找外国男人做老公网站zt16j门户网
postgresql 数据库 主从切换 测试
文章目录
- postgresql 数据库 主从切换 测试
- 前言
- 环境:
- 主从切换
- 1. 查看数据库状态:
- 2. 备库切换主库
- 3. 旧主库切换成备库;
- 4 查看状态
- 后记
前言
因数据库等保需要,需要对老系统的数据库进行主从切换来确保数据库的稳定性与安全性。
环境:
数据库版本:postgresql 11.5
pg数据库主从部署:
pg11.5主从部署:
https://blog.csdn.net/yang_z_1/article/details/112259081
主从切换
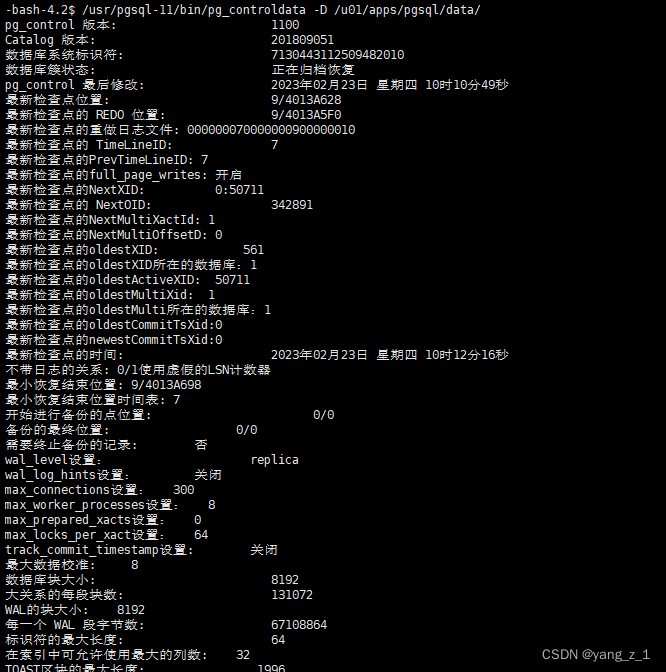
1. 查看数据库状态:
1.1 查看数据库状态
/usr/pgsql-11/bin/pg_controldata -D /u01/apps/pgsql/data/
主库:
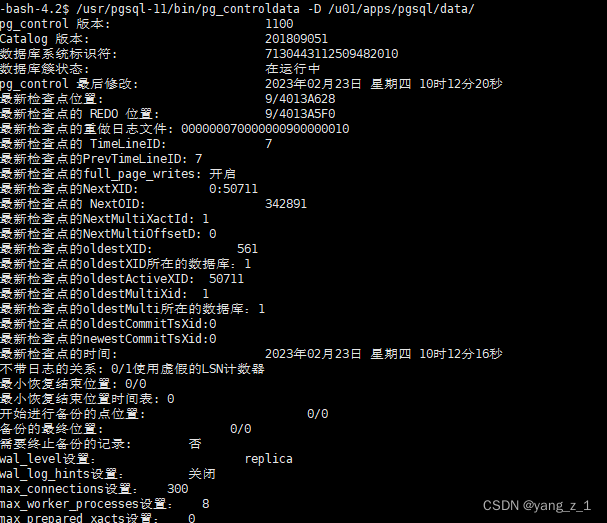
从库:
1.2 查看数据库主从
select pg_is_in_recovery();
t : t标示备库
F : f标识主库

在主库中查询:
select * FROM pg_stat_replication ;

2. 备库切换主库
2.1 停止主库
/usr/pgsql-11/bin/pg_ctl -D /u01/apps/pgsql/data/ stop
systemctl stop postgresql-11
-bash-4.2$ /usr/pgsql-11/bin/pg_ctl -D /u01/apps/pgsql/data/ stop
等待服务器进程关闭 .... 完成
服务器进程已经关闭
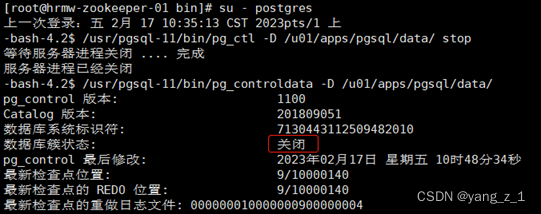
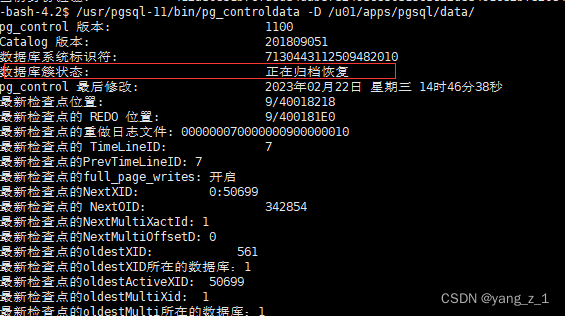
2.2 查看备库状态
查看备库状态:
一定要备库是在正在归档恢复中
2.3 修改备库参数
进入数据库目录下 ,修改recovery.conf 文件
mv recovery.conf recovery.done
[root@localhost data]# mv recovery.conf recovery.done
修改前:
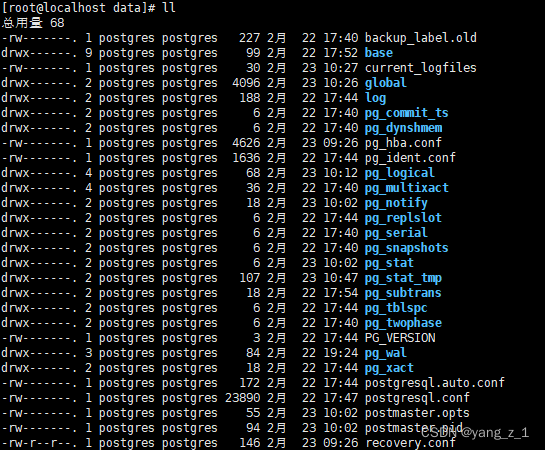
