用php做医药网站开题报告网页设计与网站建设案例课堂
目录
1、网关介绍
2、搭建网关服务
3、路由断言工厂
4、路由过滤器
5、全局过滤器GlobalFilter
6、过滤器执行顺序
7、跨域问题处理
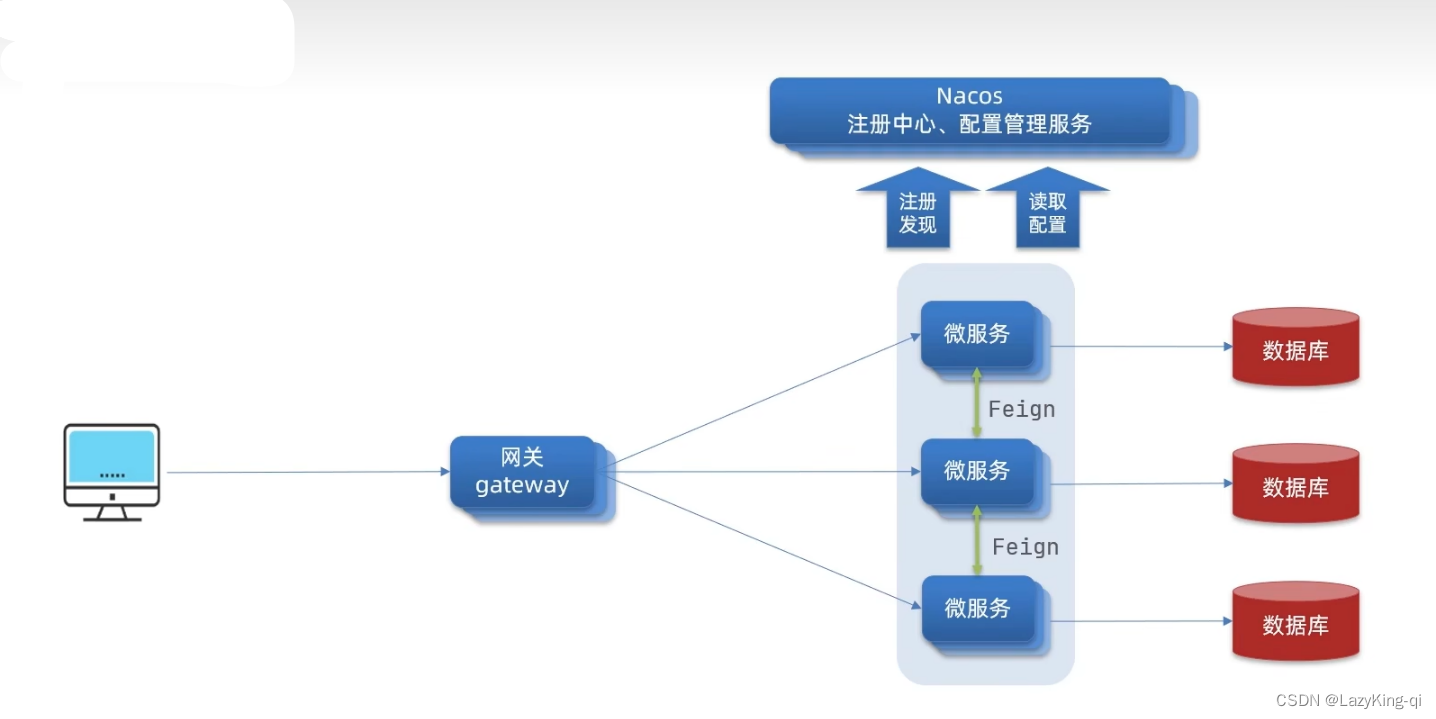
1、网关介绍
网关(Gateway)又称网间连接器、协议转换器。网关在网络层以上实现网络互连,是复杂的网络互
连设备,仅用于两个高层协议不同的网络互连。网关既可以用于广域网互连,也可以用于局域网互
连。网关是一种充当转换重任的计算机系统或设备。使用在不同的通信协议、数据格式或语言,甚
至体系结构完全不同的两种系统之间,网关是一个翻译器。与网桥只是简单地传达信息不同,网关
对收到的信息要重新打包,以适应目的系统的需求。同层--应用层。
网关功能:
1、身份认证和权限校验
2、服务路由、负载均衡
3、请求限流
网关的技术实现
在SpringCloud中网关的实现包括两种:
1、gateway
2、zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的
WebFlux,属于响应式编程的实现,具备更好的性能。
2、搭建网关服务
1、新建一个模块,引入依赖
