国内做网站比较好的公司有哪些购物网站建设存在的问题

简介
这次打ctf遇到了一个比较经典的osint类题目,在这里分享一下如何做此类题目
题目链接:
https://platform.lac.tf/challs
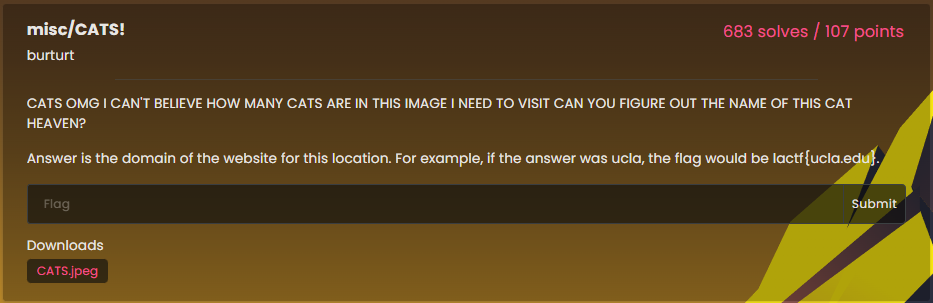
题目简介: 你能猜出这个猫天堂的名字吗?答案是此位置的网站域。例如,如果答案是 ucla,则flag将是lactf{ucla.edu}
分析
下载图片,打开可以看到一群猫猫
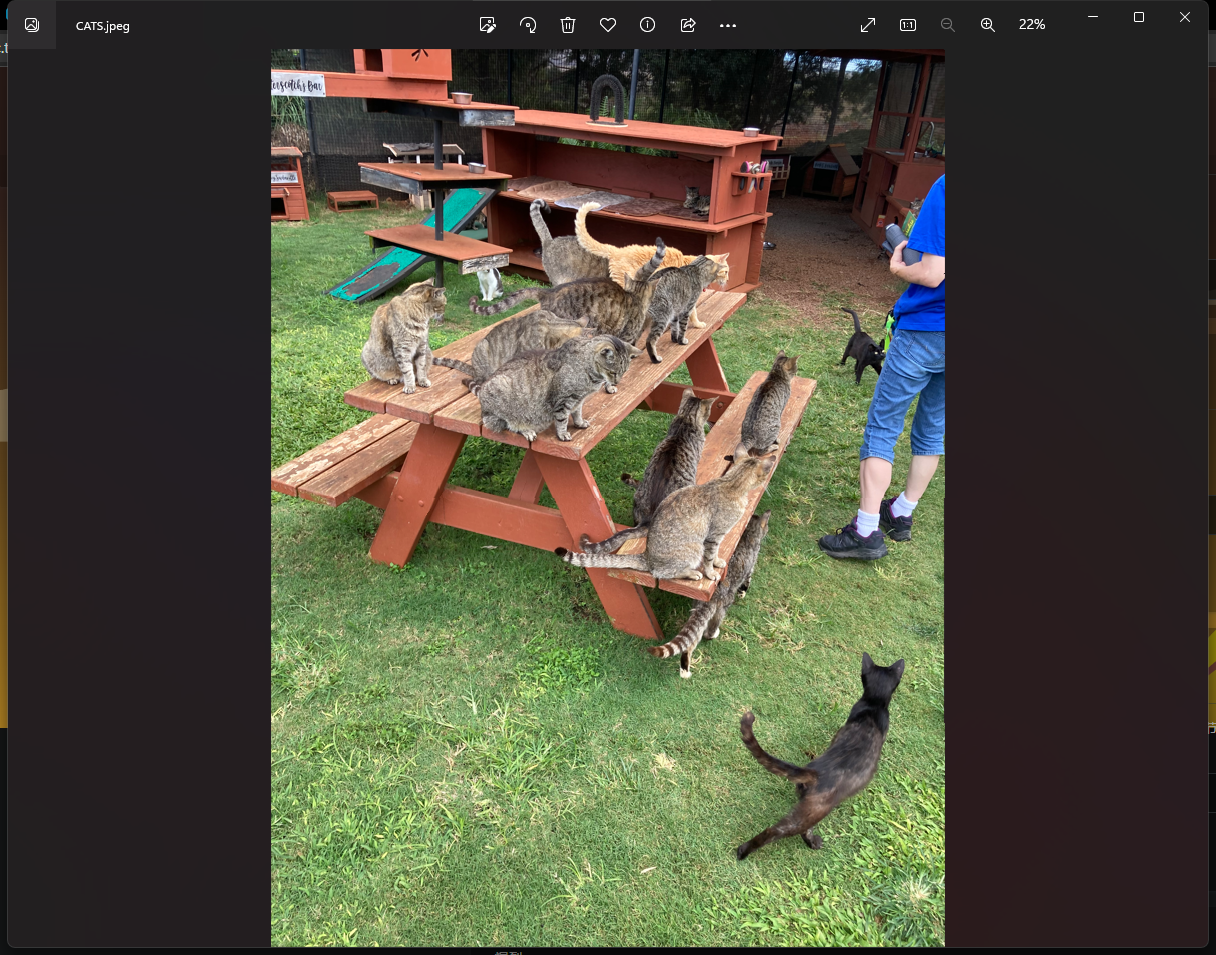
表面分析
