企业网站开发课程jsp做的网站
目录
第一部分、按键抖动现象
第二部分、消抖思路及代码
1、简单的按键消抖思路
2、实际按键消抖思路
3、实际按键消抖模块代码
第三部分、总结
第一部分、按键抖动现象
只要学习过单片机的都会知道,按键在按下去和松开的那个瞬间都存在抖动,在单片机消除抖动最简单的方式就是延时。
在FPGA的开发过程中,按键也不是理想状态。所以在按下按键和松开按键的瞬间都是存在机械抖动的。
这种抖动可分为前抖动(按下瞬间带来的抖动),后抖动(松开瞬间带来的抖动),如下图所示。
无论是前抖动还是后抖动,持续时间大约是5~10ms。

第二部分、消抖思路及代码
1、简单的按键消抖思路
如下图为最简单的按键检测思路。这种思路,在不考虑按键存在抖动的情况下,用寄存器打拍的方式(pipeline),将key延时一个时钟周期,变为key_old。
接着再通过检测key与key_old之间的信号差,来判断按键是否按下。
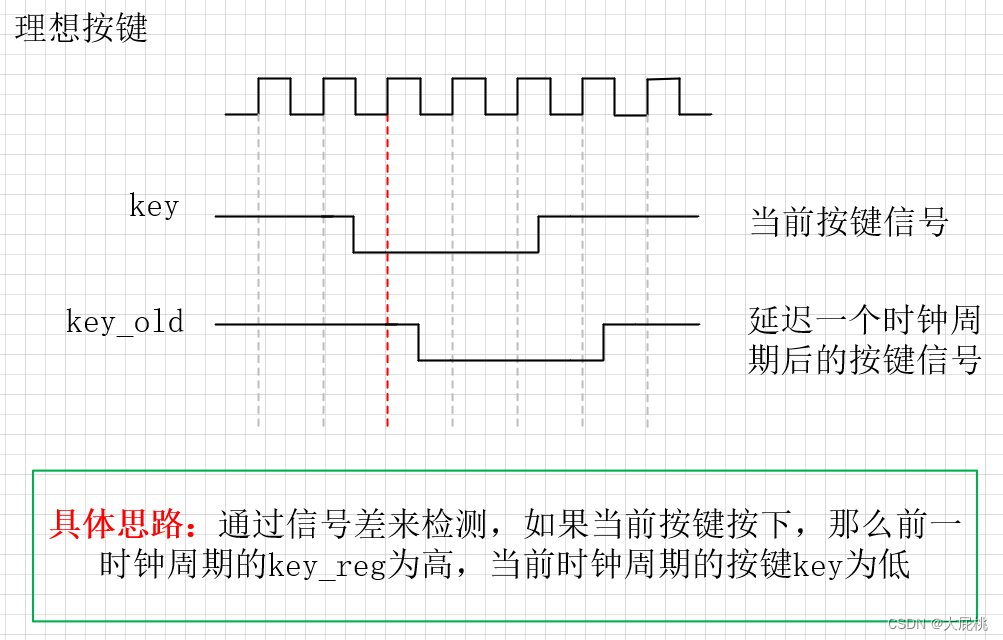
实现代码如下:
// -----------------------------------------------------------------------------
// Copyright (c) 2014-2023 All rights reserved
// -----------------------------------------------------------------------------
// Author : BigFartPeach
// CSDN : 大屁桃
// E-mail : 2624507313@qq.com
// File : key_shift_led.v
// Create : 2023-04-14 13:58:37
// -----------------------------------------------------------------------------
module key_shift_led(input wire clk,input wire rst_n,input wire key1,output wire [3:0]led);
//寄存器打拍,延迟key一个时钟周期
reg key_old;
//led流水状态寄存器
reg [3:0]led_shift = 4'b0001;//获取key_old信号
always @(posedge clk or negedge rst_n) beginif (rst_n == 1'b0) beginkey_old <= 1'b1;endelse beginkey_old <= key1;end
end
//理想按键按下检测方式
always @(posedge clk or negedge rst_n) beginif (rst_n == 1'b0) beginled_shift <= 4'b0001;endelse if (key1 == 1'b0 && key_old == 1'b1) beginled_shift <= {led_shift[2:0],led_shift[3]};end
end
//led状态赋值
assign led = led_shift;endmodule这种简单的消抖方式存在以下问题:
有的时候,按下按键,会看到LED灯一次性跳过两个,或者三个,没有实现按一下,跳一下的功能。
2、实际按键消抖思路
在消除抖动之后,如果检测到按键按下(低电平持续了5ms),那么就输出一个周期的单脉冲标志,来表示按键按下。
这么做的原因:人在正常按下按键,松开按键,按键稳定的时间一般是大于五毫秒的。
cnt_5ms:这个计数器在clk下计数,清零方式为key == 1,cnt_5ms == 5ms计数值
stable_flag:保证press_flag有且仅有一个时钟周期的高电平。cnt_5ms这个计数器在,key == 0,cnt_5ms == 5ms计数值的时候翻转,清零为key == 1
如果不这样搞得话,那么stable_flag在稳定时间里面就会有多个高脉冲。
press_flag:在cnt_5ms == 5ms计数值,stable_flag == 0的时候翻转。这样才是一个周期的单脉冲。
