php网站开发的发展前景网站建设的相关资料
目录
- overleaf写作问题记录
- 1.Latex中的%问题(文本变成灰色)
- 2.Springer文献格式问题
- 2.1 新建reference.bib
- 2.2 谷歌学术搜索文章并引用
- 2.3 复制BibTex
- 2.4 复制进reference.bib
- 2.5 在sn-article.tex的\end{document}前添加语句
- 2.6 引用文献
- 2.7 Springer模板参考文献注意事项
- 2.7.1 引入包
- 2.7.2 找到sn-jnl.cls文件,找到如下语句并修改
- 2.7.3 找到sn-basic.bst文件1708-1761行(两个大写的SORT之间)进行修改:
- 2.7.4 更改[1]为1.
- 2.7.5 编译结果
overleaf写作问题记录
1.Latex中的%问题(文本变成灰色)

使用 : $\%$ 转义%
比如: 2.5$\%$ 1.1$\%$
2.Springer文献格式问题
2.1 新建reference.bib
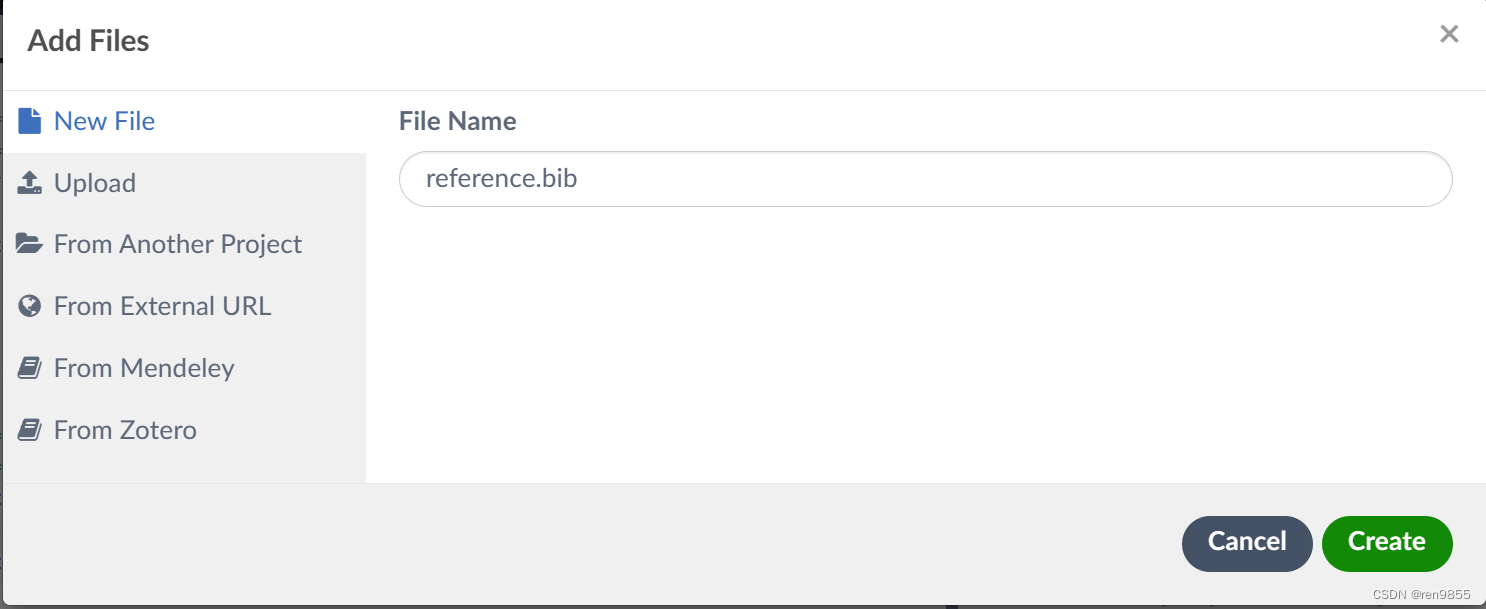