照片里的这个人看起来是白种人,猜测在欧洲或者北美,并且周围的标签都是英文,猜测这是一个以英文为主的国家
现在检查一下这个图片的exif信息
什么是exif信息
在我们拍摄图片时,exif可以记录数码照片的属性信息和拍摄数据
exif分析
这里使用kali系统里的exiftool工具来提取这张图片的exif信息
exiftool CATS.jpeg
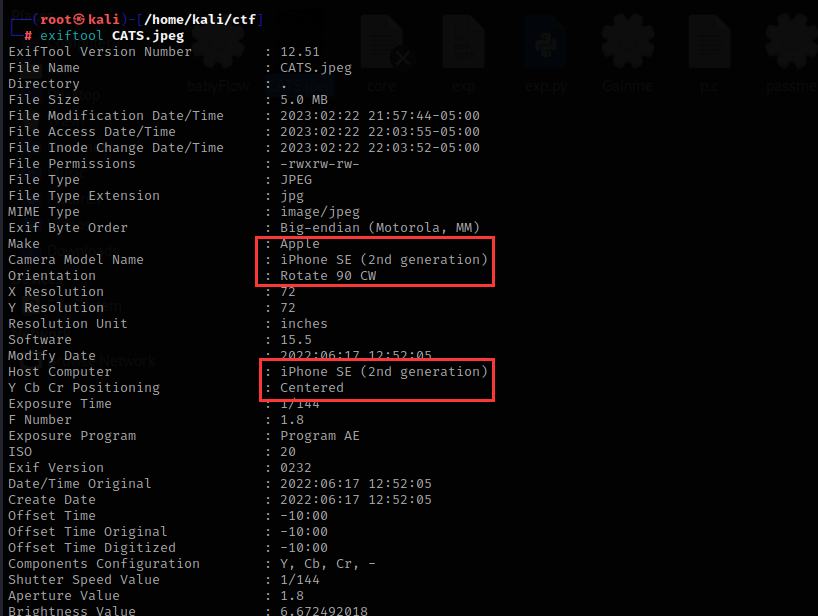
这张照片是由iphone拍摄的,型号为iphone se
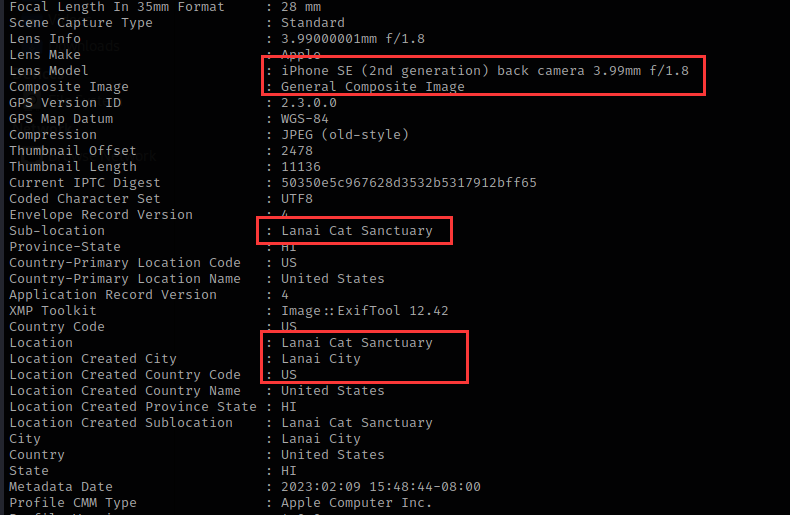
