网站建设和连接器区公司名字网店推广方案
目录
一.修炼必备
二. 整型提升
三.实用调式技巧
一.修炼必备
1.入门必备:VS2019社区版,下载地址:Visual Studio 较旧的下载 - 2019、2017、2015 和以前的版本 (microsoft.com)
2.趁手武器:印象笔记/有道云笔记
3.修炼秘籍:牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网 (nowcoder.com)
4.雷劫必备:leetcode 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
注:遇到瓶颈怎么办?百度百科_全球领先的中文百科全书 (baidu.com)
二. 整型提升
1.什么是整型提升?
——C语言是整型算术运算总数以缺省整型精度运算的,为了得到这个精度,我们需要把短整型和字符型的数据在使用之前转换为普通整型。
2.整型提升的意义?
——表达式的整型运算要在CPU的相应运算器件内执行,CPU内的整型运算器的操作数的字节长度一般就是int的字节长度,同时也是CPU的通用寄存器的长度;通用CPU是难以实现两个8比特位的数进行计算的,所有,表达式中小于int长度的整型值,万能均要把它转化为int的长度来进行计算,最后进行截断
3.整型提升的范围
——char、short自身类型的值进行混合运算的时候会进行整型提升
4.整型提升发生在什么时候?
——整型提升是按照变量的数据类型的符号位来提升的
1)负整数进行整型提升的时候,补1
