东阳厂家高端网站设计英文 edm营销 的网站 与 工具
文章目录
- 最小生成树
- 总览
- 生成树
- 广度优先生成树
- 深度优先生成树
- 最小生成树
- Prim算法
- Kruskal算法
- Prim vs Krusakal
- Prim的实现
- Kruskal的实现
- 小结
- 最短路径问题
- 单源最短路径问题
- BFS求无权图的单源最短路径
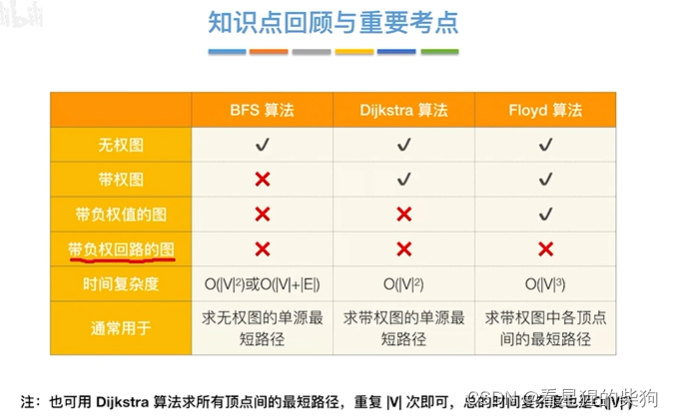
- 小结
- Dijkastra算法
- 算法时间复杂度
- 不适用情况
- 每一对顶点的最短路径问题
- Floyd算法
- 找两个点的最短路径
- 核心代码
- 实例
- 找两个顶点最短路径