<!--nacos服务注册发现依赖--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--网关gateway依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency>2、编写路由配置
server:port: 10010
spring:application:name: gatewaycloud:nacos:server-addr: nacos:8848 # nacos地址gateway:routes:- id: user-service # 路由标示,必须唯一uri: lb://userservice # 路由的目标地址predicates: # 路由断言,判断请求是否符合规则- Path=/user/** # 路径断言,判断路径是否是以/user开头,如果是则符合3、启动服务
网关实现方式:
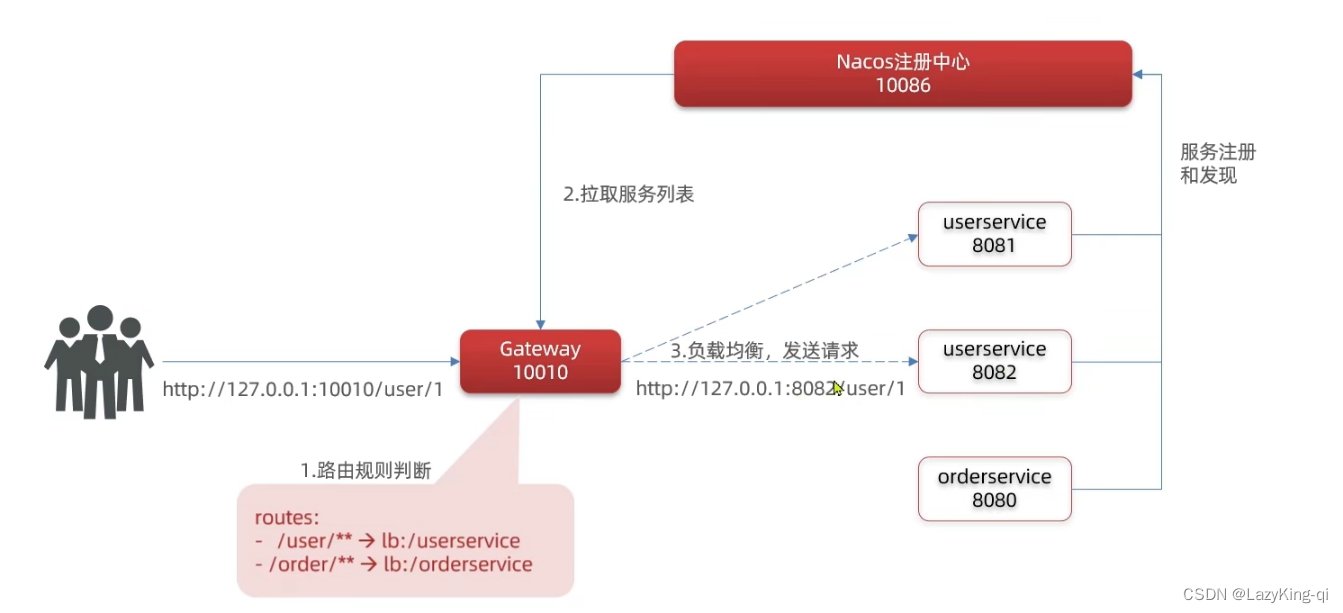
总结:
网关搭建步骤
1.创建项目,引入nacos服务发现和gateway依赖
2.配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
1.路由id:路由的唯一标示
2.路由目标(uri) :路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