实际按键检测的时序图如下图所示:

3、实际按键消抖模块代码
// -----------------------------------------------------------------------------
// Copyright (c) 2014-2023 All rights reserved
// -----------------------------------------------------------------------------
// Author : BigFartPeach
// CSDN : 大屁桃
// E-mail : 2624507313@qq.com
// File : key_shift_led_elim.v
// Create : 2023-04-14 12:38:11
// -----------------------------------------------------------------------------
module key_shift_led_elim(input wire clk,input wire rst_n,input wire key1,output wire [3:0]led);
//变量
reg [17:0]cnt_5ms;//0~249,999表示5ms时间到了
reg stable_flag;
reg press_flag;
//保存led流水状态的寄存器
reg [3:0]shift_led = 4'b0001;//cnt_5ms毫秒计数器
always @(posedge clk or negedge rst_n) beginif (rst_n == 1'b0) begincnt_5ms <= 1'b0;endelse if(cnt_5ms == 'd249_999)begincnt_5ms <= 1'b0;endelse if (key1 == 1'b0) begincnt_5ms <= cnt_5ms + 1'b1;endelse begincnt_5ms <= 1'b0;end
end
//stable_flag在key == 0稳定到5ms后,一直拉高
always @(posedge clk or negedge rst_n) beginif (rst_n == 1'b0) beginstable_flag <= 1'b0;endelse if (key1 == 1'b0 && cnt_5ms == 'd249_999) beginstable_flag <= 1'b1;endelse if(key1 == 1'b1)beginstable_flag <= 1'b0;end
end
//press_flag按下的一个周期的脉冲
always @(posedge clk or negedge rst_n) beginif (rst_n == 1'b0) beginpress_flag <= 1'b0;endelse if (stable_flag == 1'b0 && cnt_5ms == 'd249_999) beginpress_flag <= 1'b1;endelse beginpress_flag <= 1'b0;end
end
//按下按键shift_led移位
always @(posedge clk or negedge rst_n) beginif (rst_n == 1'b0) beginshift_led <= 4'b0001; endelse if (press_flag == 1'b1) beginshift_led <= {shift_led[2:0],shift_led[3]};//位置调换end
end
//led状态流水
assign led = shift_led;endmodule第三部分、总结
这篇博客介绍了FPGA检测按键消抖的两种方式,通过检测按键来控制LED的移动。最简单的检测方式带来的问题就是偶尔会出现不灵敏的现象;实际的消抖方式能很好解决按键抖动的问题。
最后希望我的博客对你有帮助,有需要的小伙伴可以查看本专栏更多的往期文章👾👾👾
FPGA的学习之旅_大屁桃的博客-CSDN博客