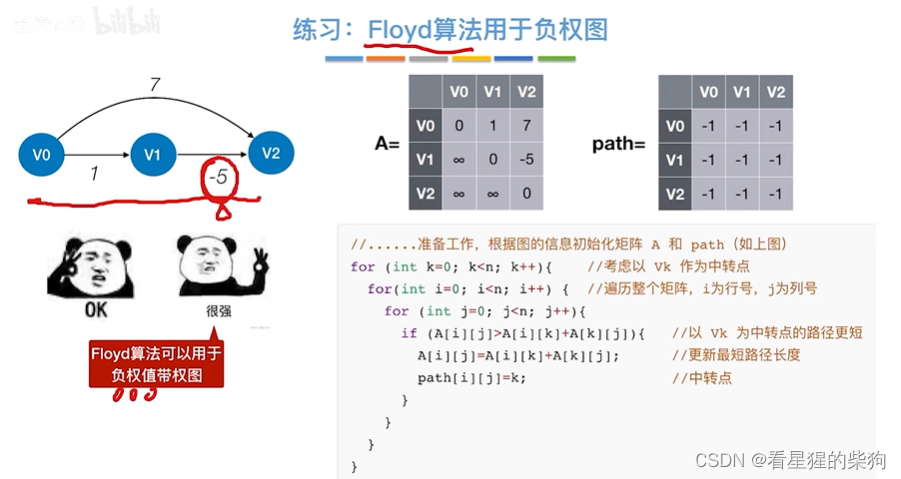
- Floyd用于负权图
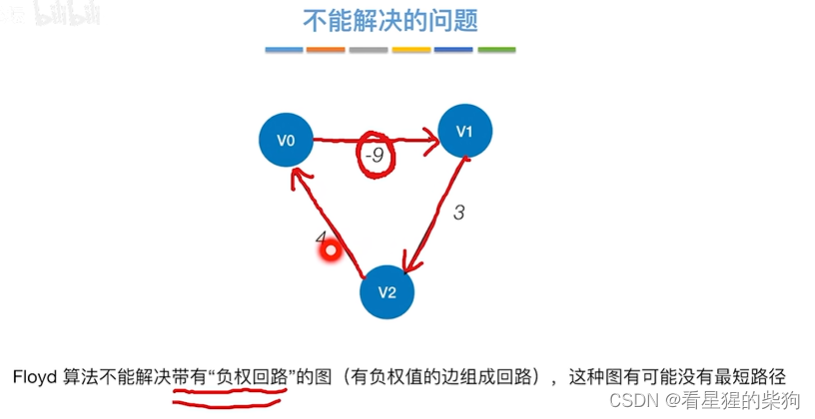
- 不能解决的问题
- 小结
最小生成树
总览

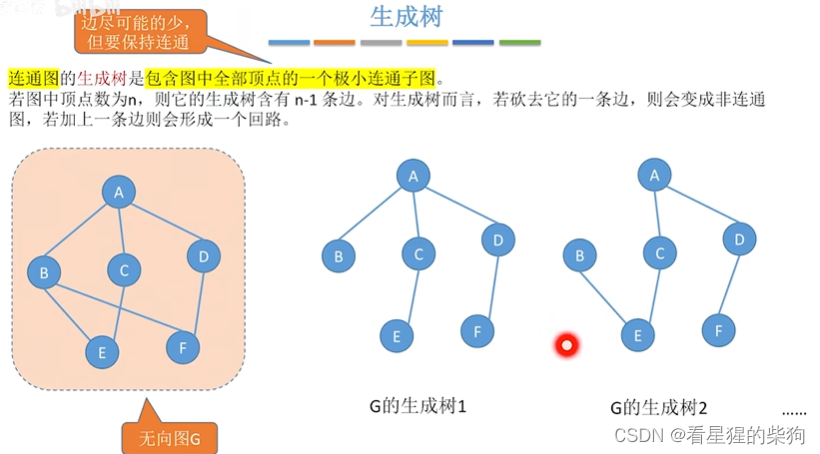
生成树
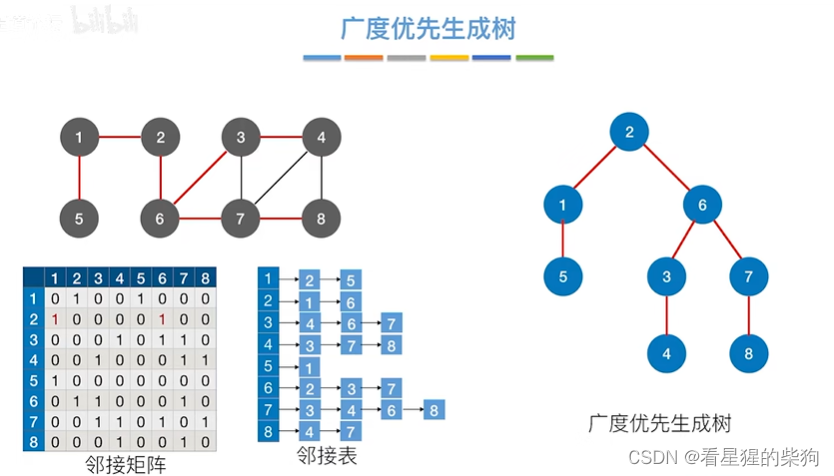
广度优先生成树
深度优先生成树

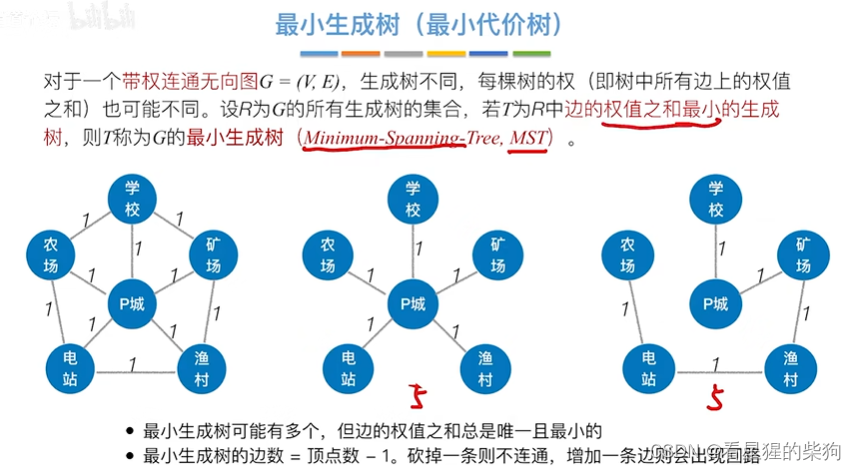
最小生成树
针对的是带权连通图
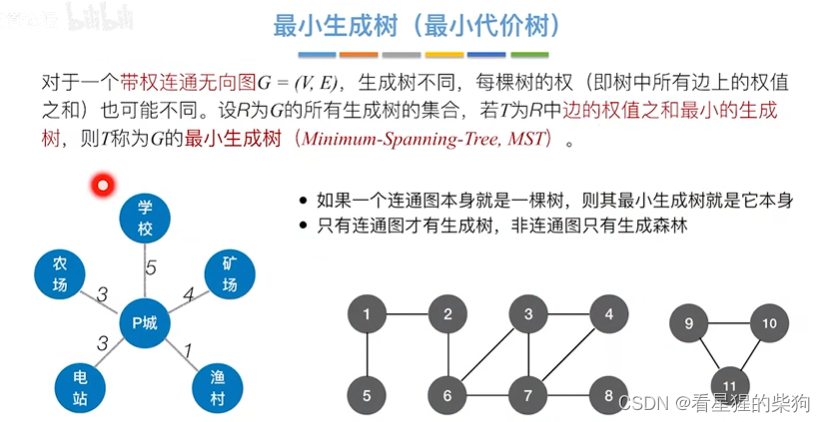