3.路由断言( predicates) :判断路由的规则
4.路由过滤器( filters) :对请求或响应做处理
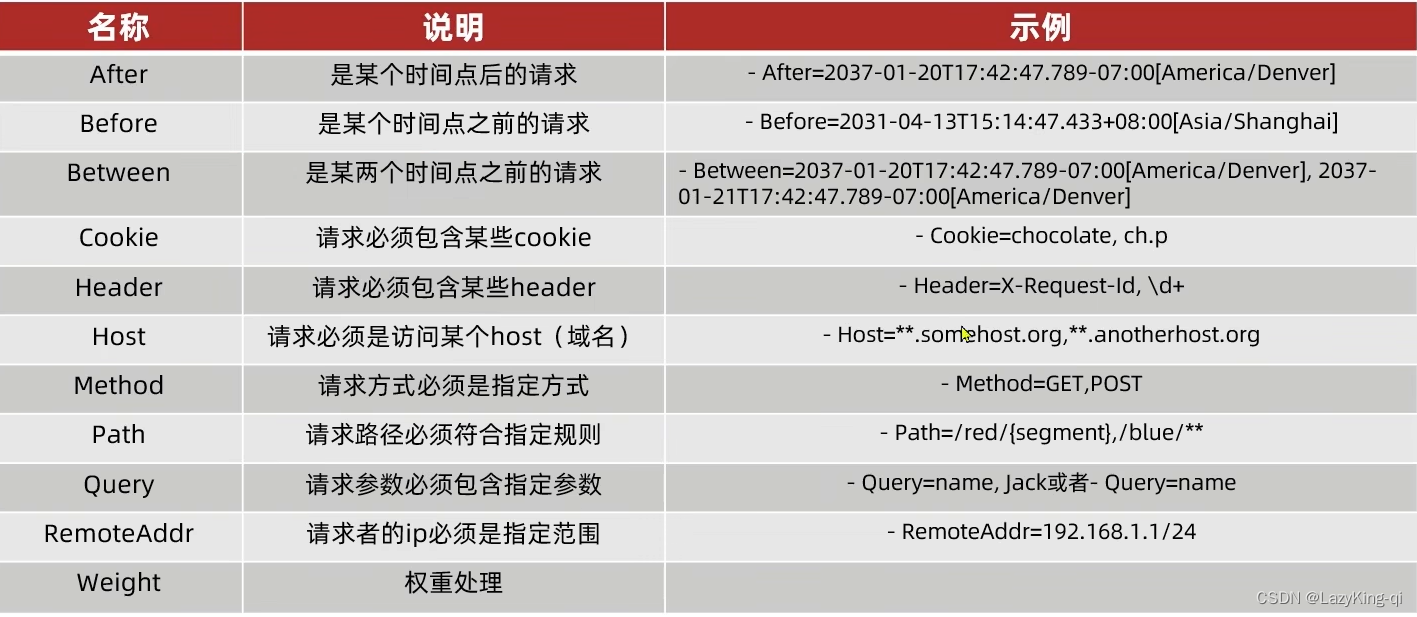
3、路由断言工厂
我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变
为路由判断的条件 例如Path=/user/**是按照路径匹配,这个规则是由
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来处理的
Spring提供了11种基本的Predicate工厂
4、路由过滤器
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理: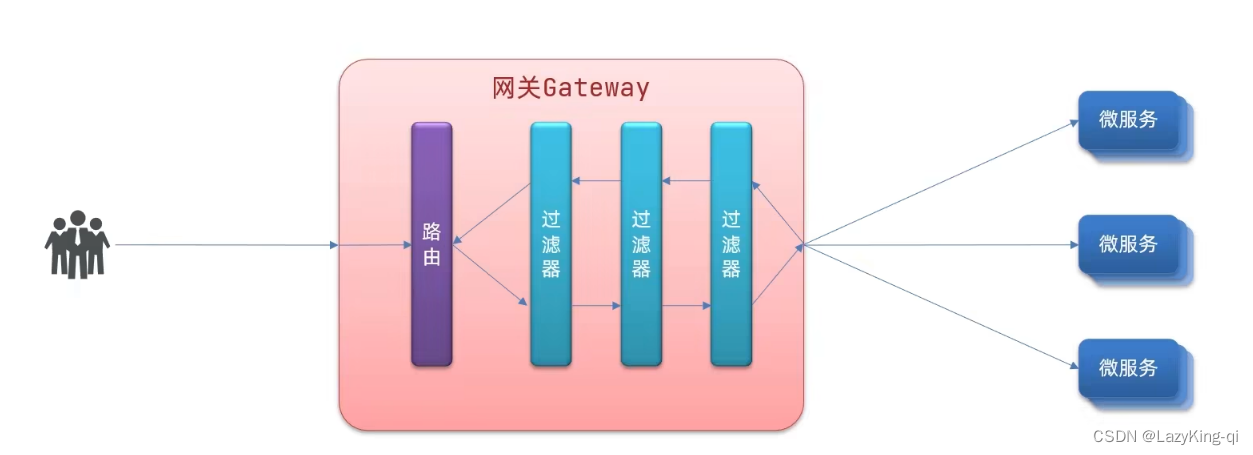
Spring提供了31种不同的路由过滤器工厂。例如:
| 名称 | 说明 |
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
| .............. | ..................... |
例如:给请求头添加一个请求
单个路由生效
所有路由生效

总结:
过滤器的作用是什么?
