网站运营分析报告做金融资讯用什么网站程序
4.6、继承
继承是面向对象三大特征之一
有些类与类之间存在特殊的关系,例如下图中:

我们发现,定义这些类的定义时,都拥有上一级的一些共性,还有一些自己的特性。那么我们遇到重复的东西时,就可以考虑使用继承的技术,减少重复代码。
4.6.1、继承基础语法
- class 子类: 继承方法 父类
class bigDog : public dog
- 子类 也称为 派生类
- 父类 也成为 基类
#include<iostream>
using namespace std;
//所有的狗都会吃饭跑步,但皮肤颜色不同
class dog {
public:void eatFood() {cout << "吃饭" << endl;}void run() {cout << "跑步" << endl;}
};//继承实现
class bigDog :public dog {
public://皮肤void skin() {cout << "焦黄色" << endl;}
};void test01() {bigDog bg;bg.eatFood();bg.run();bg.skin();
}
int main() {test01();system("pause");return 0;
}
4.6.2、继承方式
语法:class 子类: 继承方法 父类
-
继承的方式一共有三种
- 公共继承
- 保护继承
- 私有继承

- 公共继承
//公共继承
class Base1 {
public:int m_A;
protected:int m_B;
private:int m_C;
};class Son1 :public Base1 {
public:void func() {m_A = 10; //公共权限成员依然是公共权限m_B = 10; //保护权限成员 依然是保护权限 类内可以访问//m_C = 10; //不能访问私有权限}
};void test01() {Son1 s1;s1.m_A = 100;
}

- 保护继承
//保护继承
class Base2 {
public:int m_A;
protected:int m_B;
private:int m_C;
};class Son2 : protected Base2 {void func() {m_A = 100; //公共成员变为子类变成保护权限m_B = 100; //保护权限还是保护权限//m_C = 100 //不能访问私有权限}
};void test02() {Son2 s2;//s2.m_A = 1000;//在Son2中m_A变成了保护权限,因此类外不可访问
}

- 私有继承
//私有继承
class Base3 {
public:int m_A;
protected:int m_B;
private:int m_C;
};class Son3 :private Base3 {void func() {m_A = 100; //公共成员变为子类变成保护权限m_B = 100; //保护权限还是保护权限//m_C = 100 //不能访问私有权限}
};void test03() {Son3 s3;//s3.m_A = 1000; // 在Son3中m_A变成了保护权限,因此类外不可访问
}

4.6.3、继承中的对象模型
问题:从父类继承过来的成员,哪些是属性子类对象中
- sizeof输出
#include<iostream>
using namespace std;
class Base1 {
public:int m_A;
protected:int m_B;
private:int m_C;
};class Son :public Base1 {
public:int m_D;
};//查看父类到底继承了是属性子类对象中
//私有属性虽然是访问不到,但是会被继承下去
void test01() {cout << "size of Son = " << sizeof(Son) << endl;
}
int main() {test01();system("pause");return 0;
}

2 第二种方式(开发者命令提示工具查看对象模型)
- 找到自己的文件 切换到自己文件路径下
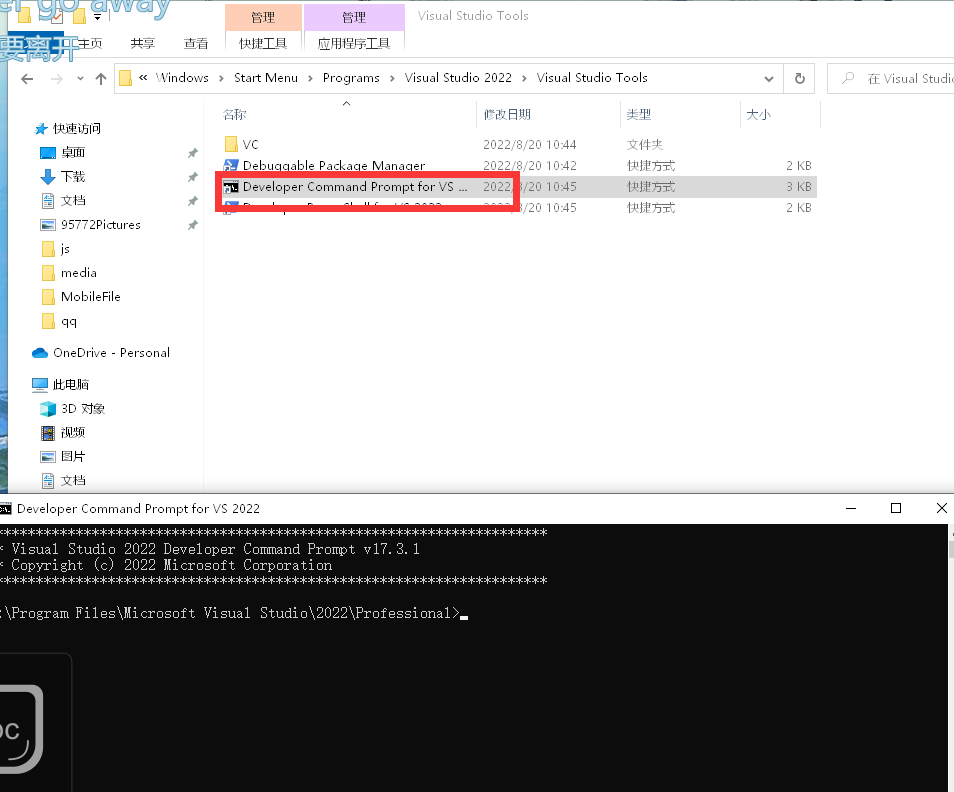