Prim算法
同一个图的最小生成树可能不唯一
从p城出发

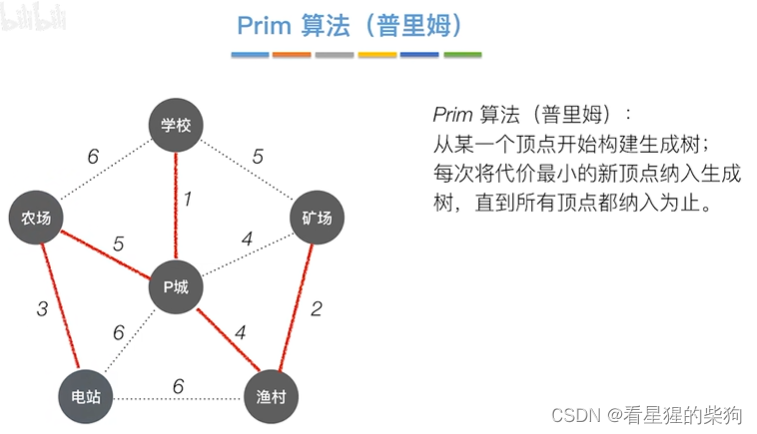
从农场出发也一样
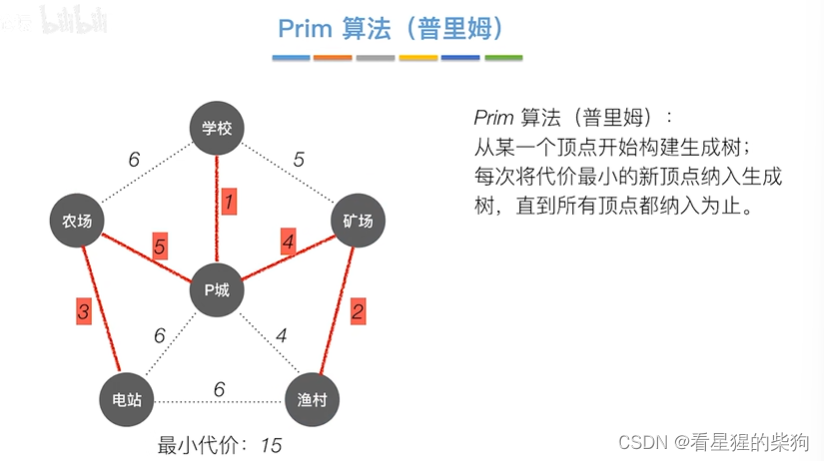
Kruskal算法
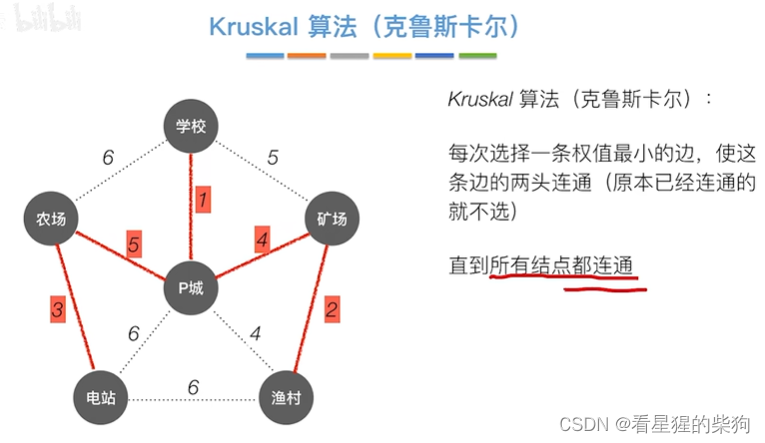
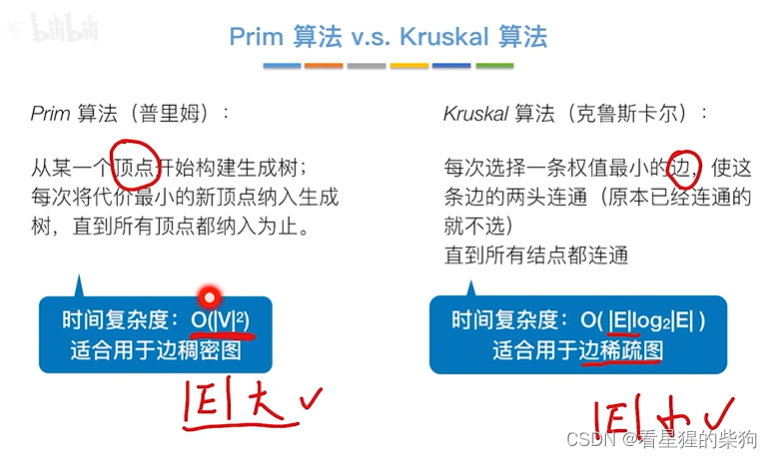
Prim vs Krusakal
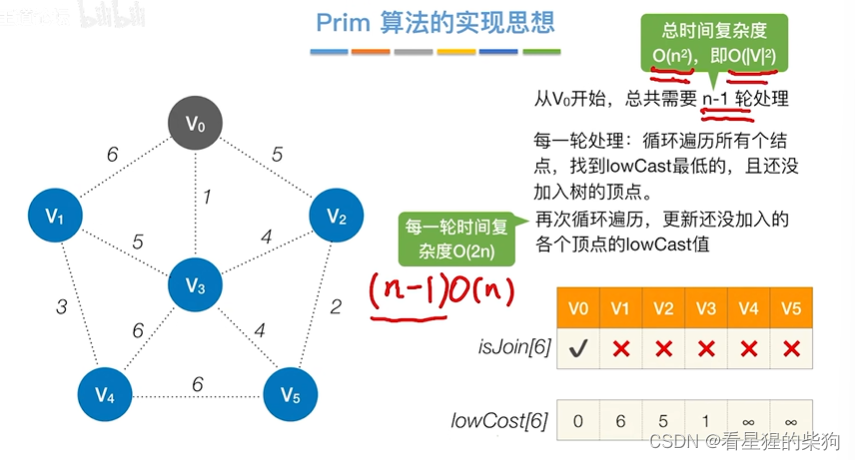
Prim的实现
先找到最低代价的节点,每次将节点加入树后,需要更新各节点加入树的最低代价(即将原来的代价和个节点与加入节点的代价作比较)
