禅城网站制作花园设计网站推荐
文章目录
- 1 创建java类
- 2 生成JNI头文件
- 3 使用visual studio2022创建DLL项目
- 3.1 选择模板中(Windows桌面向导)
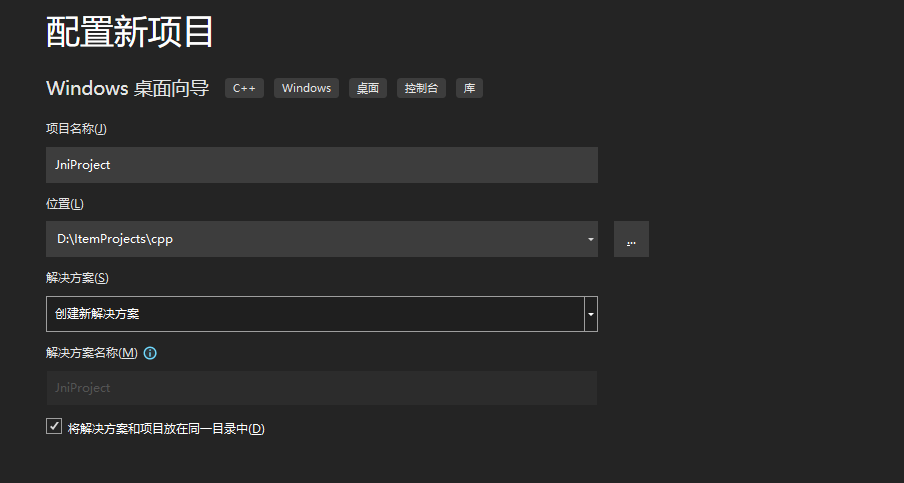
- 3.2 为项目命名
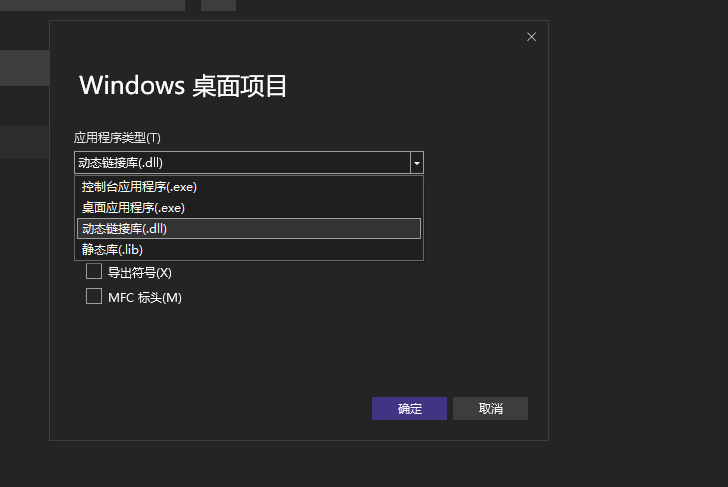
- 3.3 选择应用程序类型为动态链接库
- 3.4 项目概览
- 4 导入需要的头文件
- 4.1 导入需要的头文件
- 4.2 修改头文件
- 5 编写C++实现
- 6 生成dll文件
- 7 在java中进行测试
1 创建java类
使用idea创建一个maven项目,名为jni-demo,并创建一个类JniTest:
package com.example;public class JniTest {public native void printExt();}
整体结构如下:

2 生成JNI头文件
利用java类生成C头文件,命令如下,注意要在包的根路径执行,也就是src\main\java目录下:
javah -classpath . -jni com.example.JniTest
-