拍摄的位置是一个叫Lanai猫保护区的地方,城市名叫Lanai城,国家为美国
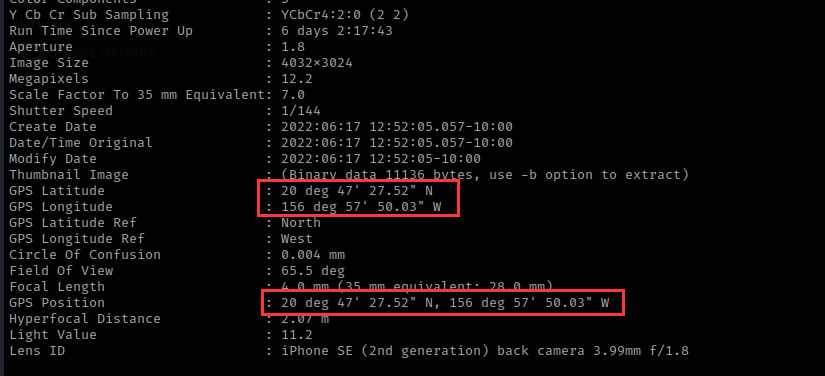
在这里还能看到经纬度信息
20 deg 47' 27.52" N, 156 deg 57' 50.03" W
获取地点与网站域名
题目叫我们找拍摄照片组织的官网,这里我们得到了以下信息
国家:美国
城市:lanai城
地点:lanai猫保护区
经纬度:20 deg 47' 27.52" N, 156 deg 57' 50.03" W
有了这么多关键信息,直接google就能找到官网,关键词
US Lanai Cat Sanctuary