2)正整数进行整型提升的时候,补0
3)无符号数进行整型提升的时候,补0
5.几个小case快速上手整型提升
1)case 1:
#include <stdio.h>int main()
{char a = 0xb6;//10110110//11111111 11111111 11111111 10110110 整型提升//10110110 截断//10110101//11001010 原码 : -74//打印查看结果printf("%d\n", a);//-74short b = 0xb600;//10110110 00000000 原码//11111111 11111111 10110110 00000000 --> 整型提升//10110110 00000000 截断//10110101 11111111//11001010 00000000 原码:-18944//打印查看结果printf("%d\n", b);//-18944int c = 0xb6000000;if (a == 0xb6){printf("a\n");}if (b == 0xb600){printf("b\n");}if (c == 0xb6000000){printf("c\n");//c}return 0;
}2)case 2:
#include <stdio.h>
int main()
{char c = 0;printf("%u\n", sizeof(c));//1//注:只要进行运算,那就会发生整型提升printf("%u\n", sizeof(+c));//4printf("%u\n", sizeof(-c));//4return 0;
}3)case 3:
#include <stdio.h>int main()
{char a = 3;//00000101char b = 127;//01111111char c = a + b;//注:在运算的时候才会出现整型提升,写在上面是为了方便//00000011 : 3//01111111 : 127//10000010 结果//11111111 11111111 11111111 10000010//10000010 截断//10000001//11111110 -126printf("%d\n", c); //-126return 0;
}三.实用调式技巧
1.什么是bug?
——bug就是指程序中出现的错误,有很多bug的程序不是优秀的程序,我们应该把自己的程序的bug降低到可控范围内
2.有那些bug?
1)编译性错误,这种类型的bug编译器能给出提示,按照编译器的提示解决问题即可

2)连接性错误,这种错误一般是标识符名字拼写错误或标识符不存在
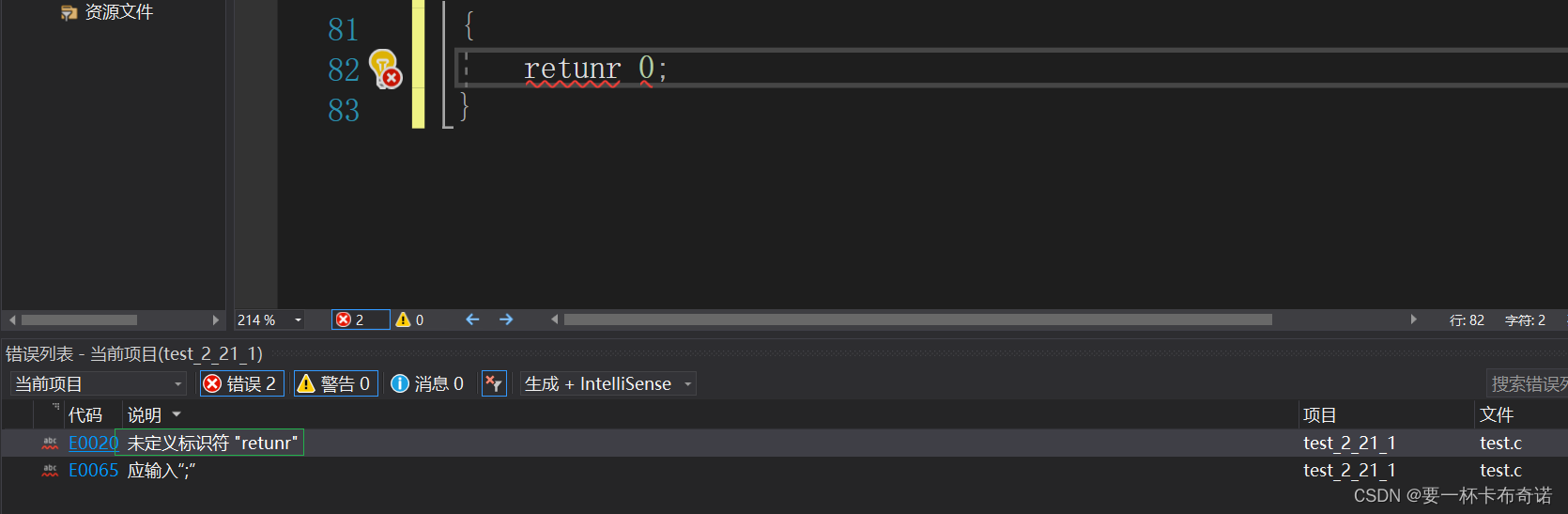
3)运行时的bug,这种bug编译器一般不会给出提示,需要我们自己去查找(最难)
3.为什么需要调式?
——因为有一些bug编译器不能明显的给出提示,这个时候我们就需要通过调试去查找bug
4.如何进行调式?
1)发现程序错误的存在
2)以隔离、消除等方式对错误进行定位
3)确定错误产生的原因
4)提出错误的纠正方法
5)对程序给予改正,再重新测试