对路由的请求或响应做加工处理,比如添加请求头
配置在路由下的过滤器只对当前路由的请求生效
defaultFilters的作用是什么?
对所有路由都生效的过滤器
5、全局过滤器GlobalFilter
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。
区别在于GatewayFilter通过配置定义,处理逻辑是固定的。而GlobalFilter的逻辑需要自己写代码
实现。定义方式是实现GlobalFilter接口。

示例:自定义过滤器
@Order(-1) //设置优先级
@Component
public class AuthorizeFilter implements GlobalFilter {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 1.获取请求参数ServerHttpRequest request = exchange.getRequest();MultiValueMap<String, String> params = request.getQueryParams();// 2.获取参数中的 authorization 参数String auth = params.getFirst("authorization");// 3.判断参数值是否等于 adminif ("admin".equals(auth)) {// 4.是,放行return chain.filter(exchange);}// 5.否,拦截// 5.1.设置状态码exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);// 5.2.拦截请求return exchange.getResponse().setComplete();}
}总结:
全局过滤器的作用是什么?
对所有路由都生效的过滤器,并且可以自定义处理逻辑
实现全局过滤器的步骤?
实现GlobalFilter接口
添加@Order注解或实现Ordered接口
编写处理逻辑
6、过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)
中,排序后依次执行每个讨滤器
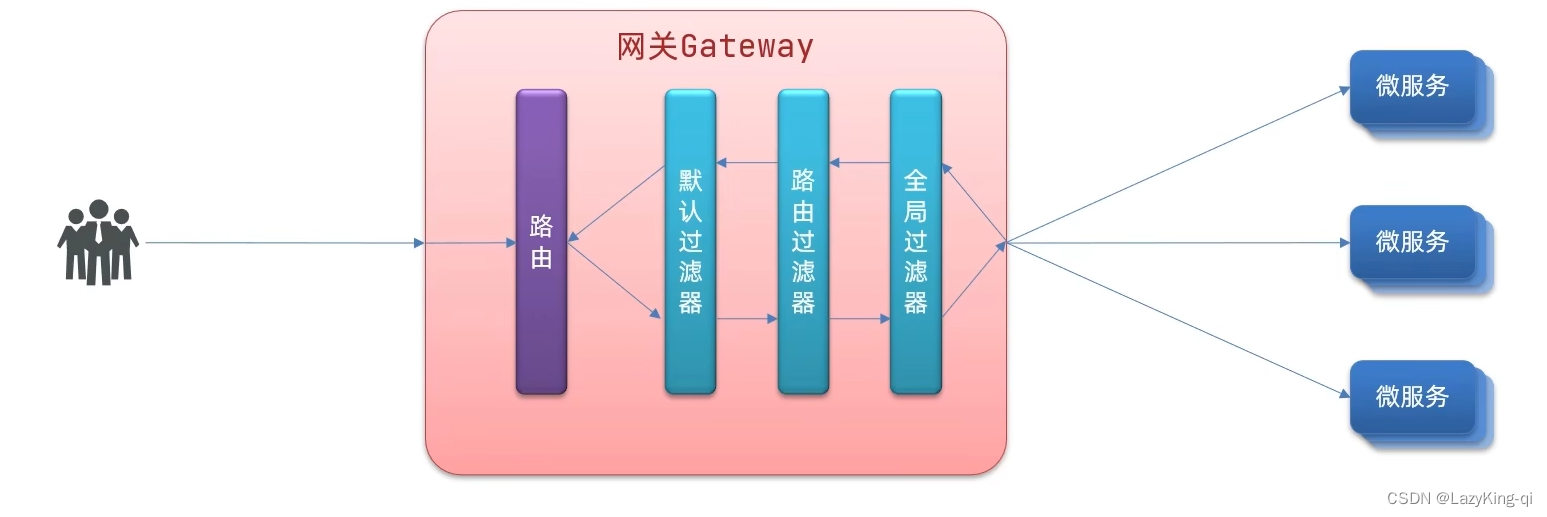
每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
当过滤器的order值一样时,会按照defaultFilter >路由过滤器>GlobalFilter的顺序执行。
可以参考下面几个类的源码来查看:

总结:
路由过滤器、defaultFilter、全局过滤器的执行顺序?