如果文件中有中文,需要指定格式,如格式为UTF-8 需要添加
-encoding UTF-8 -
参数解析:
-classpath [class]指定类的路径
-jni [类名]需要生成的类名称,注意不带.java
执行后生成了如下头文件com_example_JniTest.h:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class com_example_JniTest */#ifndef _Included_com_example_JniTest
#define _Included_com_example_JniTest
#ifdef __cplusplus
extern "C" {
#endif
/** Class: com_example_JniTest* Method: printExt* Signature: ()V*/
JNIEXPORT void JNICALL Java_com_example_JniTest_printExt(JNIEnv *, jobject);#ifdef __cplusplus
}
#endif
#endif
3 使用visual studio2022创建DLL项目
3.1 选择模板中(Windows桌面向导)
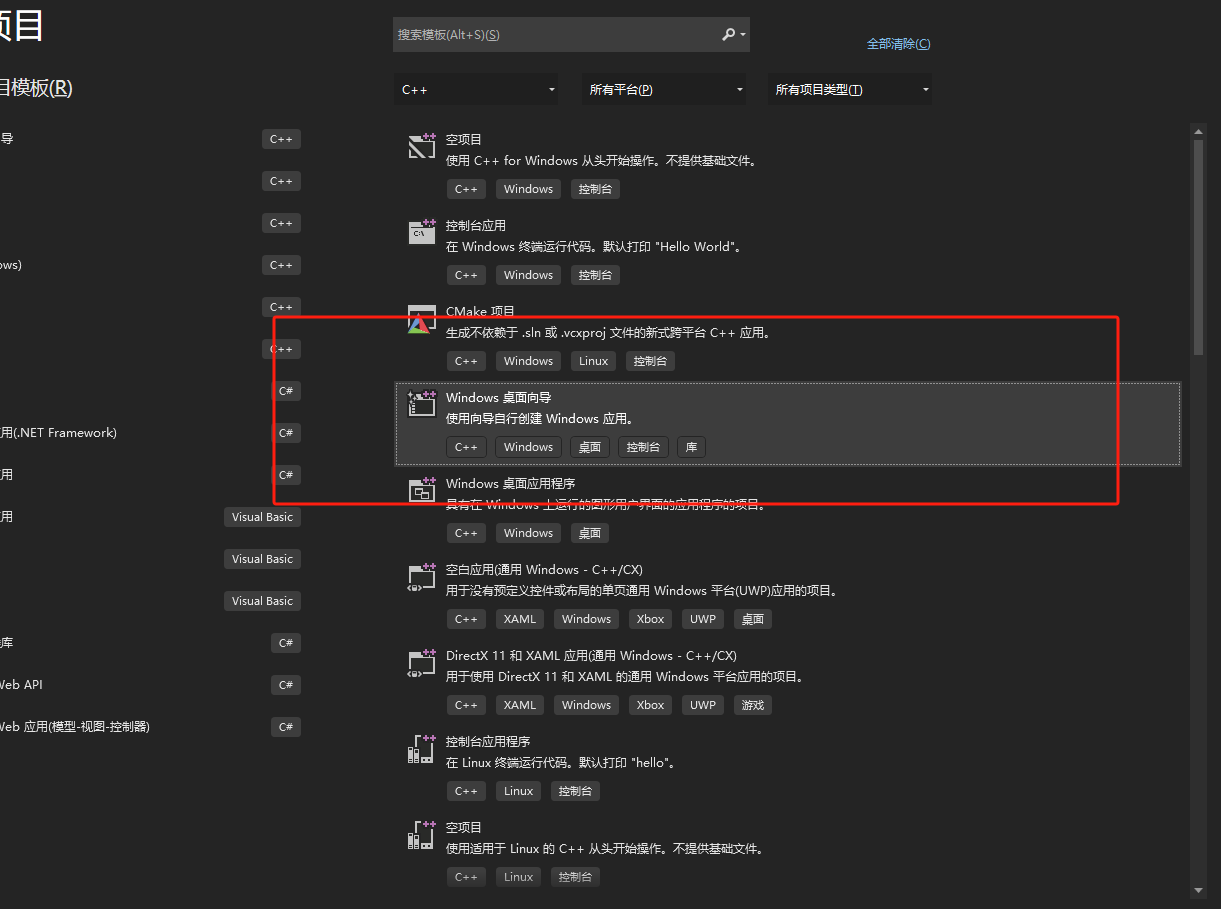
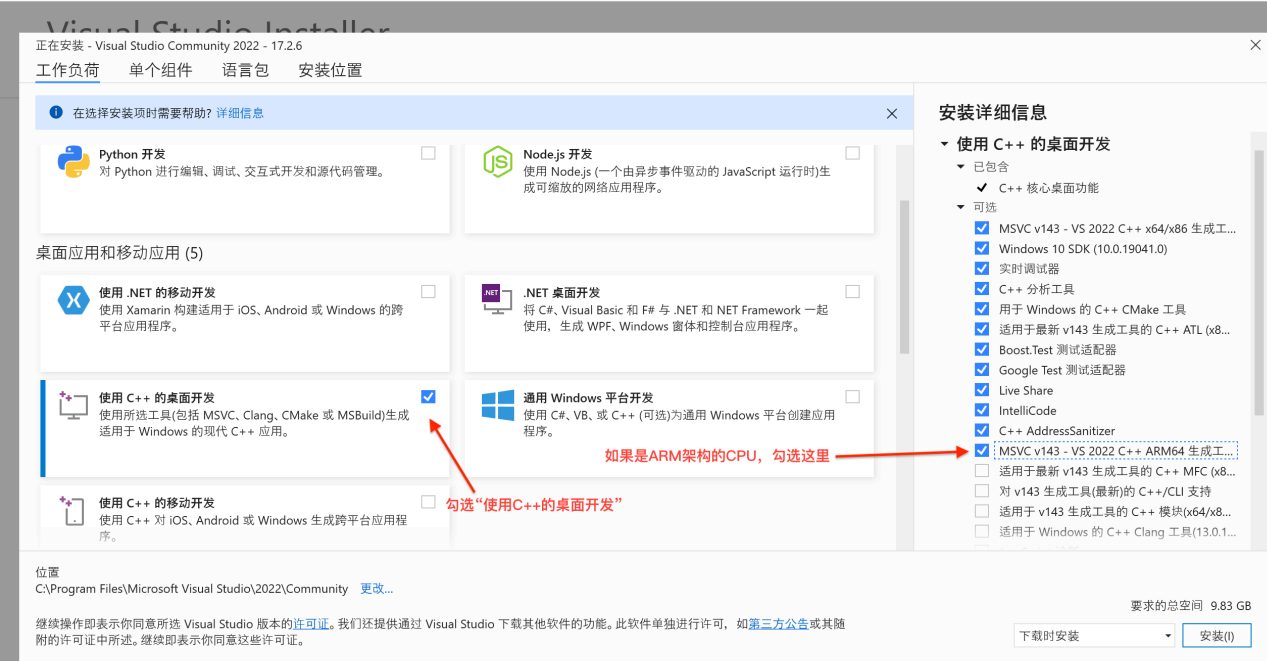
如果没有这个模板则安装:
3.2 为项目命名
3.3 选择应用程序类型为动态链接库
3.4 项目概览
4 导入需要的头文件
4.1 导入需要的头文件
将第二步生成的com_example_JniTest.h文件、JDK目录的include目录下有一个jni.h文件、和JDK目录下的\include\win32下的jni_md.h文件复制到visual studio2022创建的项目中,如下:
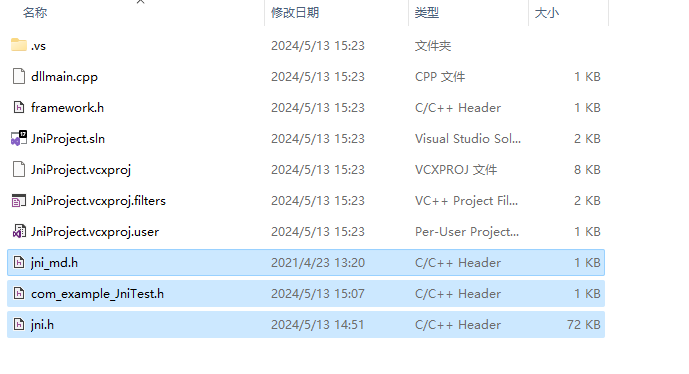
然后在visual studio2022中点击头文件->添加->现有项,找到上述三个头文件,添加即可。
4.2 修改头文件
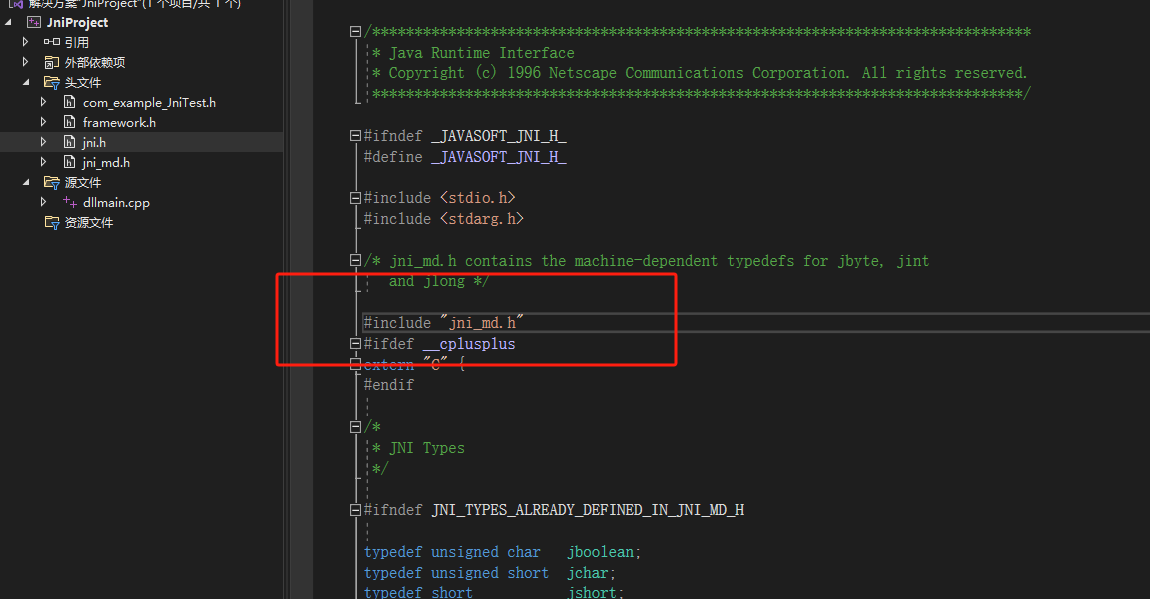
找到jni.h文件中#include <jni_md.h>修改为#include "jni_md.h",如下:
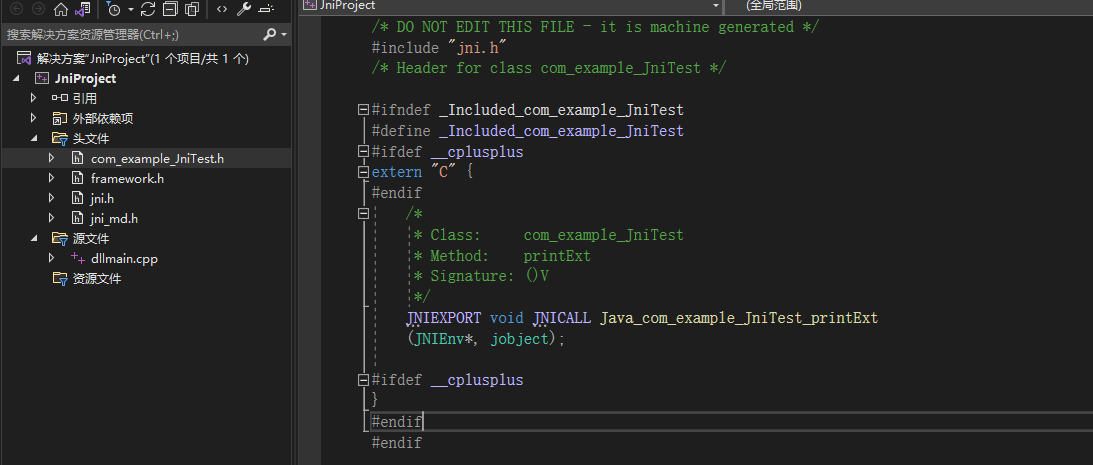
找到com_example_JniTest.h文件中#include <jni.h>修改为#include "jni.h"",如下:
5 编写C++实现
在visual studio2022中点击源文件->添加->新建项,选择C++文件,命名为MyJinCpp.cpp,然后在MyJinCpp.cpp编写如下内容:
#pragma execution_character_set("utf-8")//设置字符编码,不然java中显示乱码
#include "com_example_JniTest.h"
#include <iostream>
using namespace std;//引入命名空间std,使得std::cout和std::endl可以直接省去std::JNIEXPORT void JNICALL Java_com_example_JniTest_printExt
(JNIEnv*, jobject) {cout << "现在你正在调用c++的实现" << endl;
}
6 生成dll文件
在visual studio2022中右键点击生成,输出会显示一个dll的地址,复制这个地址,接下来java要用:
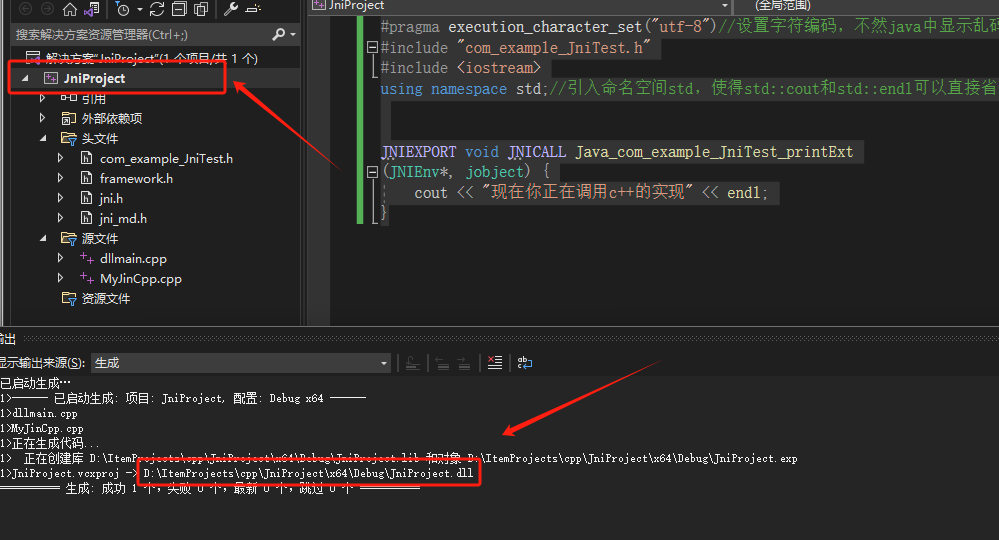
7 在java中进行测试
修改Main类,如下:
注意:
- 使用
System.load直接加载任意位置的动态链接库,需要指定全路径以及扩展名 - 使用
System.loadLibrary加载java.library.path这一jvm变量所指向的路径中位置的动态链接库,不需要指定全路径以及扩展名可以通过System.getProperty("java.library.path")方法来获得该变量的值
package com.example;// Press Shift twice to open the Search Everywhere dialog and type `show whitespaces`,
// then press Enter. You can now see whitespace characters in your code.
public class Main {static {System.load("D:\\ItemProjects\\cpp\\JniProject\\x64\\Debug\\JniProject.dll");}public static void main(String[] args) {new JniTest().printExt();}
}
运行结果:
现在你正在调用c++的实现Process finished with exit code 0