5.调式的快捷键
1)F10:逐过程调式(该过程可以是一个函数或一条语句)
2)F11:逐行调式(会进入方法的内部进行调式)
3)F9:创建断点和取消断点
4)F5:开始调式,会直接跳到有断点的地方(和F9搭配使用)
6.tips
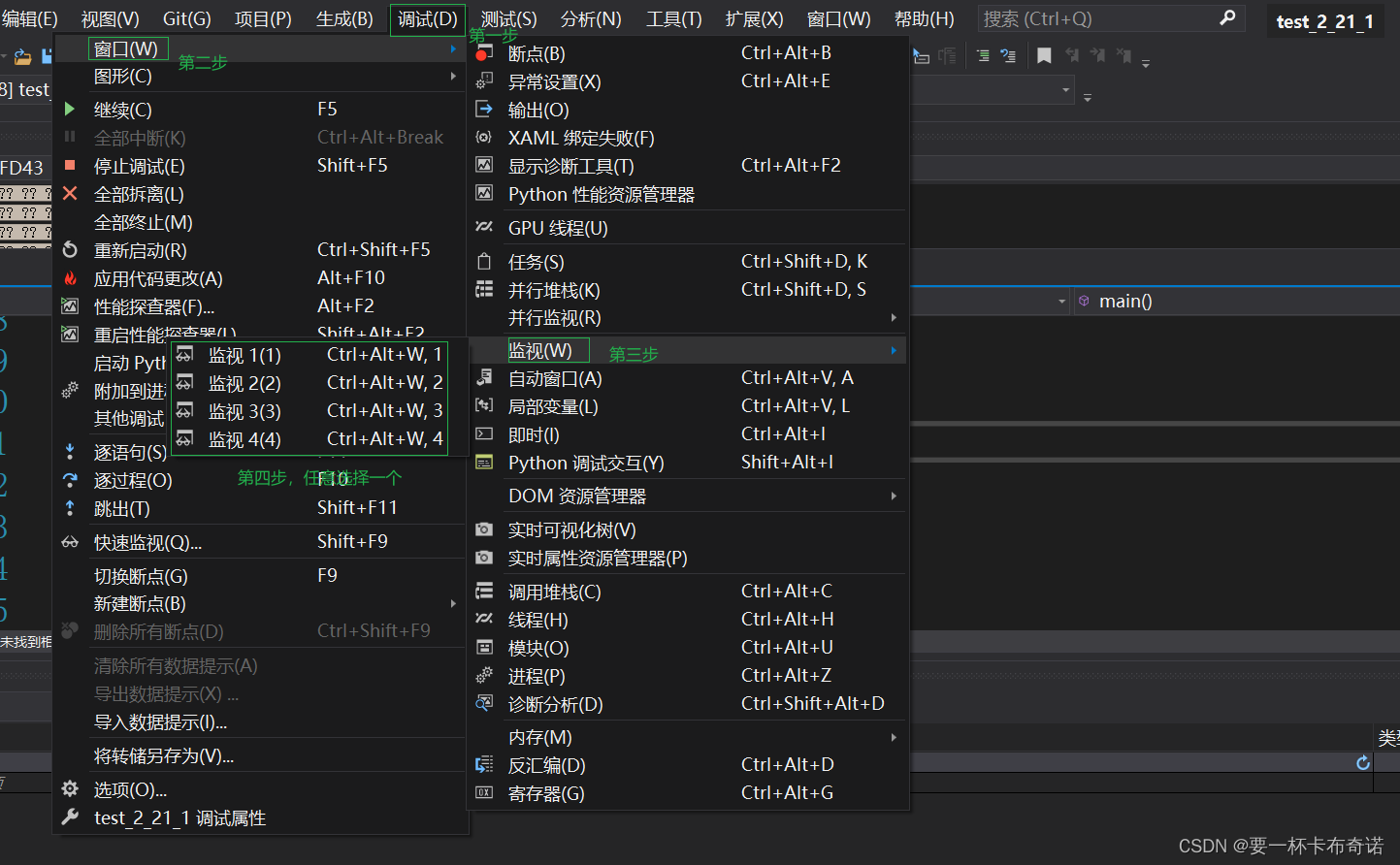
1)调试过程中查看变量
——点击调式、窗口、监视、然后随便选择一个监视

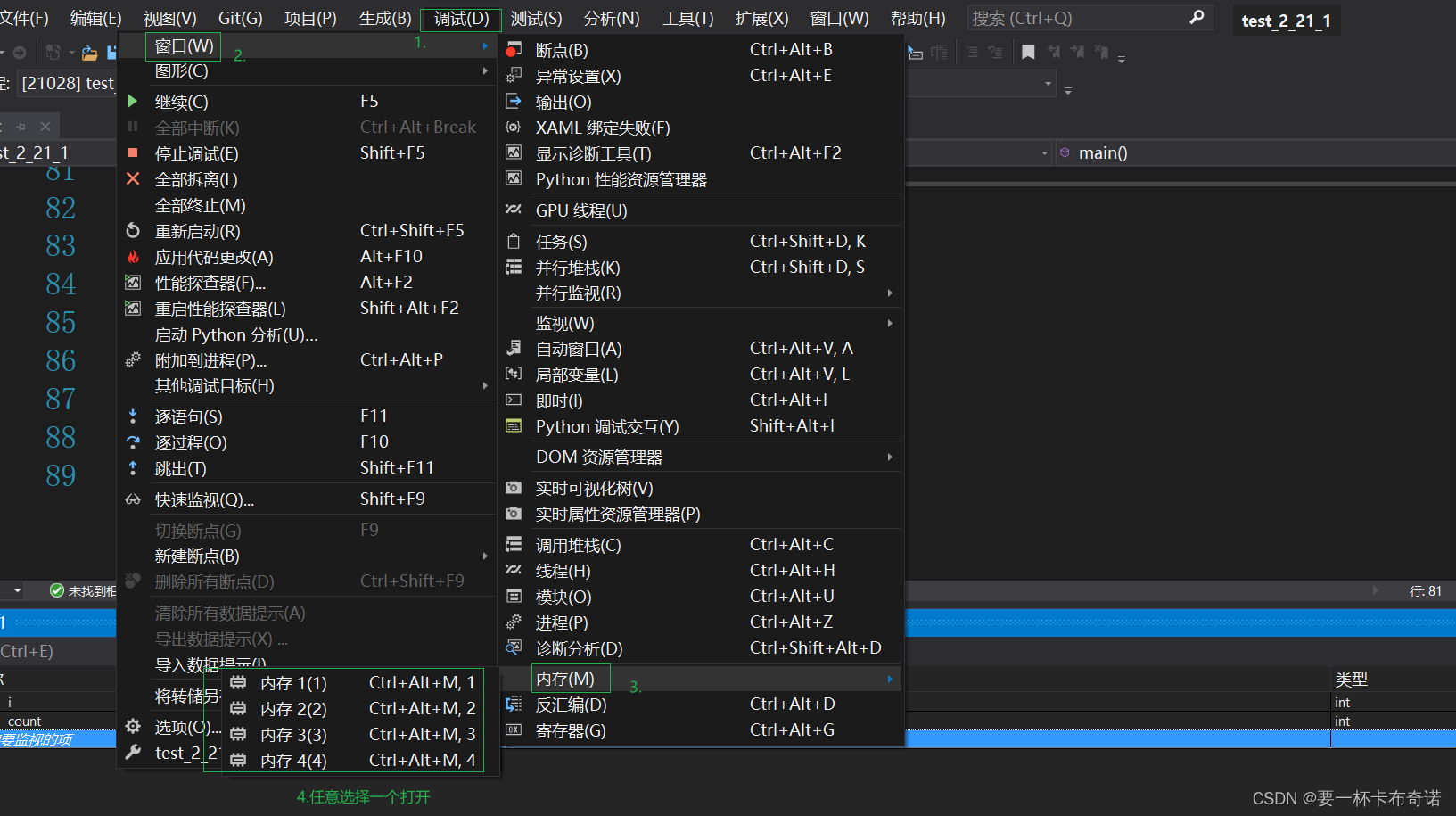
2)查看变量的内存信息
——调式、窗口、内存、选择任意一个内存打开

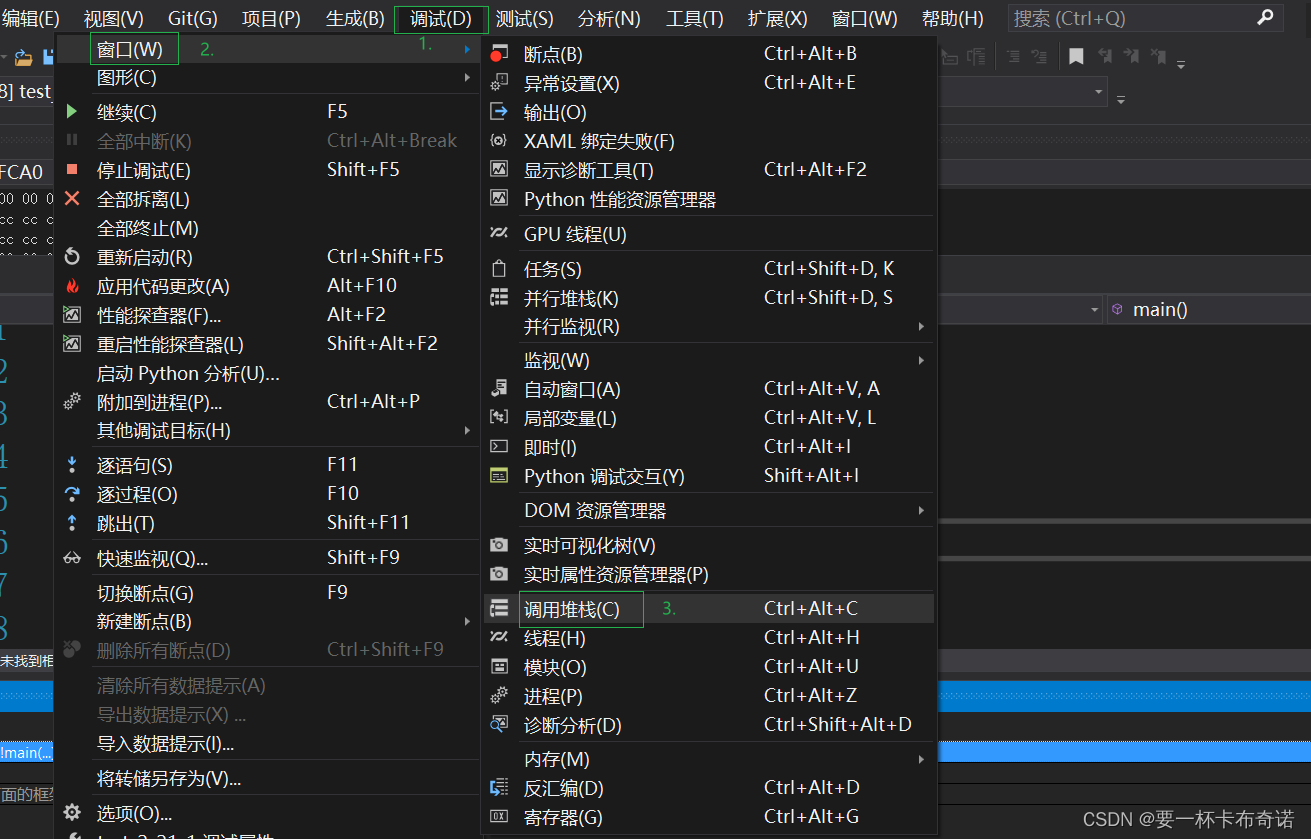
3)调用堆栈
——通过调用堆栈,清晰的看出函数之间调用的关系以及当前调用所处位置
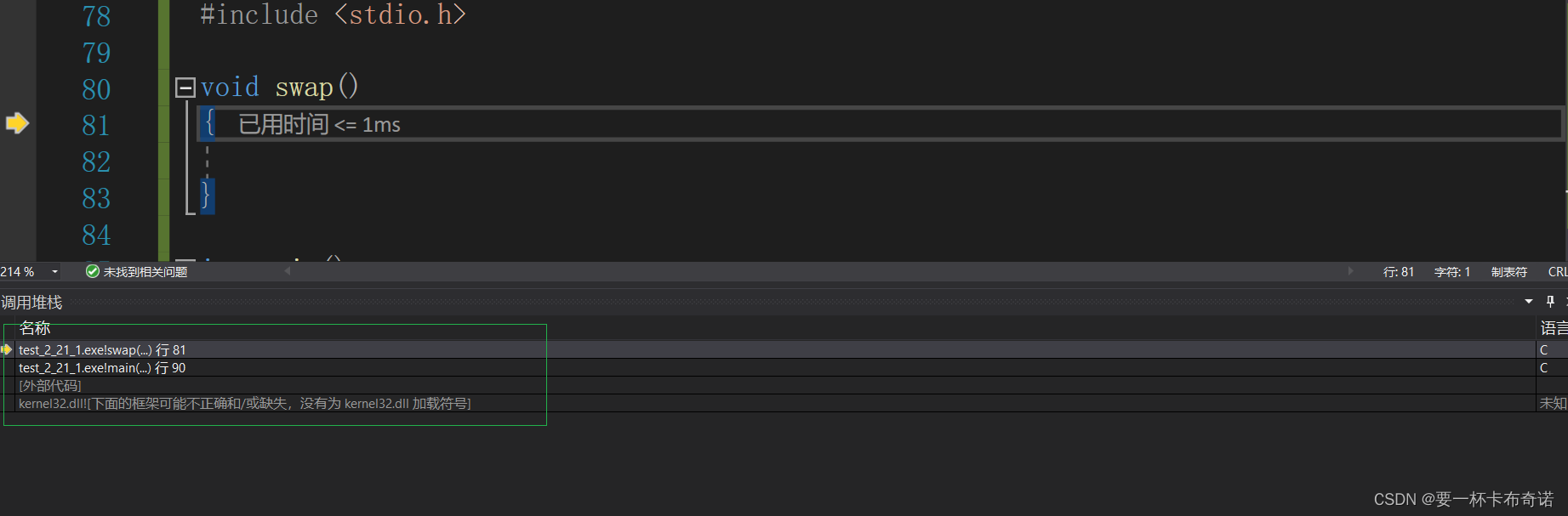 7.调式以下代码,说出问题所在
7.调式以下代码,说出问题所在
case 1:求出1-10的阶乘
#include <stdio.h>
int main()
{int i = 0;int sum = 0;//保存最终结果int n = 0;int ret = 1;//保存n的阶乘scanf("%d", &n);for (i = 1; i <= n; i++){int j = 0;for (j = 1; j <= i; j++){ret *= j;}sum += ret;}printf("%d\n", sum);return 0;
}case 2:说出死循环的原因
#include <stdio.h>
int main()
{int i = 0;int arr[10] = { 0 };//在VS2019中,栈中会留出两个int的空间//i和arr[12]占用了同一个内存空间,所有arr[12]的改变影响了ifor (i = 0; i <= 12; i++){arr[i] = 0;printf("hehe\n");}return 0;
}8.怎样写出优秀的代码
1)使用assert
2)在值不改变的情况下使用const
3)养成良好的编程风格
4)添加必要的注释
5)要注意编码的陷阱
9.模拟实现strlen函数求字符串
#include <stdio.h>
#include <string.h>
#include <assert.h>//加const是为了防止不小心修改了arr
int my_strlen(const char* arr)
{assert(arr);//防止arr是NULLint count = 0;while (*arr++ != '\0'){count++;}return count;
}int main()
{char arr[100] = "husdghfjgfghkshf";//int len = strlen(arr);//printf("%d\n", len);//16int len = my_strlen(arr);printf("%d", len);return 0;
}!!!恭喜你,突破至筑基六层!!!
注:由于CSDN排版问题,想要美观的文章阅读,请前往有道云阅读:有道云笔记