网站推广需要域名迁移网站建设设计师
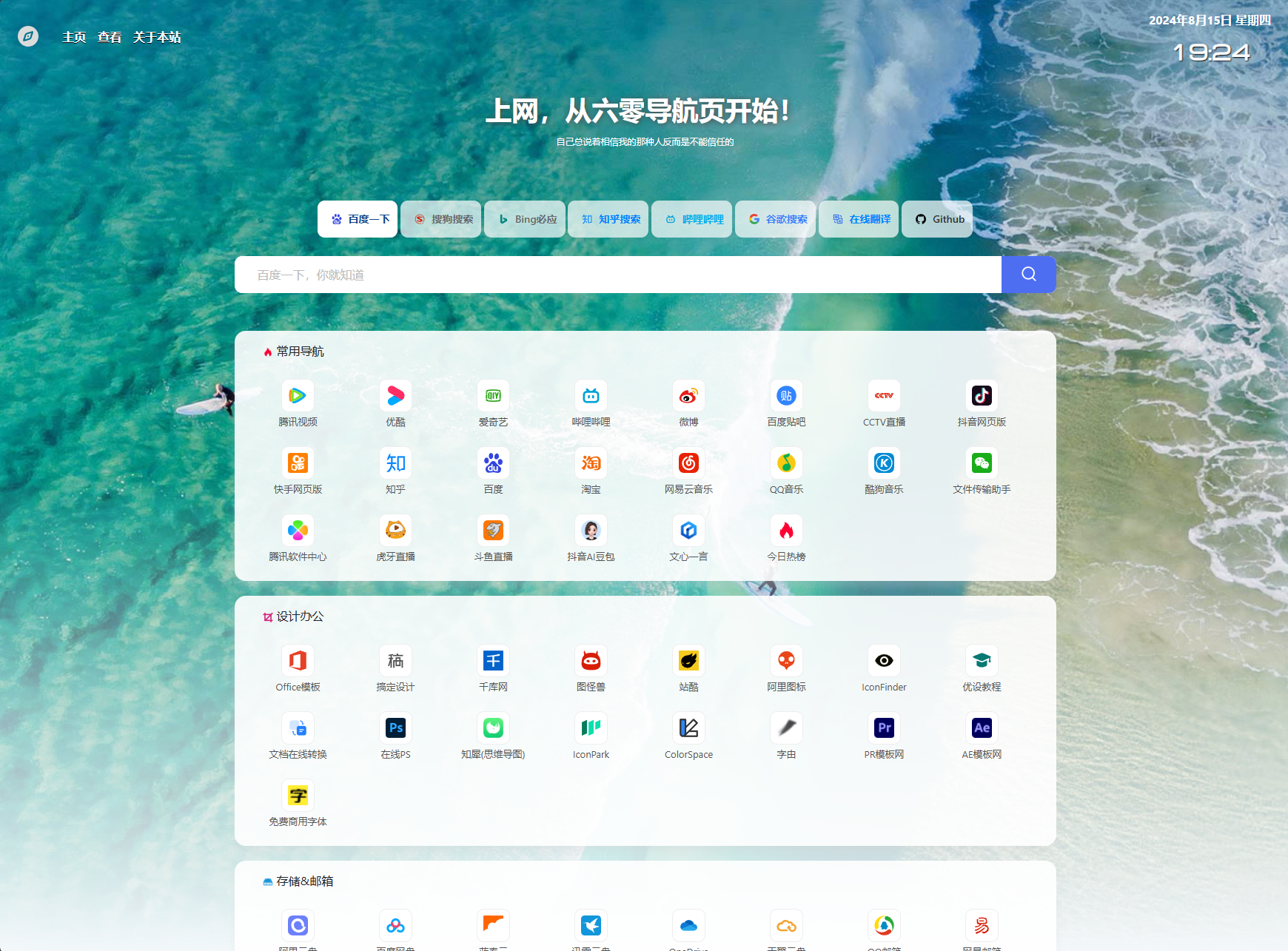
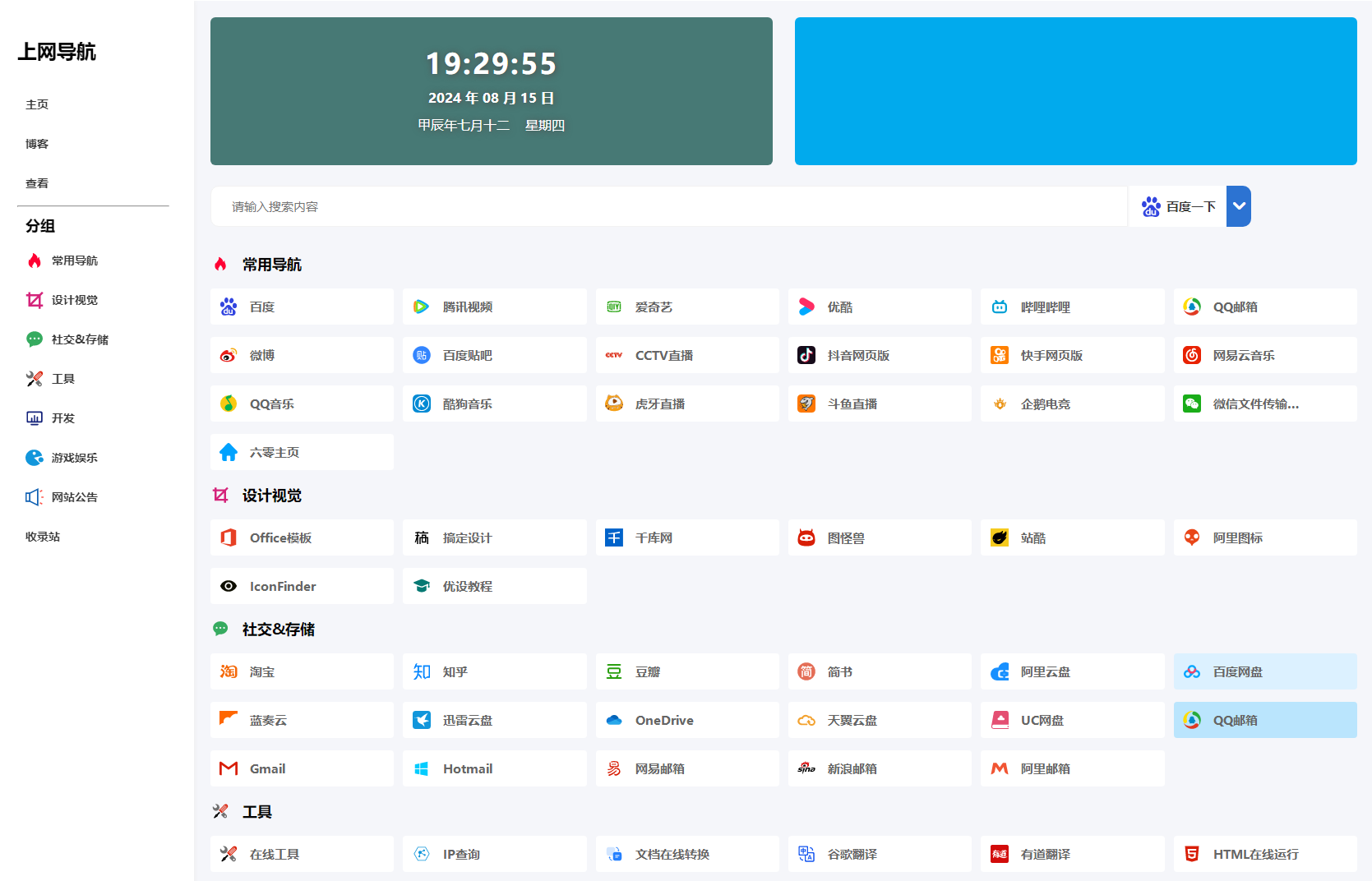
六零导航页 (LyLme Spage) 致力于简洁高效无广告的上网导航和搜索入口,支持后台添加链接、自定义搜索引