2.2 谷歌学术搜索文章并引用
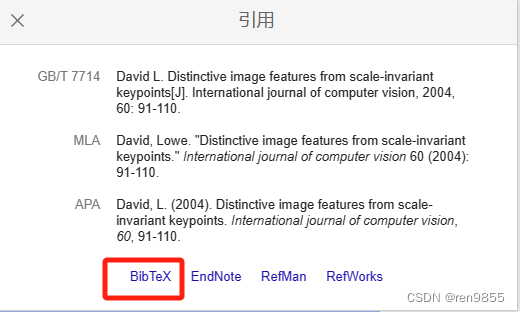
2.3 复制BibTex

2.4 复制进reference.bib
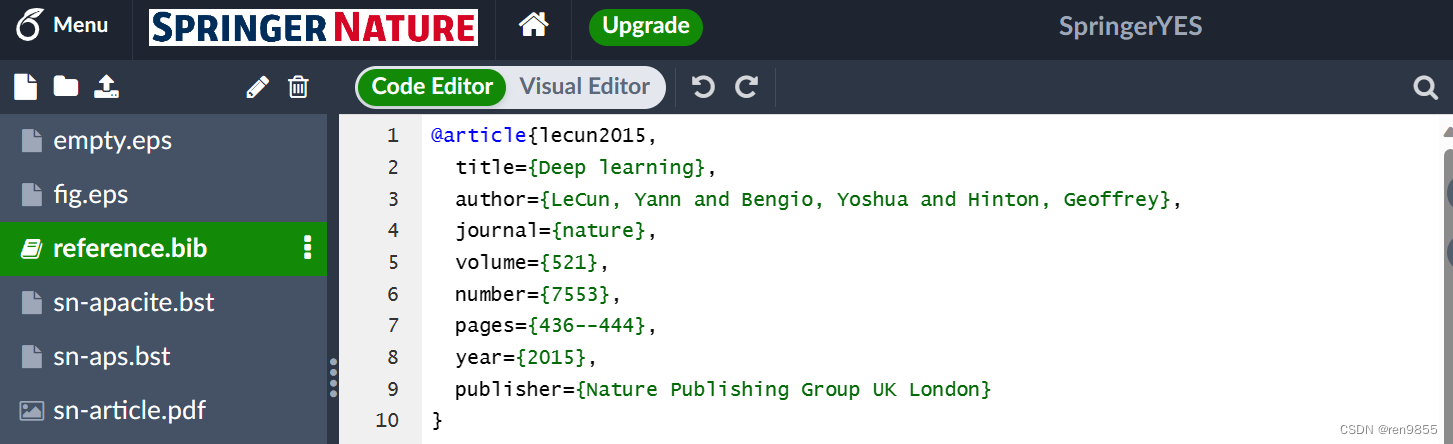
2.5 在sn-article.tex的\end{document}前添加语句
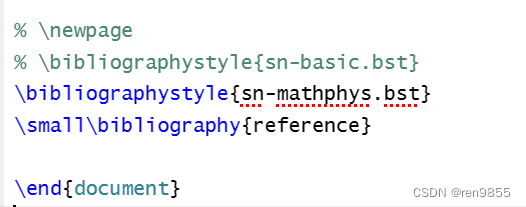
\bibliographystyle{sn-mathphys.bst}
\small\bibliography{reference}
2.6 引用文献
使用\cite{文献名字}

2.7 Springer模板参考文献注意事项

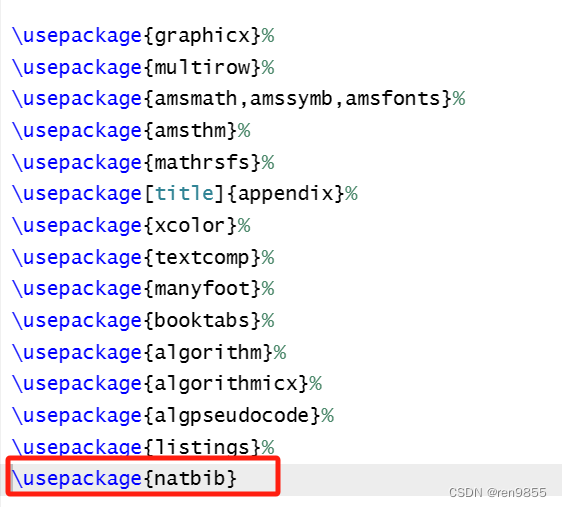
2.7.1 引入包
\usepackage{natbib}
2.7.2 找到sn-jnl.cls文件,找到如下语句并修改
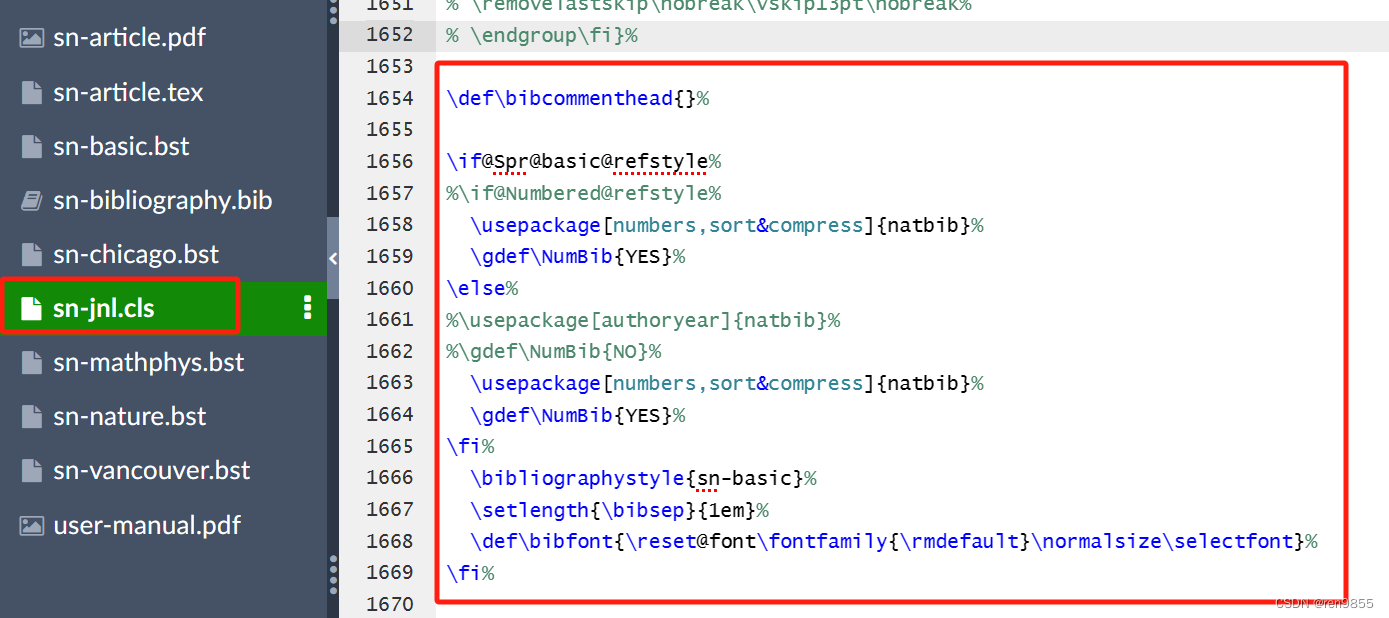
\if@Spr@basic@refstyle%