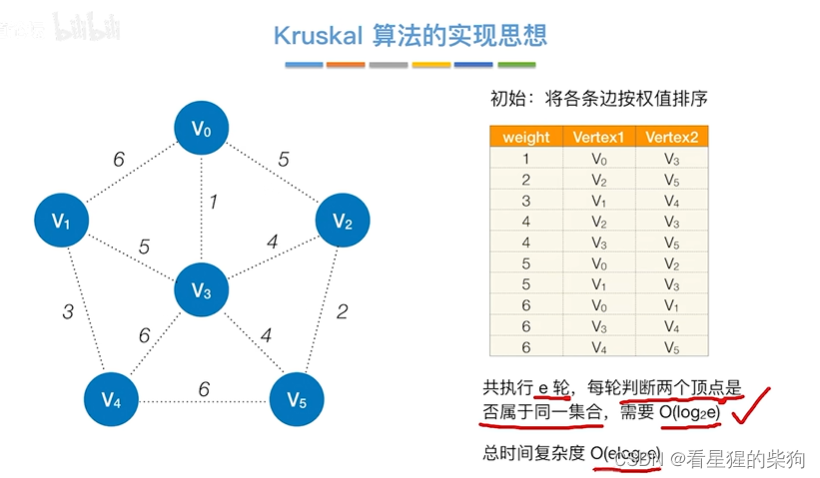
Kruskal的实现
查找并查集(如果用二叉树实现的)的根需要log2E
小结

最短路径问题
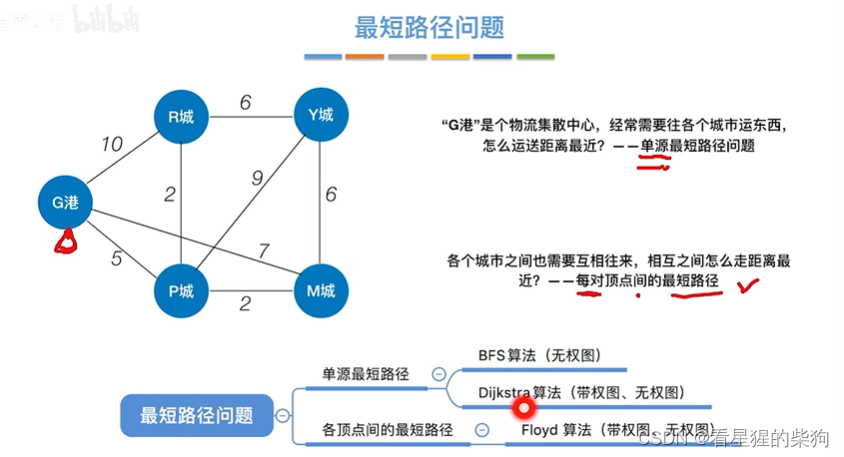
单源最短路径问题
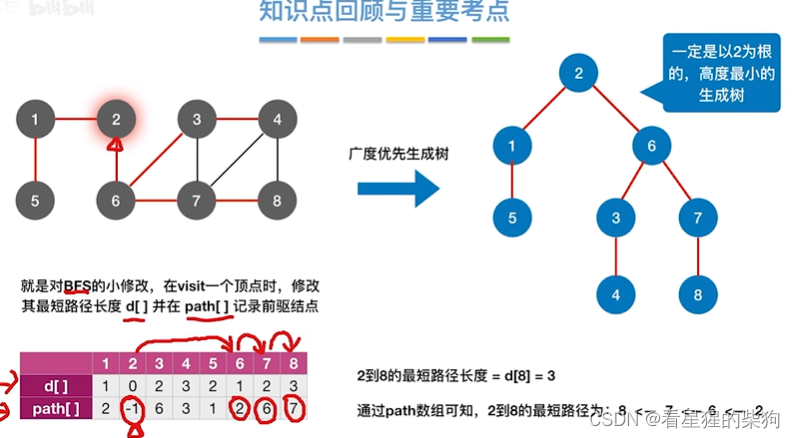
BFS求无权图的单源最短路径
首先访问2号顶点,然后再更新其相邻顶点后的结果
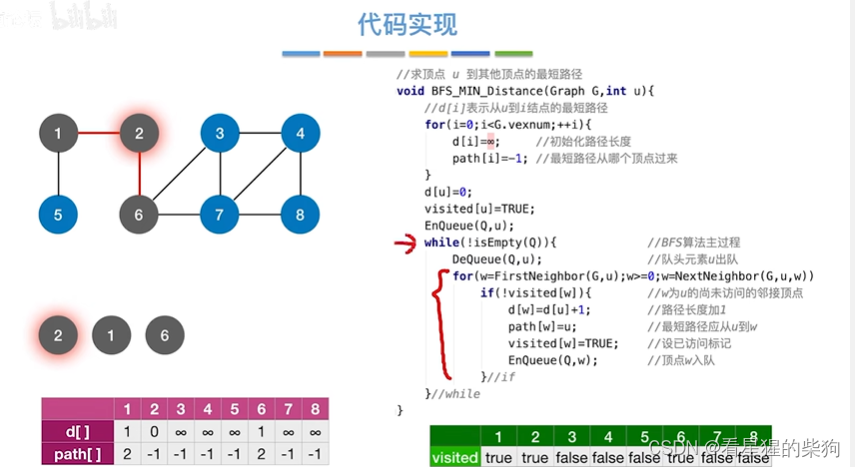
然后1号顶点出队,相邻节点入队,同时更新各相邻节点
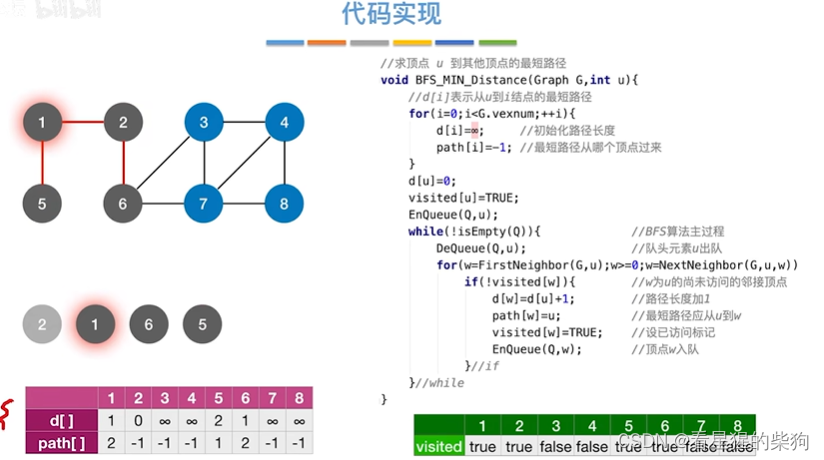