修改后:
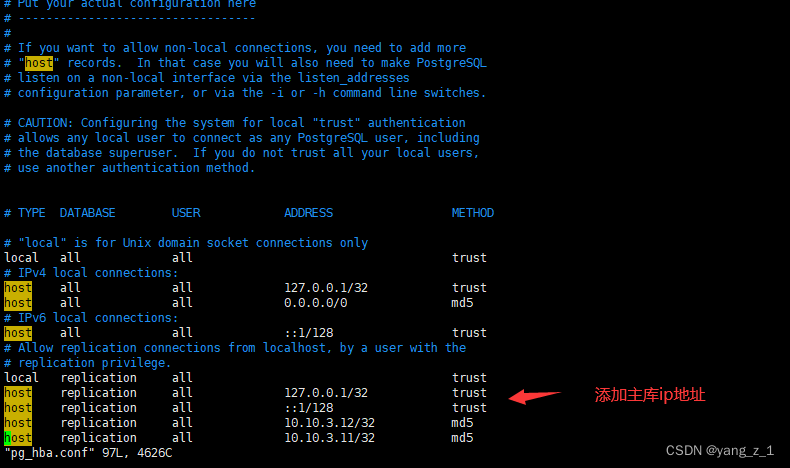
修改 pg_hba.conf文件
添加主库ip地址到pg_hba.conf文件。
2.4 重启备库
/usr/pgsql-11/bin/pg_ctl -D /u01/apps/pgsql/data/ stop
/usr/pgsql-11/bin/pg_ctl -D /u01/apps/pgsql/data/ start
再次查看备库状态;
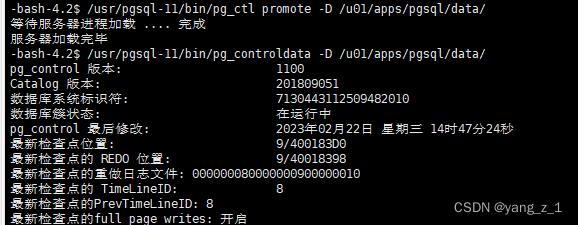
现在备库已经成为了新的主库。
3. 旧主库切换成备库;
3.1 查看数据库状态:
现在数据库状态应该是关闭的。
3.2 修改参数文件
进入 数据库目录下,修改pg_hba.conf文件 ,跟备库的一致,添加旧主库IP(就是本机数据库ip)。
添加 recovery.conf 文件1
vim recovery.conf
内容如下:
standby_mode ='on'
primary_conninfo ='host = 10.10.3.12 port = 5432 user = replication password = replication'
trigger_file = '/tmp/pgsql_master'
host为新的主库ip地址,port 为新的主库的端口 user为主备传输用户
文件赋权
chown -R postgres:postgres recovery.conf
注意: 现在主从库的pg_hba.conf文件上都应该有现在从库的ip地址!!!!!!!!
3.3 启动从库
/usr/pgsql-11/bin/pg_ctl -D /u01/apps/pgsql/data/ start
4 查看状态
- 在新的主库上查看:
select * FROM pg_stat_replication ;
查看是否有数据。
- 在主从库中执行select pg_is_in_recovery();是否为主从。
- 在主库上创建新表,在从库上查看是否同步
以上都没有问题,就表示主从切换成功了。如果要切换回去,也是上面的操作。
后记
如果本文章有何错误,请您评论中指出,或联系我,我会改正,如果您觉得这篇文章有用,请帮忙一键三连,让更多的人看见,谢谢
作者 yang_z_1 csdn博客地址: https://blog.csdn.net/yang_z_1?type=blog