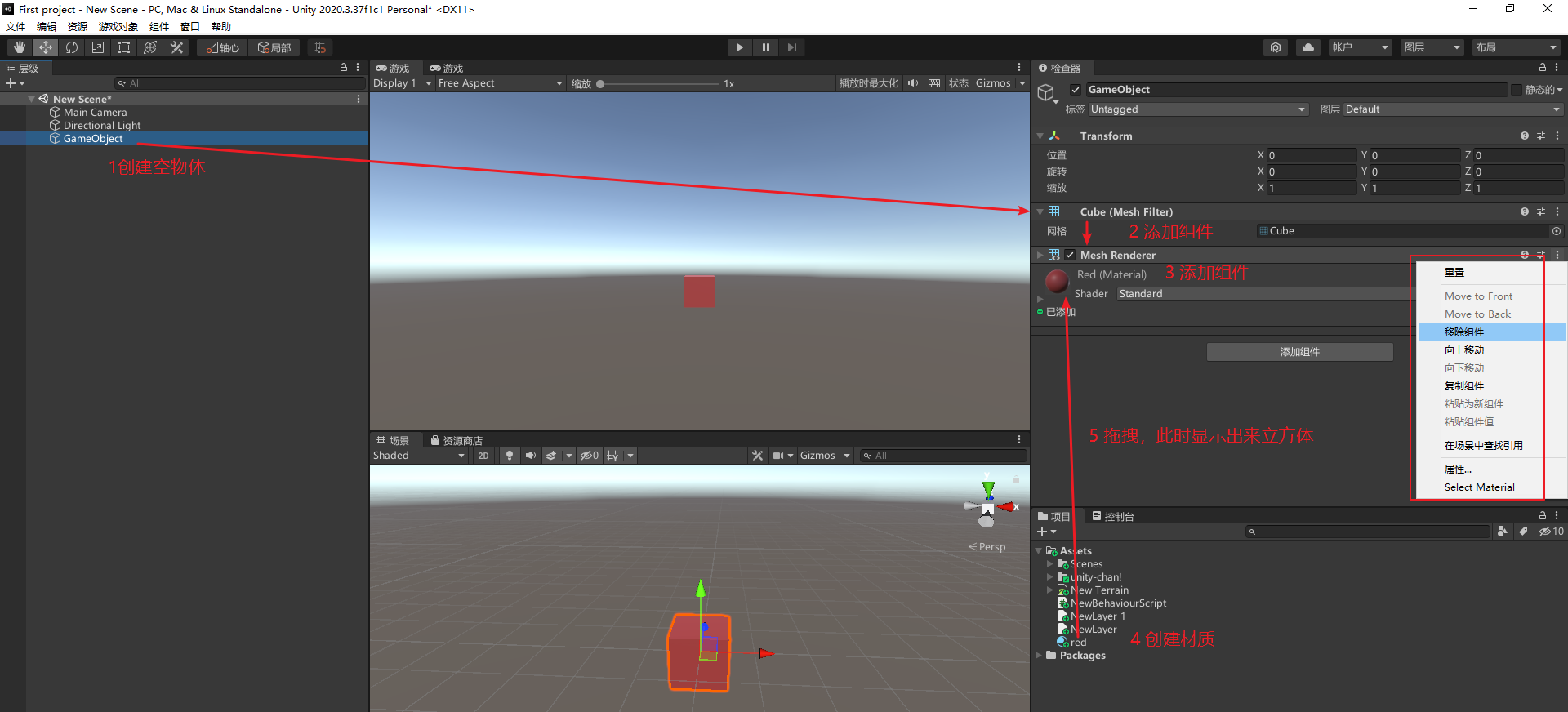
组件右侧的白色框框的选项是一些对组件的操作,包括移动、复制和粘贴组件、粘贴组件属性值等
14 尽职的一生,了解组件的生命周期
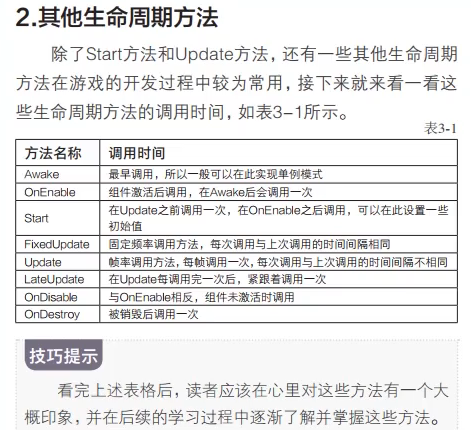
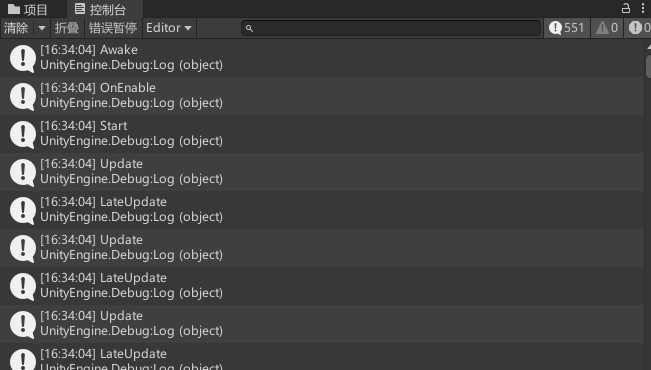
- awake
- onenable组件激活(启动)(可多次)
- start 第一次 onenable调用之后
- update每一帧
- lastupdata每一帧之后
- fix固定时间可在设置中修改
- ondisahle 物体状态变成非激活时候执行其中代码
- ondestroy 移除组件时候调用
using System.Collections;
using System.Collections.Generic;
using UnityEngine;public class test : MonoBehaviour
{
void Awake()
{
Debug.Log("Awake");
}
void OnEnable()
{
Debug.Log("OnEnable");
}
// Start is called before the first frame update
void Start()
{
Debug.Log("Start");
}// Update is called once per frame
void Update()
{
Debug.Log("Update");
}void LateUpdate()
{