然后6号顶点出队,更新相邻节点,同时各个相邻节点入队

5号顶点没有相邻
所以到3号顶点处理
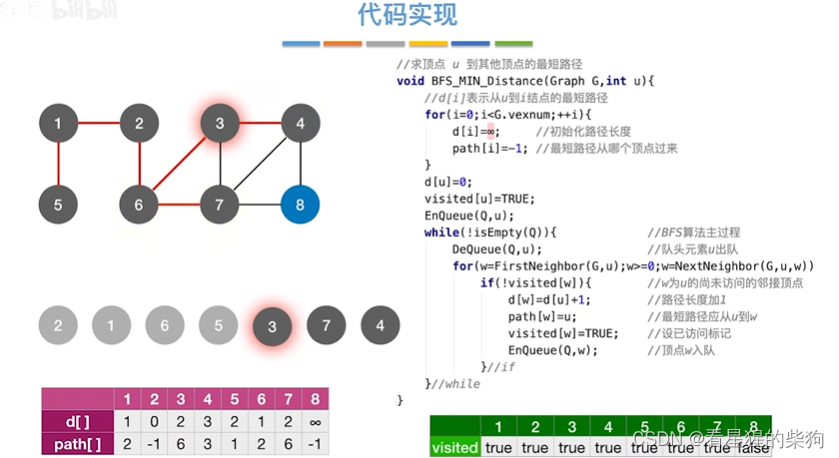
7号顶点处理
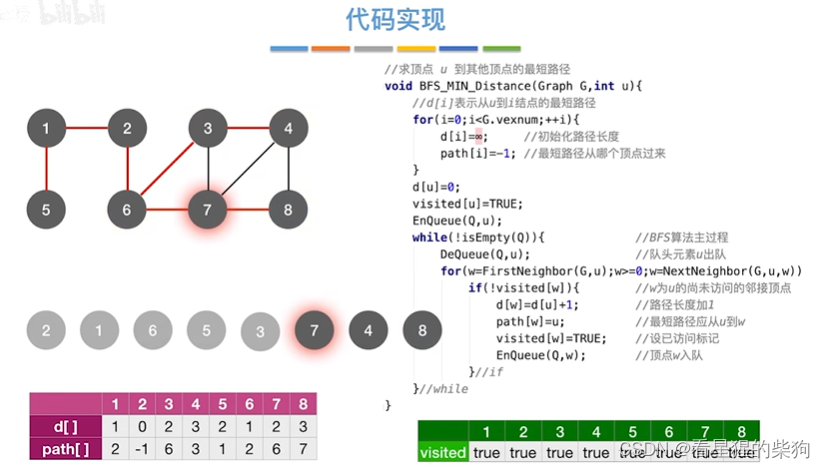
4号和8号相邻节点都被访问,所以没有处理
小结
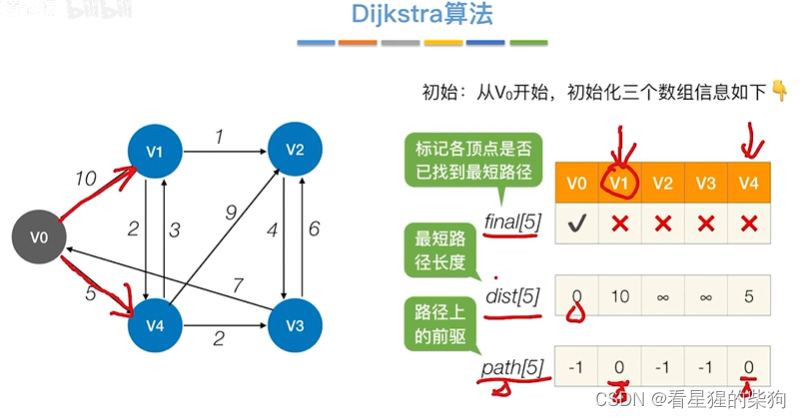
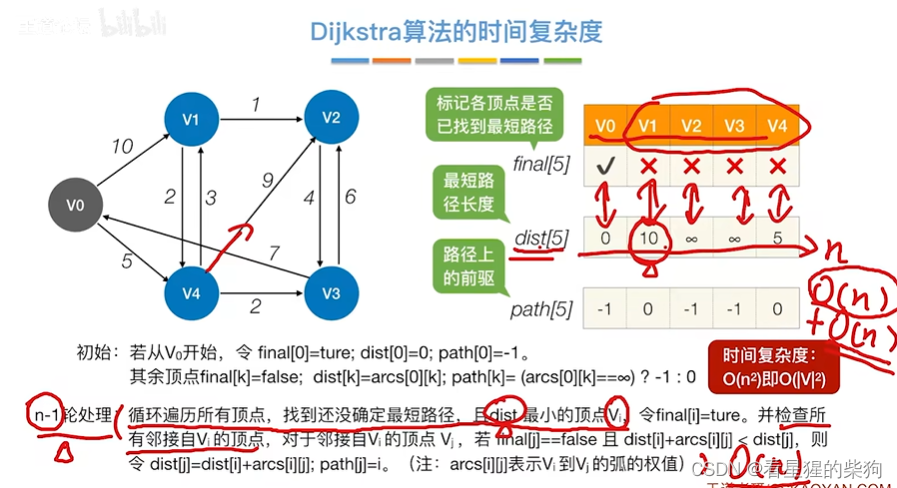
Dijkastra算法
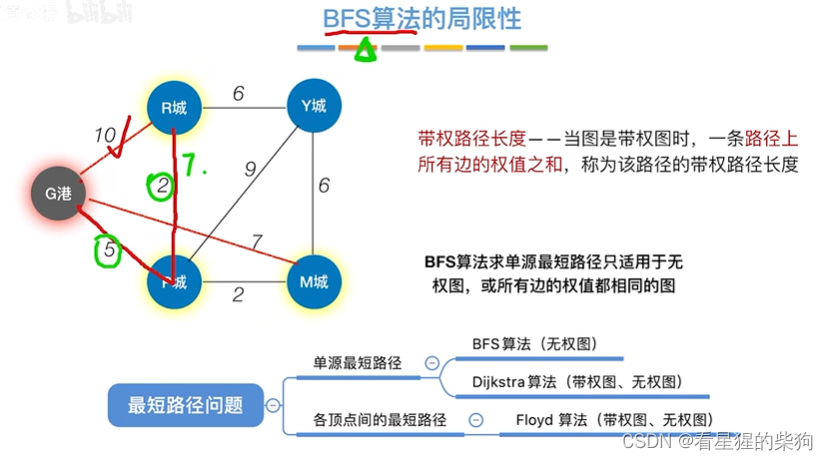
BFS局限性(默认每条路径长度一样)