%\if@Numbered@refstyle%\usepackage[numbers,sort&compress]{natbib}%\gdef\NumBib{YES}%
\else%
%\usepackage[authoryear]{natbib}%
%\gdef\NumBib{NO}%\usepackage[numbers,sort&compress]{natbib}%\gdef\NumBib{YES}%
\fi%\bibliographystyle{sn-basic}%\setlength{\bibsep}{1em}%\def\bibfont{\reset@font\fontfamily{\rmdefault}\normalsize\selectfont}%
\fi%
2.7.3 找到sn-basic.bst文件1708-1761行(两个大写的SORT之间)进行修改:
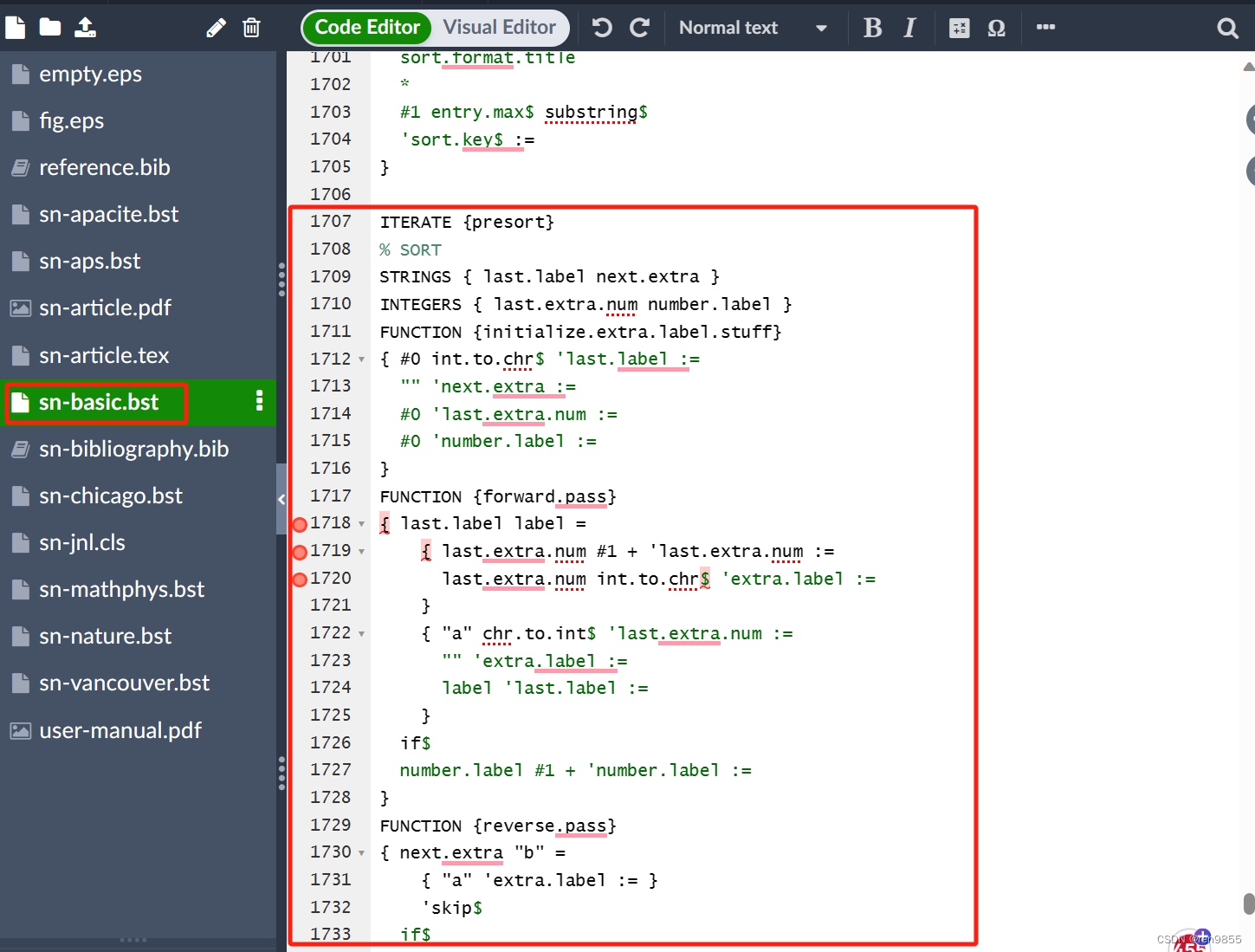
% SORT 注释掉
STRINGS { last.label next.extra }
INTEGERS { last.extra.num number.label }