Debug.Log("LateUpdate");
}//void FixedUpdate()
//{
// Debug.Log("FixedUpdate")
//}void OnDisable()
{
Debug.Log("OnDisable");
}void OnDestroy()
{
Debug.Log("OnDestroy");
}
}
15 不能插队!脚本的执行顺序问题
多个脚本时候的执行顺序:
先执行所有脚本的Awake方法,在执行所有脚本的Start方法。
控制脚本执行顺序的两个方法
- 利用生命周期函数
- 脚本1的代码写在Awake(要求脚本1中的先执行)
- 脚本2的代码写在OnEnable
- 使用编辑器的项目设置(设置执行顺序)
- 第一种方式打开
- 第二种打开方式
- 第一种方式打开

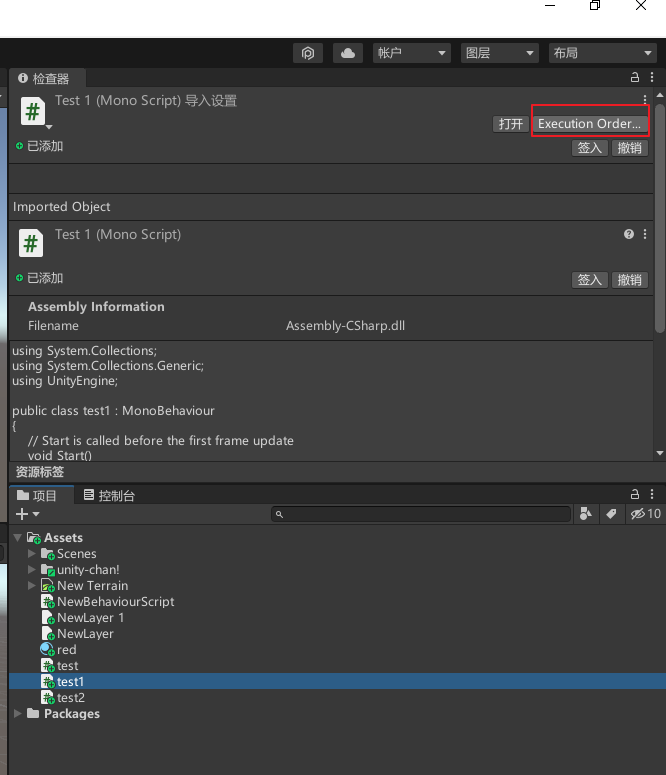
注意要把框架最底层的东西放在上边,这样我们的才有效。
初始化的东西放在Awake里边。不要放在OnEnable,否则容易多次运行,丢失信息。
16 别搞错了,给游戏物体做个标记
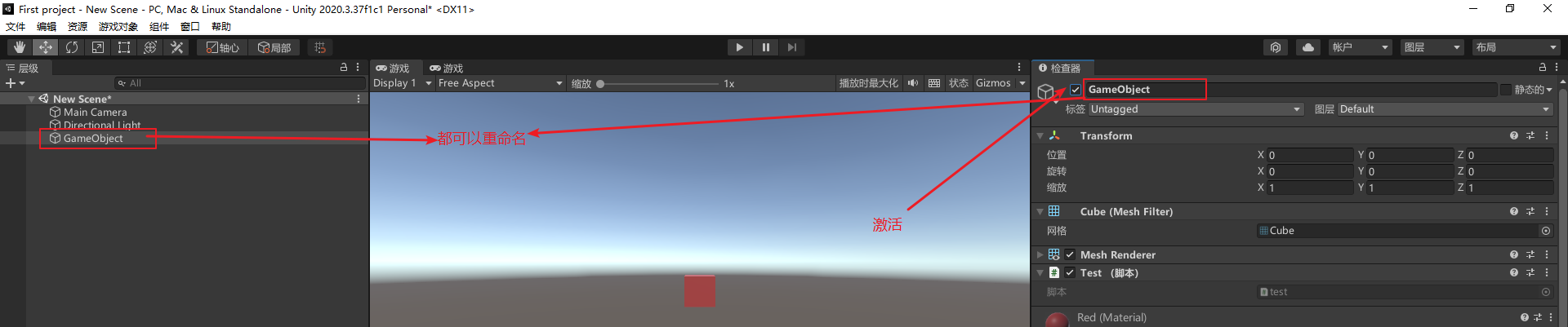
【标签】的作用
作用1:在脚本中通过标签能找到物体(游戏对象)
作用2:判断物体是不是我想要的物体
注意标签是可以重复的:多个物体可以对应同一个标签。比如多个妖怪都是妖怪
【图层】
碰撞检测、相机拍摄 会涉及到
图层是控制一批游戏物体的,比如游戏中的角色。图层的个数只有32个,最好从系统给定之下添加图层。
相机的剔除遮罩就是利用了图层,决定拍哪、不拍哪些图层。
真实场景中可利用图层来制作小地图。