局域网建网站的详细步骤河北城乡建设学校网站
目录结构
- 前言
- 设置neo4j外部访问
- 代码整理
- maven 依赖
- java 代码
- 参考链接

前言
公司需要获取neo4j数据库内容进行数据筛查,neo4j数据库咱也是头一次基础,辛辛苦苦安装好整理了安装neo4j的步骤,如今又遇到数据不知道怎么创建,关关难过关关过,前路漫漫亦灿灿,现调查整理如下:
设置neo4j外部访问
编辑安装目录“C:\Users\admin\Desktop\Neo4j\neo4j-community-5.8.0\conf\neo4j.conf”文件,大概在83行;
# Bolt connector
server.bolt.enabled=true
#server.bolt.tls_level=DISABLED
# 修改前...
# server.bolt.listen_address=:7687
# 修改后...
server.bolt.listen_address=0.0.0.0:7687
#server.bolt.advertised_address=:7687# HTTP Connector. There can be zero or one HTTP connectors.
server.http.enabled=true
# 修改前...
# server.http.listen_address=:7474
# 修改后...
server.http.listen_address=0.0.0.0:7474
#server.http.advertised_address=:7474
代码整理
maven 依赖
<dependency><groupId>org.neo4j.driver</groupId><artifactId>neo4j-java-driver</artifactId><version>4.2.0</version>
</dependency>
<!-- 此demo中以下依赖可以不加,但在项目中需要加以下依赖,否则加载驱动时加载不成功 -->
<dependency><groupId>org.neo4j</groupId><artifactId>neo4j</artifactId><version>3.3.4</version>
</dependency>
java 代码
import org.apache.commons.collections4.MapUtils;
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
import org.neo4j.driver.Session;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
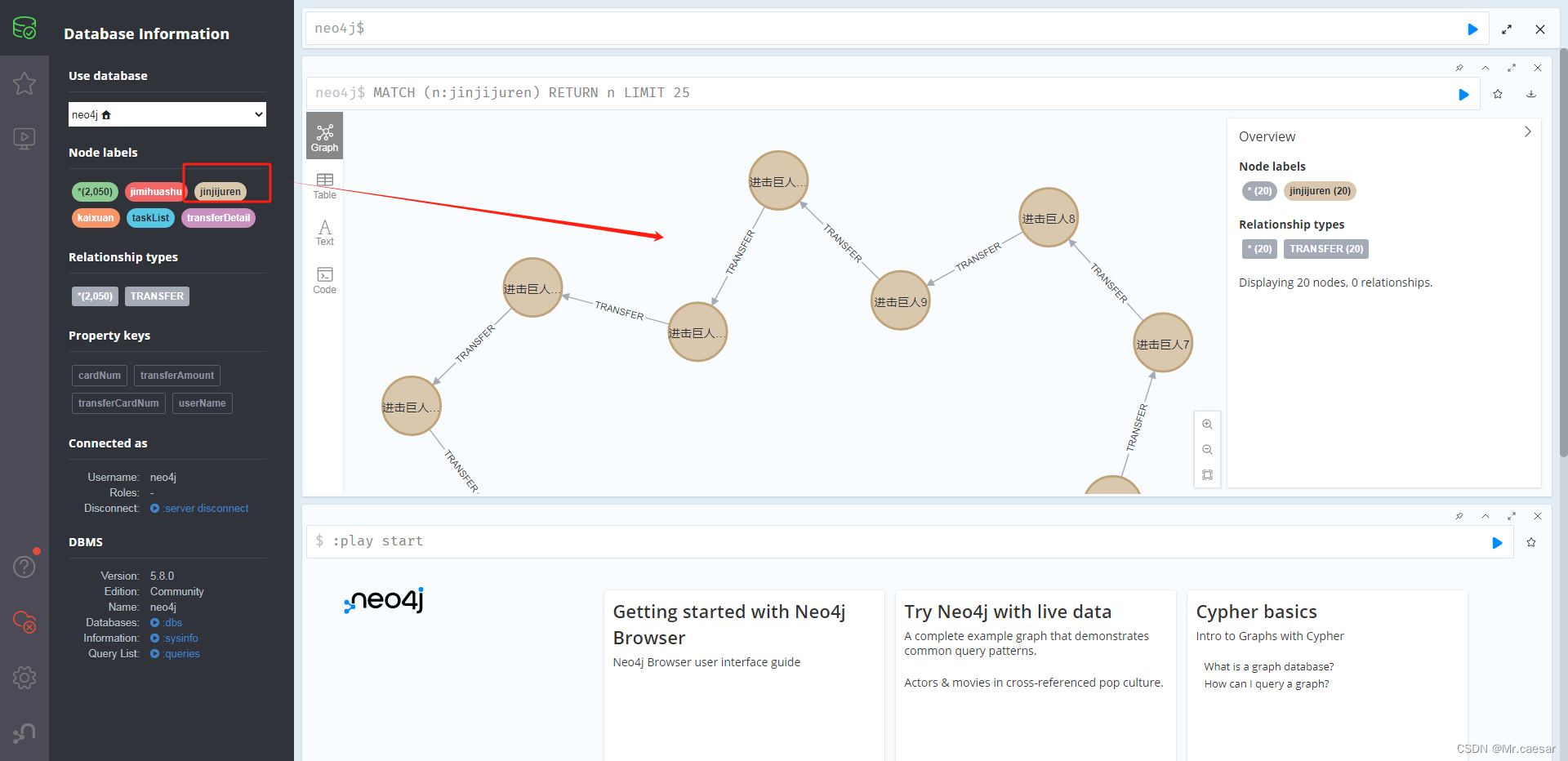
import java.util.Map;public class Kaixuan {private static final Integer DATA_SIZE = 20;private static List<Map<String, Object>> generateData() {List<Map<String, Object>> datas = new ArrayList<>(DATA_SIZE);Map<String, Object> tmpMap = null;for (int i = 0; i < DATA_SIZE; i++) {tmpMap = new