初始化后,即更新初始节点及其相邻节点
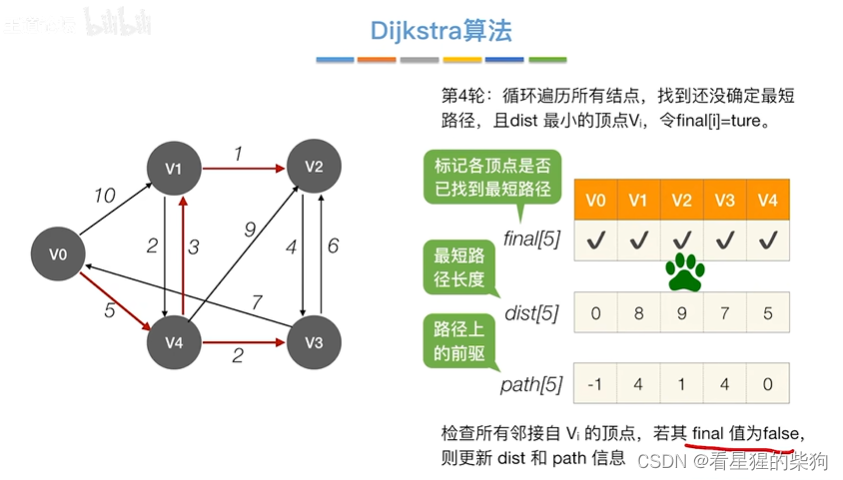
第一轮后

第二轮后

第三轮后

第四轮后
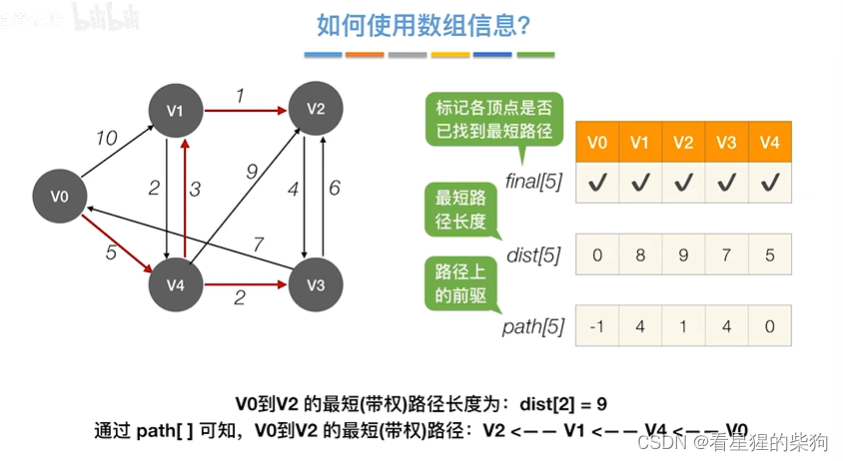
查找两个顶点的最短路径
算法时间复杂度
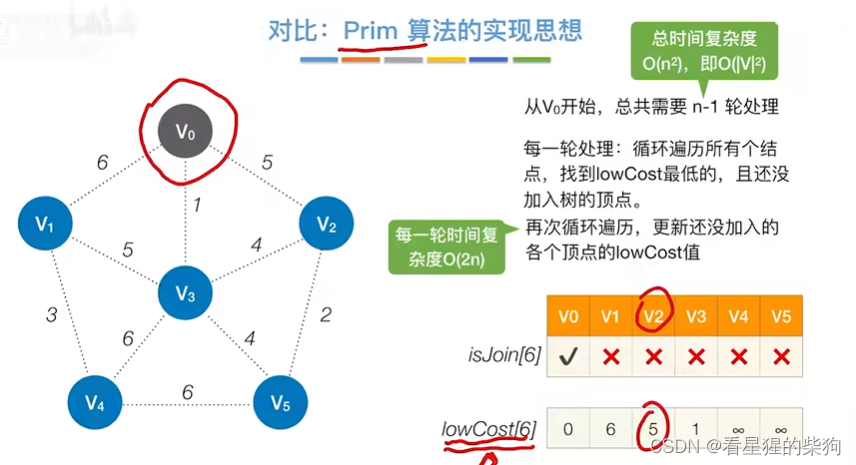
不适用情况

每一对顶点的最短路径问题

Floyd算法
初始时
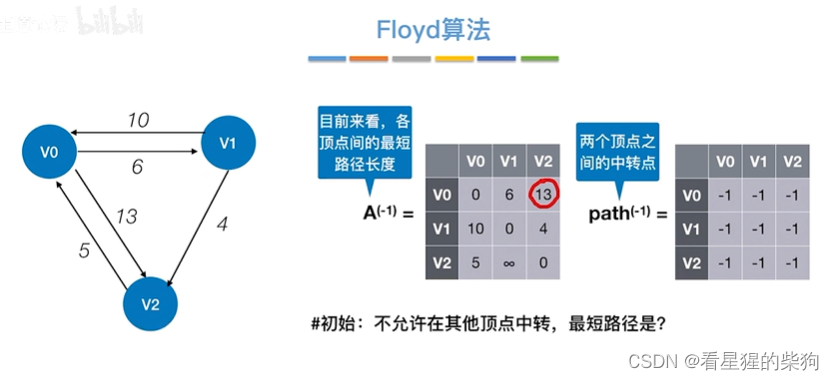
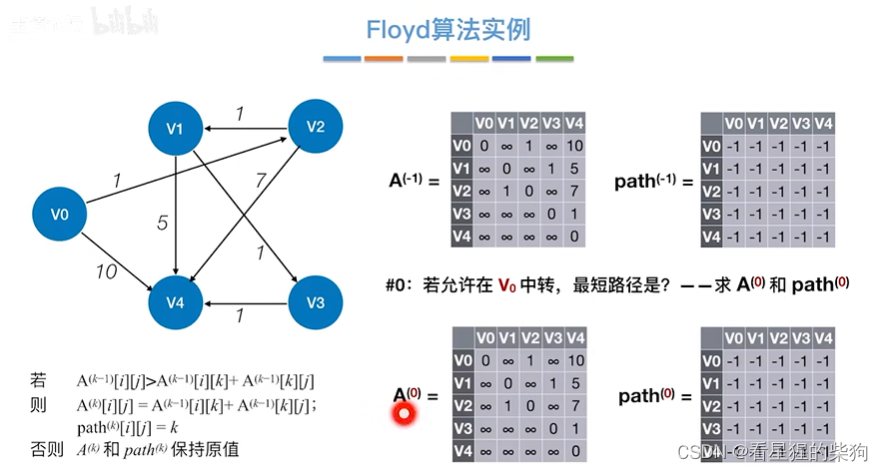
允许在v0中转