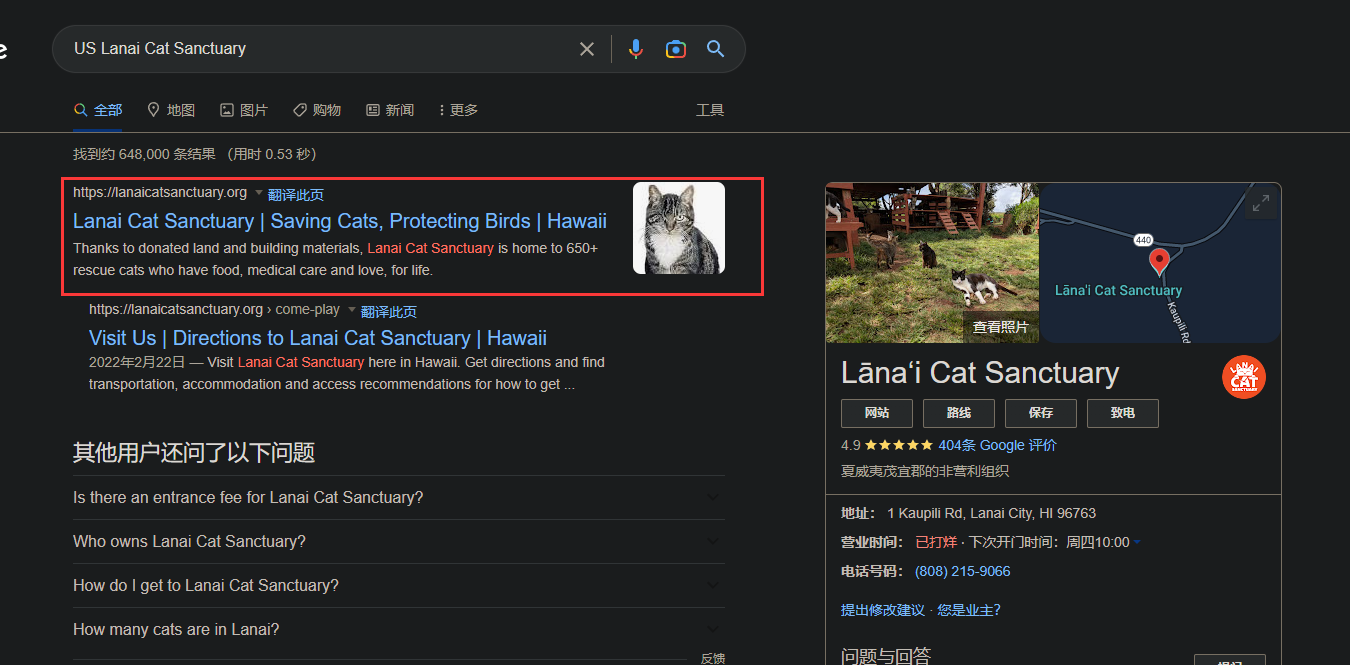
或者根据经纬度
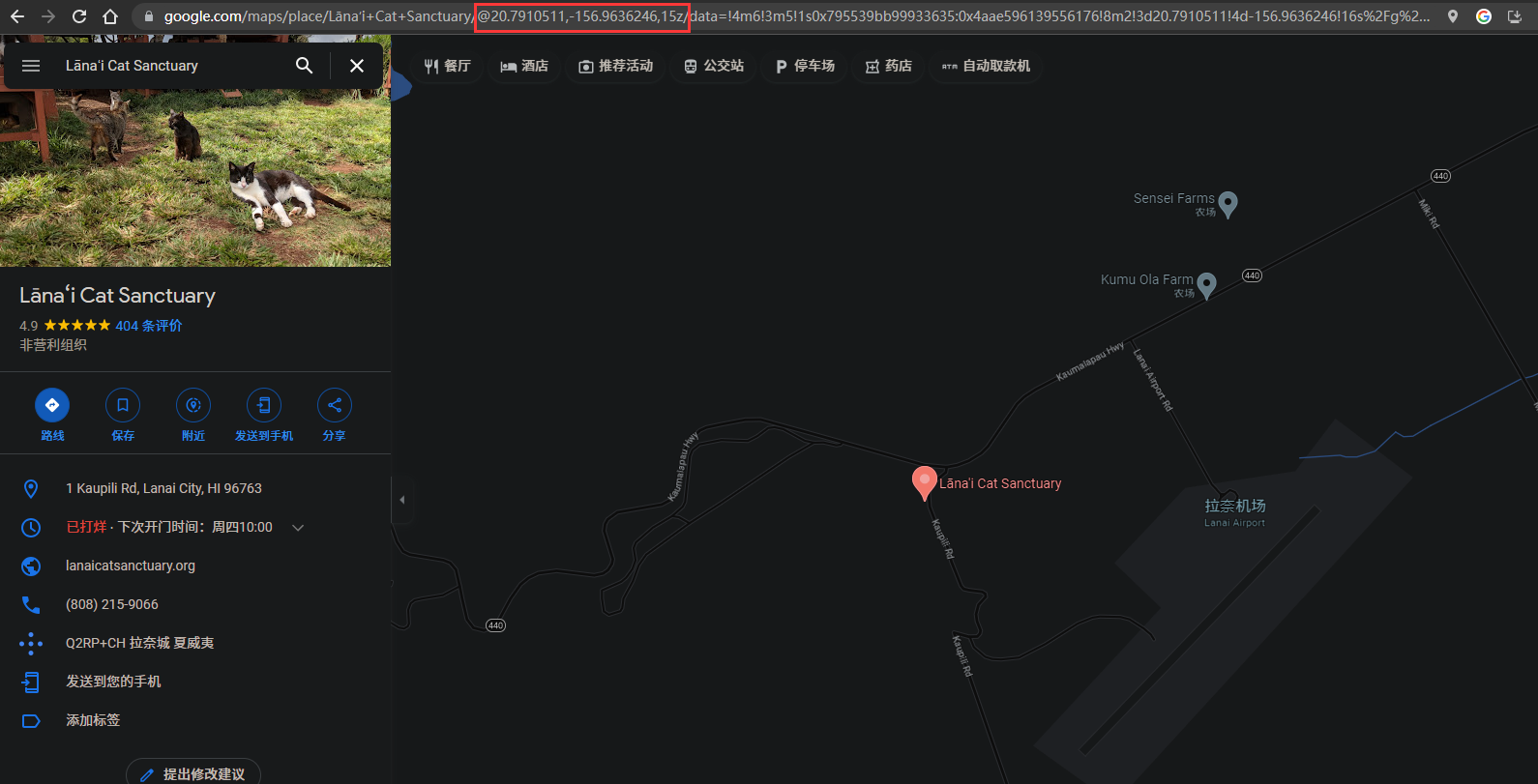
网站域名为:https://lanaicatsanctuary.org/
flag为:
lactf{lanaicatsanctuary.org}
静下心来时刻梳理已经提取到的信息是很重要的,因为osint是在互联网里搜索一个指定的目标,就像是在大海捞针
如果没有exif信息该怎么办
图片里没有exif信息就需要通过图片来分析所在地
假设你有一张图片,但是不知道图片在哪里拍摄的,没有exif数据,没有有用的信息,我们如何找到图片拍摄的位置呢