HashMap<>();datas.add(tmpMap);tmpMap.put("cardNum", i);tmpMap.put("userName", "进击巨人" + i);tmpMap.put("transferCardNum", (i + 1) % 20);tmpMap.put("transferAmount", i);}return datas;}private static void inertNeo4jTest() {// 构造数据, 数据和pg 库里面的数据一样List<Map<String, Object>> datas = generateData();Driver driver = GraphDatabase.driver("bolt://192.168.1.111:7687", AuthTokens.basic("neo4j", "123qweQWE"));Session session = driver.session();// 手动create to neo4jString createCQLTemplate = "create (n:jinjijuren {cardNum: '$cardNum', userName: '$userName', transferCardNum: '$transferCardNum', transferAmount: '$transferAmount'})";for (Map<String, Object> data : datas) {String createCQL = createCQLTemplate.replace("$cardNum", MapUtils.getString(data, "cardNum")).replace("$userName", MapUtils.getString(data, "userName")).replace("$transferCardNum", MapUtils.getString(data, "transferCardNum")).replace("$transferAmount", MapUtils.getString(data, "transferAmount"));session.run(createCQL);}// 手动维护关系String mergeCQLTemplate = "match (a:jinjijuren{cardNum: '$cardNum1'}), (b:jinjijuren{cardNum: '$cardNum2'}) MERGE(a)-[:TRANSFER{transferAmount: '$transferAmount'}]->(b)";datas.forEach(data -> {String mergeCQL = mergeCQLTemplate.replace("$cardNum1", MapUtils.getString(data, "cardNum")).replace("$cardNum2", MapUtils.getString(data, "transferCardNum")).replace("$transferAmount", MapUtils.getString(data, "transferAmount"));session.run(mergeCQL);});// close resourcesession.close();driver.close();}public static void main(String[] args) {inertNeo4jTest();}
}
参考链接
- https://www.cnblogs.com/qlqwjy/p/14774488.html