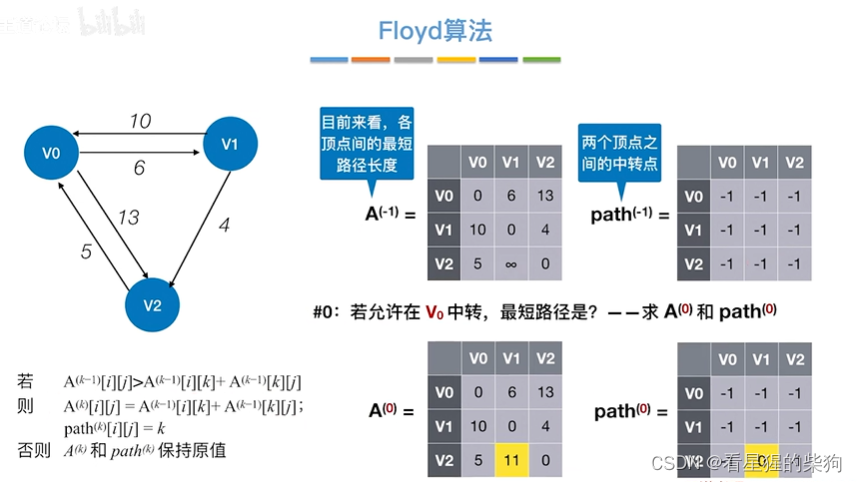
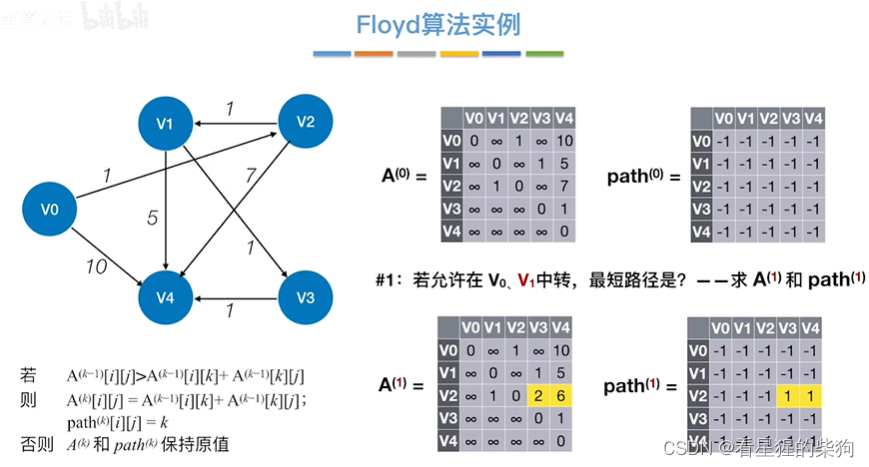
允许在v0 v1中转
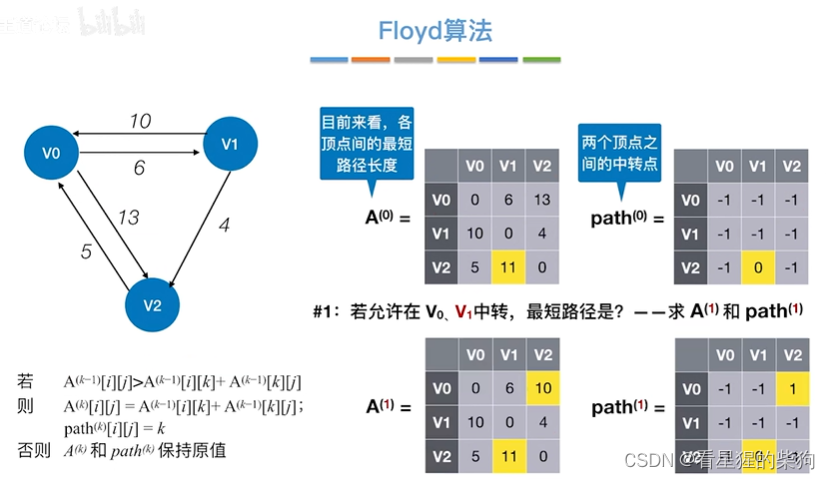
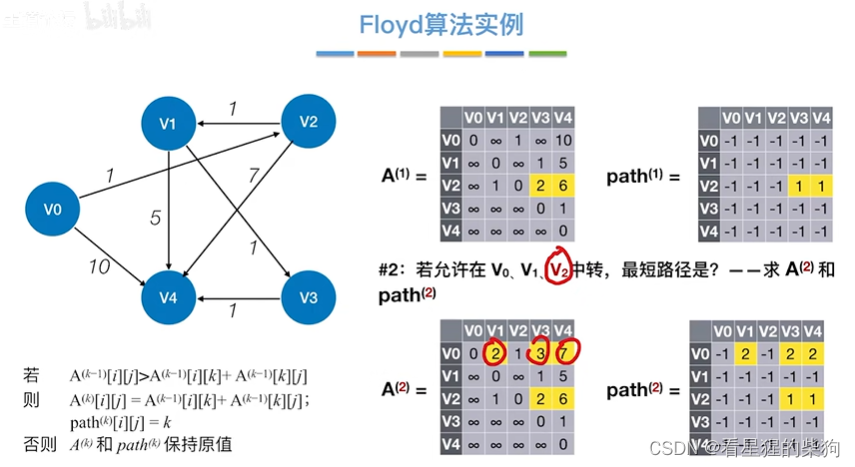
允许在v0 v1 v2中转
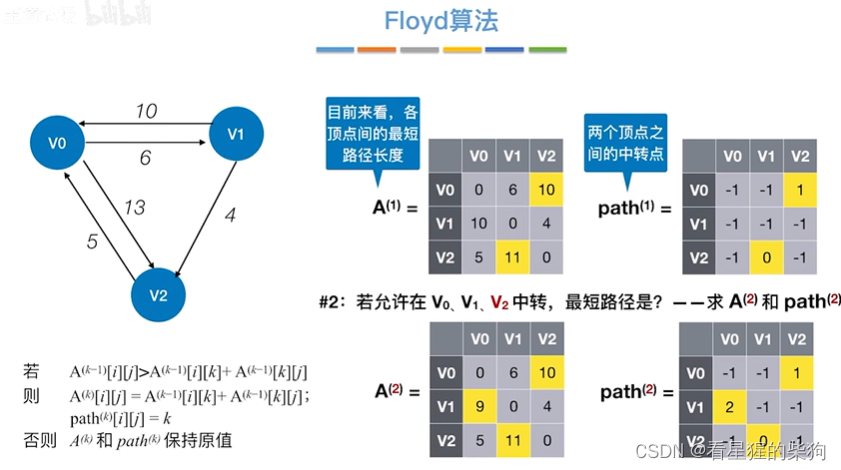
找两个点的最短路径

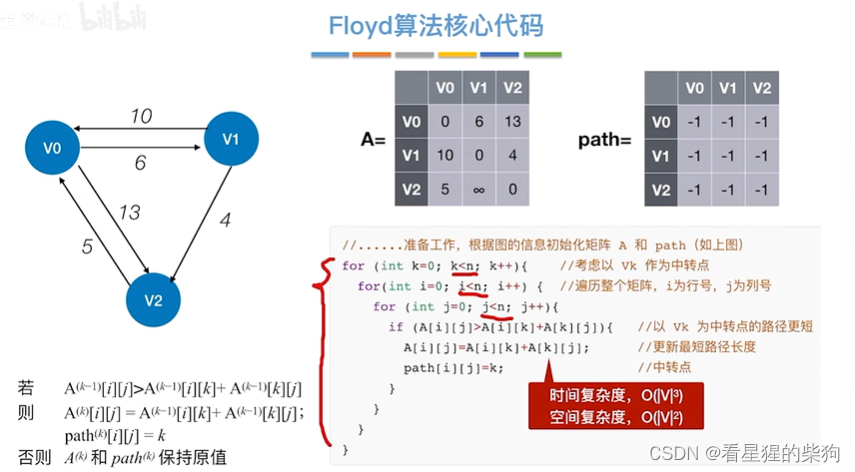
核心代码
空间复杂度是有n*n个矩阵那么多
实例
初始

允许在v0中转
发现没有变化