FUNCTION {initialize.extra.label.stuff}
{ #0 int.to.chr$ 'last.label :="" 'next.extra :=#0 'last.extra.num :=#0 'number.label :=
}
FUNCTION {forward.pass}
{ last.label label ={ last.extra.num #1 + 'last.extra.num :=last.extra.num int.to.chr$ 'extra.label :=}{ "a" chr.to.int$ 'last.extra.num :="" 'extra.label :=label 'last.label :=}if$number.label #1 + 'number.label :=
}
FUNCTION {reverse.pass}
{ next.extra "b" ={ "a" 'extra.label := }'skip$if$extra.label 'next.extra :=extra.labelduplicate$ empty$'skip${ "{\natexlab{" swap$ * "}}" * }if$'extra.label :=label extra.label * 'label :=
}
EXECUTE {initialize.extra.label.stuff}
ITERATE {forward.pass}
REVERSE {reverse.pass}
FUNCTION {bib.sort.order}
{ sort.label" "*year field.or.null sortify*" "*title field.or.nullsort.format.title*#1 entry.max$ substring$'sort.key$ :=
}
ITERATE {bib.sort.order}
% SORT 注释掉
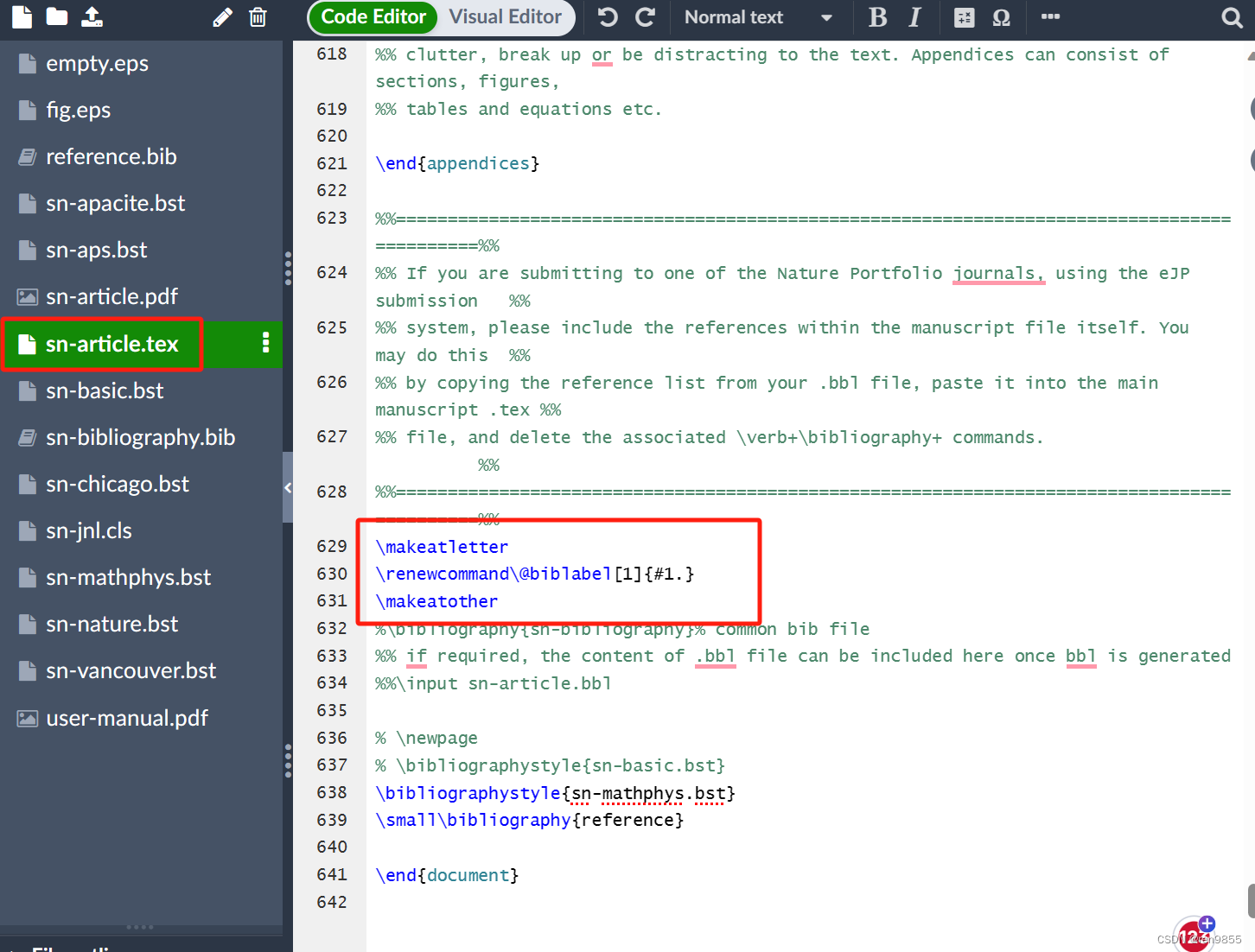
2.7.4 更改[1]为1.
在sn-article.tex末尾添加语句
\makeatletter
\renewcommand\@biblabel[1]{#1.}
\makeatother
2.7.5 编译结果