这是一张图片,难度为简单,假设我们要调查这张图片,我们能从中找到什么信息呢
其实这张图里有很多信息
汽车
这是一辆凯迪拉克汽车,我们可以寻找出售凯迪拉克汽车的地方来缩小寻找的范围
我们还可以看到,这辆凯迪拉克停在路的右侧,方向盘在车辆的左侧,所以可以确定这个国家的汽车方向盘是左边的
我们还可以看这个车牌,可以说明这辆车所在的国家
背景
我们可以看见周围有很多雪,说明这张照片不是在南半球或者赤道附近拍的
我们可以根据十字架来判断这是一个教堂
还有一座桥,路灯,路牌,河流
现在我们从这张照片获取了很多信息,首先我们进行google图片搜索
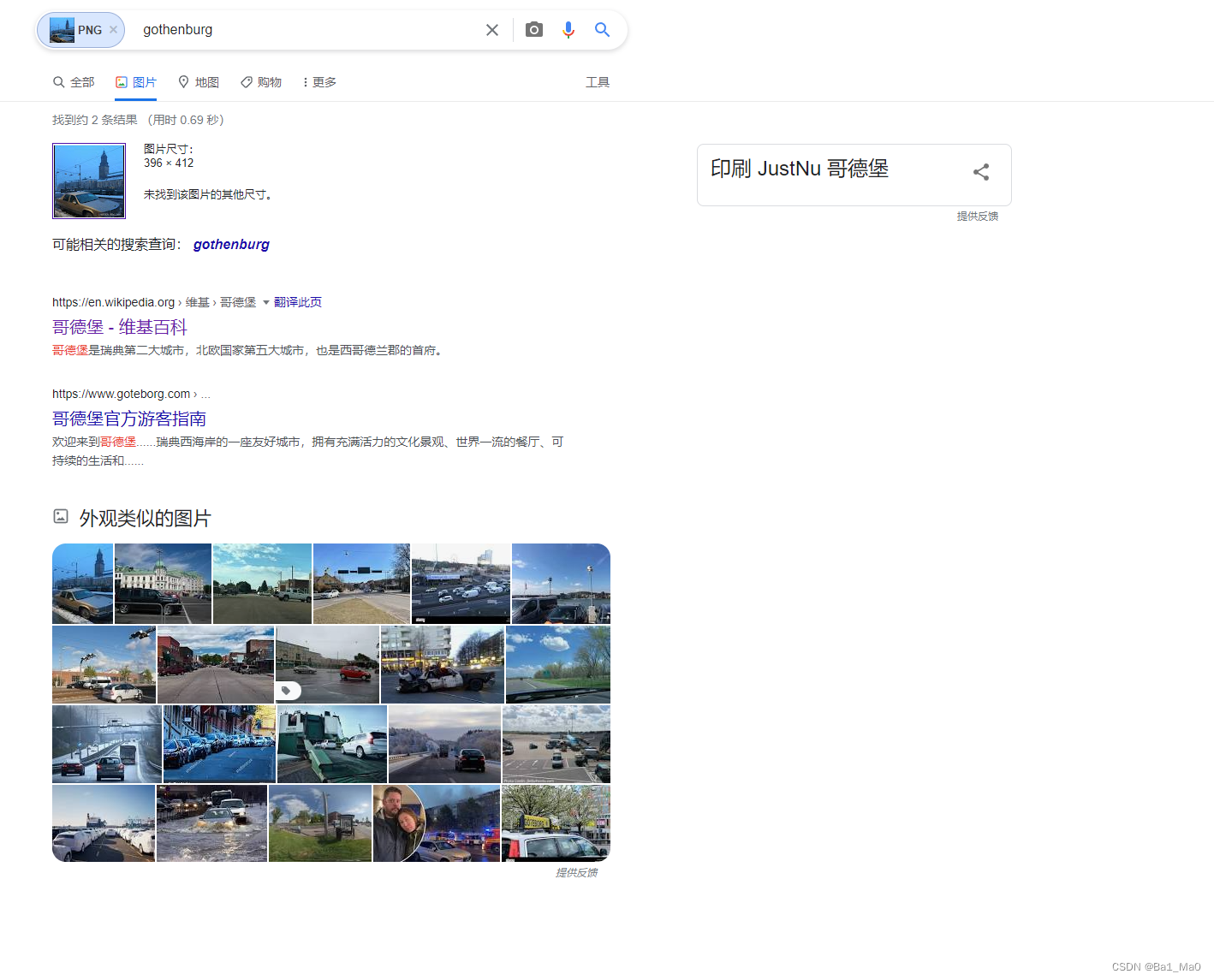

这可能是在瑞典哥德堡境内拍摄的图像,根据我们前面的环境分析,来进一步确定
然后进入Google地图,我们的关键词为
瑞典哥德堡 教堂
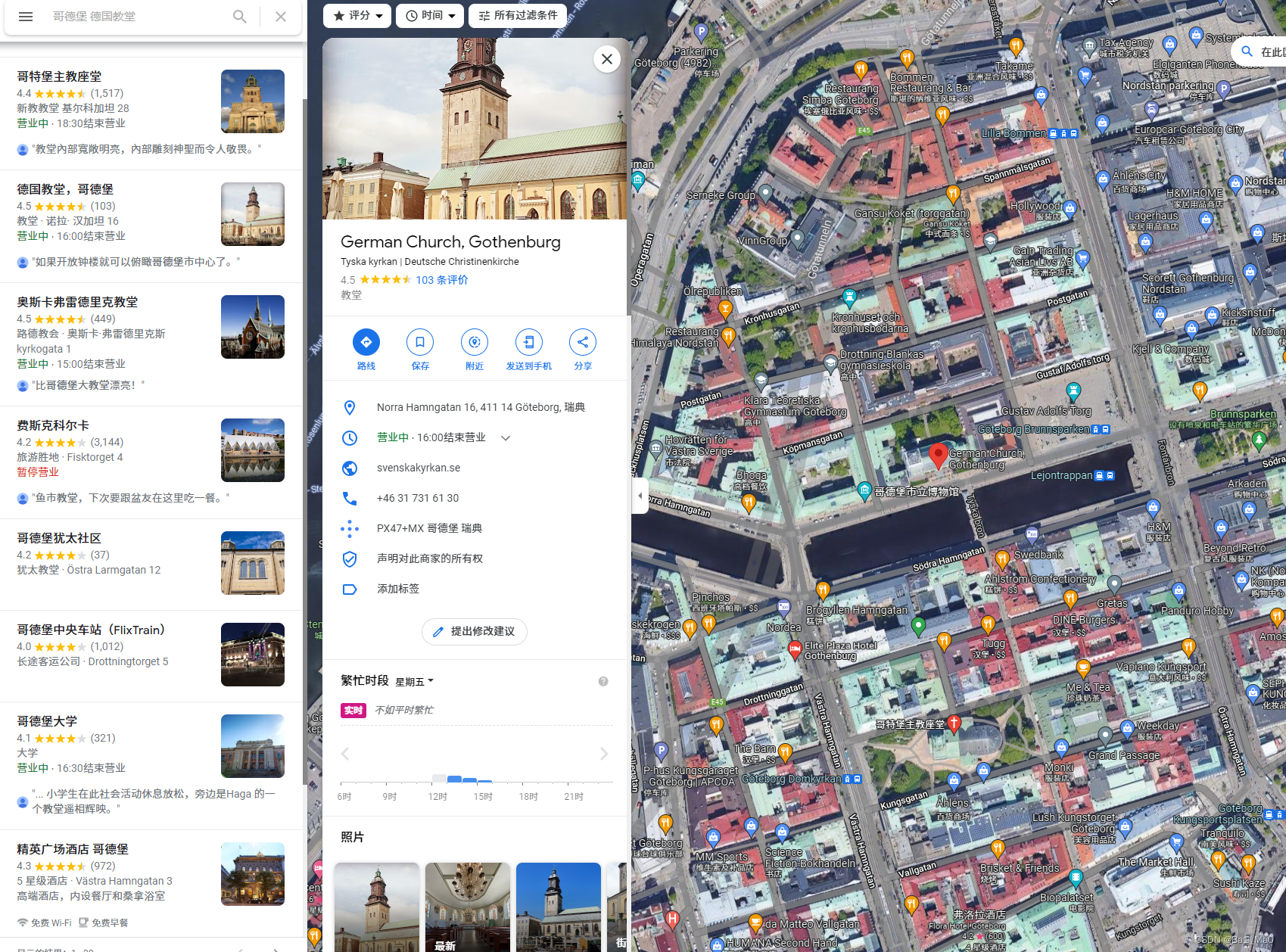
这个地方很符号我们的判断
教堂,桥,分岔口,路牌,河流
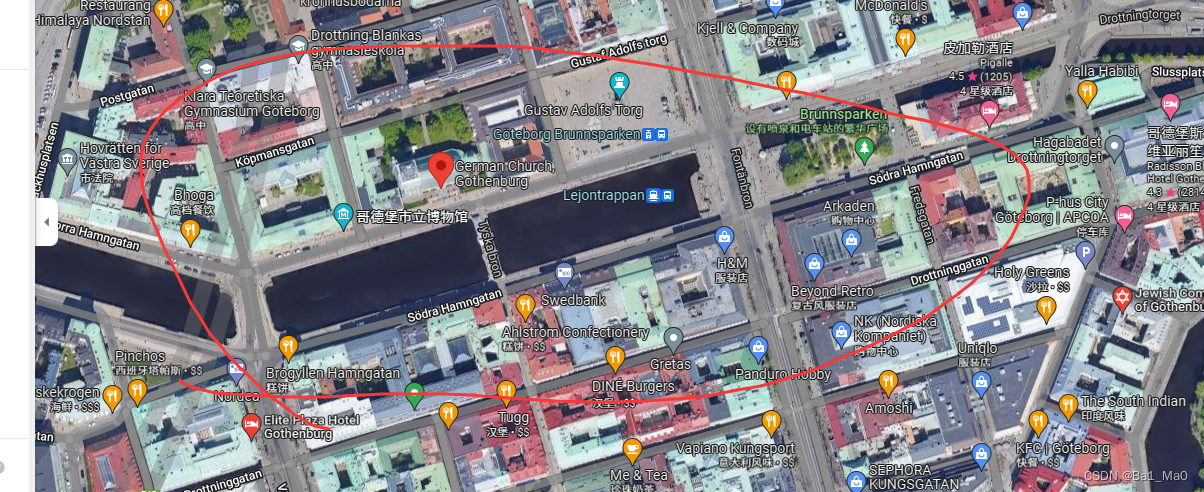

成功通过图片找到地址
反向图片搜索
也可以直接用google进行反向图片搜索,通过图片,查找网上关于这张图片留下的痕迹
https://images.google.com
总结
做osint类题目一定要静下心来,从一堆信息中提取有效的信息并整理,还有些题目是找到某人朋友或者不知道谁的的社交账号,这还需要分析人际关系,分析很多细节,遇到打不开的网站,或者别人把flag删掉了,可以用这个网站来查看之前时间的页面
https://web.archive.org/
这个网站可以查看指定网页每一个时间段的信息
osint考得很多,最重要的是分析能力,之前我写过一篇很详细的osint文章,大家可以去看看
https://blog.csdn.net/qq_45894840/article/details/124663918