从图可以发现v0没有进去的边,所以自然没法中转
允许在v0 v1中转
允许在v0 v1 v2中转
是已经基于之前v0 v1的中转结果的
例如v2到v3是基于中转v1的,但是在以v2中转的转换中是把它认为是相连的

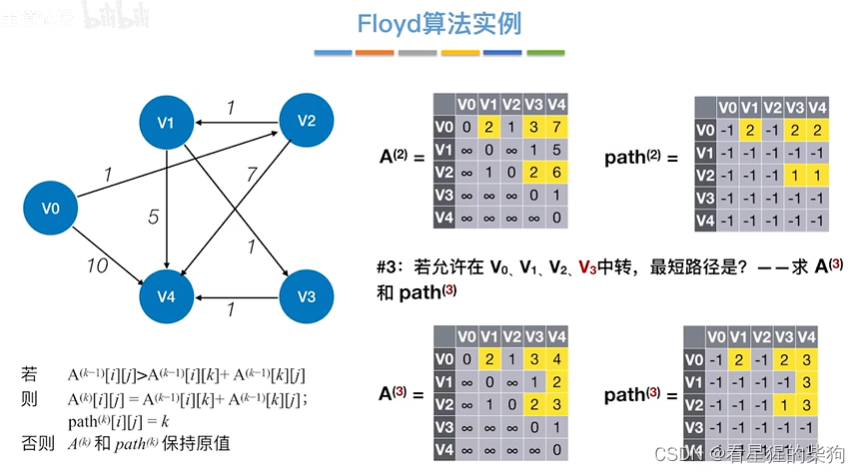
允许在v0 v1 v2 v3中转
允许在v0 v1 v2 v3 v4中转
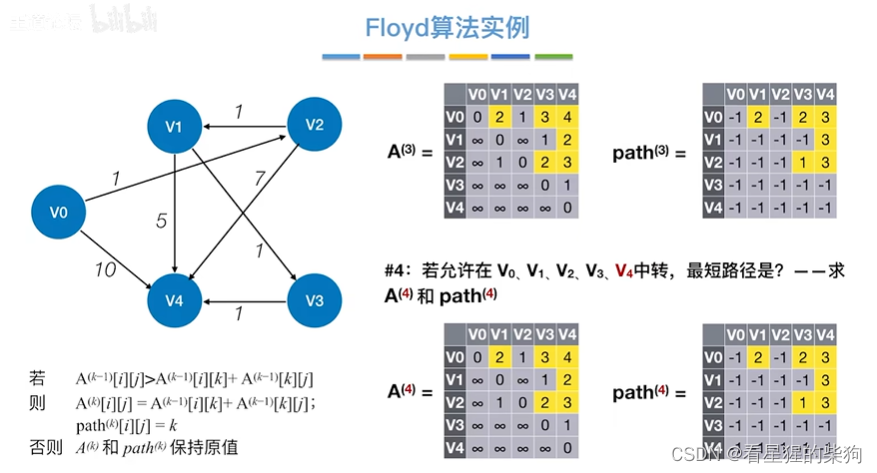
找两个顶点最短路径
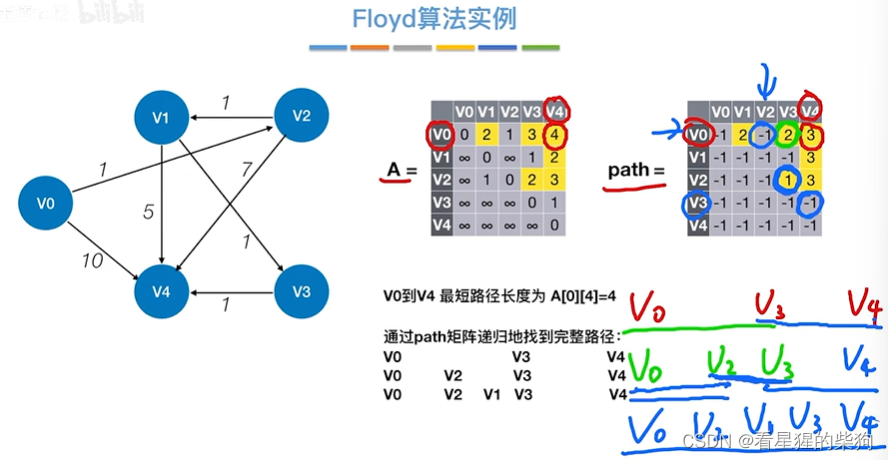
Floyd用于负权图
不能解决的问题
回路越多,路径越短
小结
BFS 采用邻接矩阵是V的平方 邻接矩阵是V+E