1、order值越小,优先级越高
2、当order值一样时,顺序是defaultFilter最先,然后是局部的路由过滤器,最后是全局过滤器
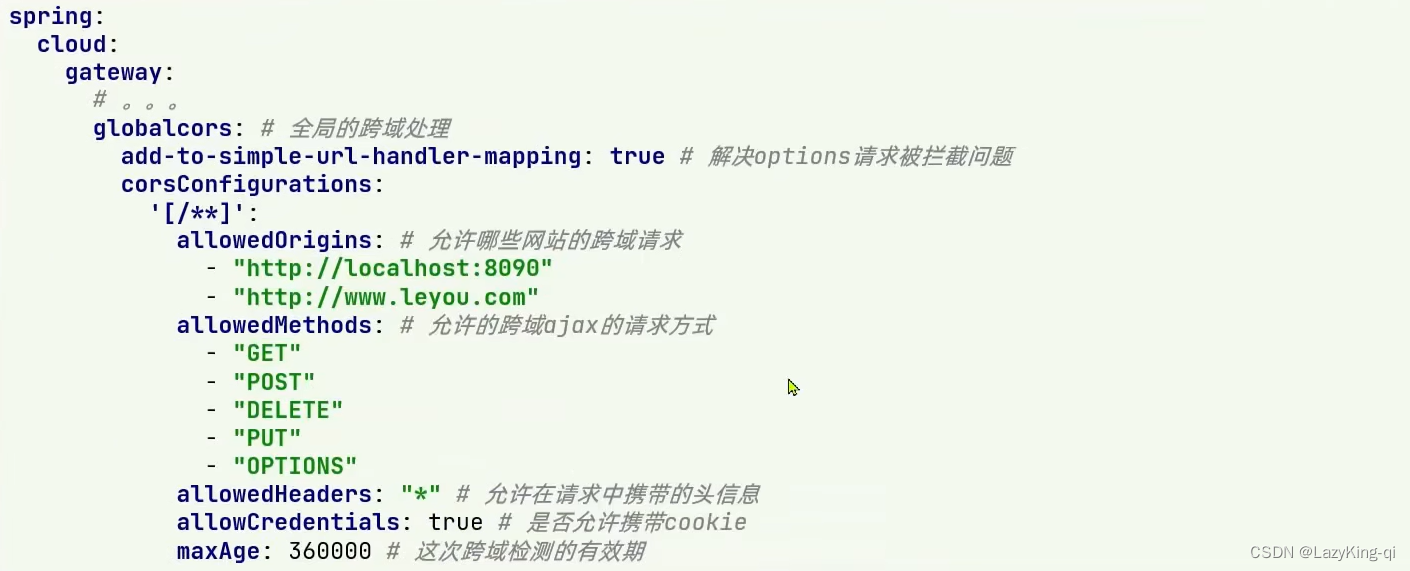
7、跨域问题处理
跨域:域名不一致就是跨域,主要包括:
1、域名不同: www.taobao.com和www.taobao.org和www.jd.com和miaosha.jd.com·
2、域名相同,端口不同: localhost:8080和localhost8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
解决方案:CORS
配置yml文件