擎,沉淀最具价值链接,全站无商业推广,简约而不简单。
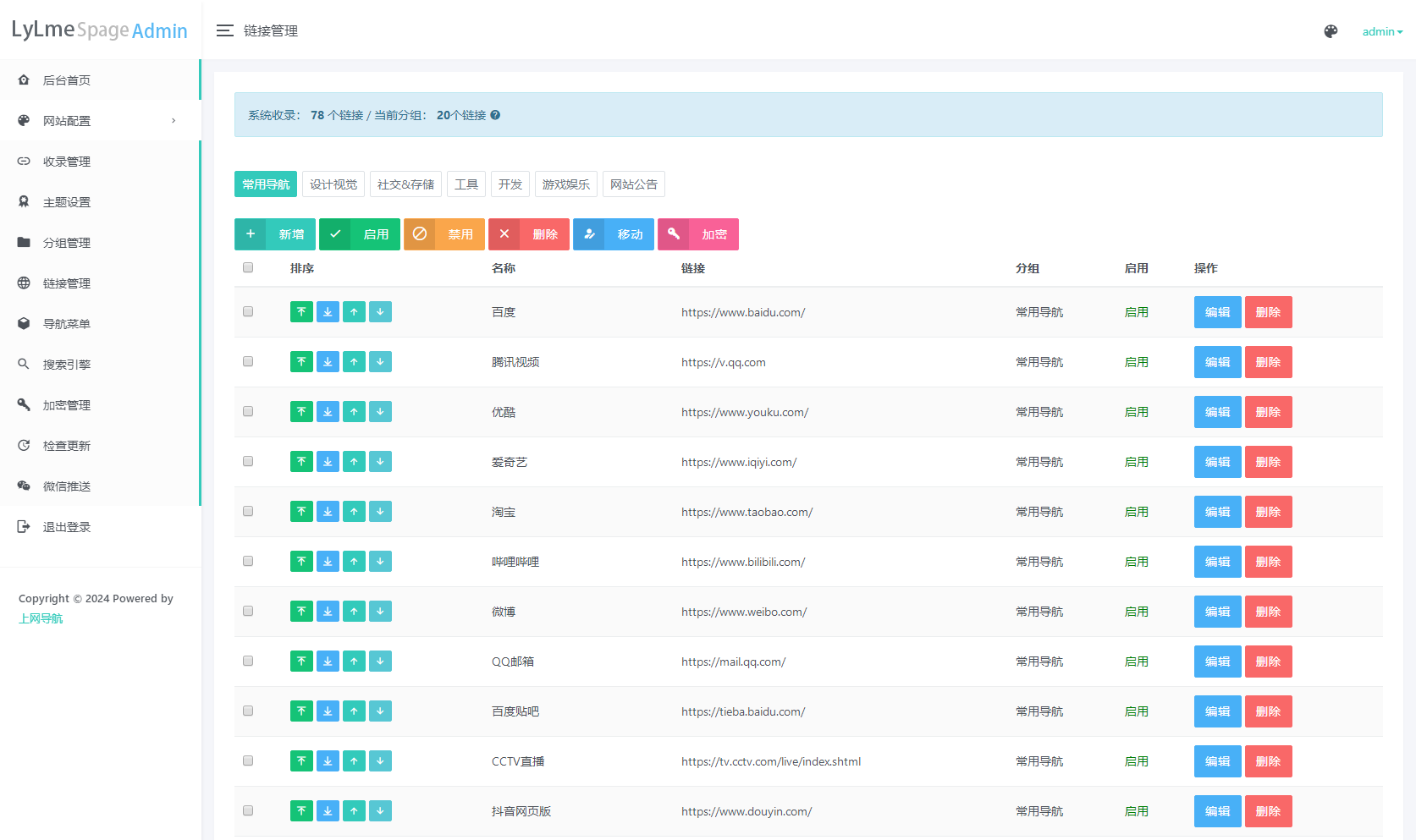
使用PHP+MySql,增加后台管理
多模板选择,支持在后台切换模板
增加常用搜索引擎,如:知乎、哔哩哔哩、在线翻译等(支持自定义)
支持用户提交收录申请,地址:http://域名/apply
部分模板优化和增加部分功能,如返回顶部、获取输入框焦点、时间日期显示等
安装教程:
上传到网站根目录解压
访问http://域名/install
按提示配置数据库进行安装
后台地址:http://域名/admin
账号密码:admin/123456
最新UI六零导航系统源码 | 多模版全开源