敲如下指令
cl /d1 reportSingleClassLayout类名 文件名
-
cl /d1 reportSingleClassLayoutSon “3 继承中的对象模型.cpp”
这里的Son是对应子类的名字“3 继承中的对象模型.cpp” 对应的你cpp文件名字

然后我们就可以看到结果了

4.6.4、继承中构造和析构顺序
子类继承父类后,当创建子类对象,也会调用父类的构造函数
问题:父类和子类的构造和析构顺序是谁先谁后?
父子子父
#include<iostream>
using namespace std;
//继承中的构造和析构顺序
class Base {
public:Base() {cout << "Base构造函数被调用" << endl;}~Base(){cout << "Base析构函数被调用" << endl;}
};class son1 : public Base {
public:son1() {cout << "son1构造函数被调用" << endl;}~son1(){cout << "son1析构函数被调用" << endl;}
};void test01(){son1 s;
}
int main() {test01();system("pause");return 0;
}

4.6.5、继承同名成员处理方式
问题:当子类与父类出现同名的成员,如何通过子类对象,访问到子类或父类中同名的数据呢?
- 访问子类同名成员 直接访问即可
- 访问父类同名成员 需要加作用域
//继承中同名成员处理
class Base {
public:Base() {m_A = 100;}void func() {cout << "Base func调用" << endl;}void func(int a) {cout << "Base func(int a)调用" << endl;}int m_A;
};class son :public Base {
public:son() {m_A = 200;}void func() {cout << "son func调用" << endl;}int m_A;
};void test01() {son s1;cout << "s1的m_A的值:" << s1.m_A << endl; //要访问父类的同名成员,需要加作用域cout << "s1的m_A的值:" << s1.Base::m_A << endl; s1.func();s1.Base::func();//如果子类中出现和父类同名的成员函数,子类的同名成员会隐藏掉父类中的所有同名函数//要想访问就必须加作用域//s1.func(100);
}
4.6.6、继承同名静态成员处理方式
问题:继承中同名的静态成员在子类对象上如何进行访问?
静态成员和非静态成员出现同名时,方法处理一致
- 访问子类同名成员 直接访问即可
- 访问父类同名成员 需要加作用域
//继承中的同名静态成员处理方式
class Base {
public:static int m_A;static void func() {cout << "Base - func()" << endl;}
};
int Base::m_A = 100;class Son :public Base {
public:static int m_A;static void func() {cout << "Son - func()" << endl;}
};
int Son::m_A = 200;//同名静态成员属性
//void test01() {
// //通过对象访问
// Son s;
// cout << "Son 下的m_A = " << s.m_A << endl;
// cout << "Base 下的m_A = " << s.Base::m_A << endl;
//
// //通过类名访问
// cout << "通过类名访问:" << endl;
// cout << "Son 下的m_A = " << Son::m_A << endl;
// //第一个::代表通过类名方式访问 第二个::代表访问父类作用域下
// cout << "Base 下的m_A = " << Son::Base::m_A << endl;
//}void test02() {Son s;s.func();s.Base::func();
}
4.6.7、多继承语法
C++允许一个类继承多个类
语法:class 子类 : 继承方式 父类 1, 继承方式 父类2…
多继承可能会引发父类中有同名成员出现,需要加作用域区别
c++实际开发中不建议用多继承
//多继承语法class Base1 {
public:Base1() {m_A = 100;}int m_A;
};
class Base2 {
public:Base2() {m_A = 200;}int m_A;
};//子类 需要继承Base1 和 Base2
class Son :public Base1, public Base2 {
public:Son() {m_C = 300;m_D = 400;}int m_C;int m_D;};void test01() {Son s;//继承后占用的大小cout << "sizeof Son = " << sizeof(s) << endl;//二义性 当多个父类中出现相同的参数名会出现,需要加上作用域cout << s.Base1::m_A << endl;cout << s.Base2::m_A << endl;
}
4.6.8、菱形继承
概念:
- 俩个派生类继承同一个基类
- 又有某个类同时继承着俩个派生类
称这种继承方式叫菱形继承,或者砖石继承

菱形继承问题:
- 同时继承羊和驼的动物属性,羊驼使用的时候会产生二义性
- 羊驼继承动物的数据继承了俩份,我们只需要一份
//动物类
class Aniaml{
public:int m_Age;
};//利用虚继承 解决菱形继承到底问题
//继承之前 加上关键字 virtual 变为 虚继承
//Animal称为虚基类//羊类
class Sheep :virtual public Aniaml {};//驼类
class Camle :virtual public Aniaml {};//羊驼类
class Alpaca : public Sheep, public Camle {};void test01() {Alpaca al;al.Sheep::m_Age = 18;al.Camle::m_Age = 28;cout << "al.Sheep::m_Age = " << al.Sheep::m_Age << endl;cout << "al.Camle::m_Age = " << al.Camle::m_Age << endl;cout << "al.m_Age = " << al.m_Age << endl;
底层会有虚指针(vbptr)指向虚基类表,表中存放的是继承的数据,以及偏移量数据