网站关键词seo优化怎么做推广怎么做
摘 要
信息化社会内需要与之针对性的信息获取途径,但是途径的扩展基本上为人们所努力的方向,由于站在的角度存在偏差,人们经常能够获得不同类型信息,这也是技术最为难以攻克的课题。针对城市美发管理系统等问题,对城市美发管理系统进行研究分析,然后开发设计出城市美发管理系统以解决问题。
城市美发管理系统主要功能模块包括美发师介绍、服务类型、美发师预约、美发店、美发服务、服务订单,采取面对对象的开发模式进行软件的开发和硬体的架设,能很好的满足实际使用的需求,完善了对应的软体架设以及程序编码的工作,采取MySQL作为后台数据的主要存储单元,采用springboot框架、Java技术、Ajax技术进行业务系统的编码及其开发,实现了本系统的全部功能。本次报告,首先分析了研究的背景、作用、意义,为研究工作的合理性打下了基础。针对城市美发管理系统的各项需求以及技术问题进行分析,证明了系统的必要性和技术可行性,然后对设计系统需要使用的技术软件以及设计思想做了基本的介绍,最后来实现城市美发管理系统和部署运行使用它。
关键词:城市美发管理系统;java;springboot
Abstract
In the information society, there is a need for targeted access to information, but the expansion of access is basically the direction people are striving for. Due to the deviation in perspective, people often can obtain different types of information, which is also the most difficult topic for technology to overcome. Aiming at issues such as urban hairdressing management systems, this paper studies and analyzes urban hairdressing management systems, and then develops and designs urban hairdressing management systems to solve the problems.
The main functional modules of the urban hairdressing management system include hairdresser introduction, service type, hairdresser appointment, hairdressing shop, hairdressing service, and service order. The object-oriented development model is adopted for software development and hardware installation, which can well meet the actual use needs. The corresponding software installation and program coding work are improved. MySQL is used as the main storage unit for background data, and the spring boot framework is adopted Java technology, Ajax technology for business system coding and development, achieving all the functions of the system. This report first analyzes the background, role, and significance of the research, laying a foundation for the rationality of the research work. This article analyzes various requirements and technical issues of the urban hairdressing management system, proves the necessity and technical feasibility of the system, and then makes a basic introduction to the technical software and design ideas needed to design the system. Finally, it realizes the urban hairdressing management system and deploys and runs it.
Key words:Urban hairdressing management system; java; springboot
目录
1 绪论
1.1选题目的
1.2 选题意义
1.3 相关技术介绍
1.4 springboot框架介绍
2城市美发管理系统分析
2.1 可行性分析
2.1.1 技术可行性分析
2.1.2 经济可行性分析
2.2 系统业务流程分析
2.3 系统需求分析
2.3.1 功能性需求分析
2.3.2 非功能性分析
2.4 系统用例分析
3城市美发管理系统总体设计
3.1 系统模块设计
3.2 数据库设计
3.3.1 数据库概念结构设计
3.2.2 数据库逻辑结构设计
4城市美发管理系统设计与实现
4.1 系统首页界面
4.2 注册界面
4.3 登录界面
4.4修改密码界面 20
4.5美发师介绍详情界面 21
4.6美发资讯界面 24
4.7 美发店详情界面 24
4.8系统用户管理界面 25
4.9资源管理界面
4.10模块管理界面
5城市美发管理系统测试
5.1 调试部分问题
5.2 系统测试用例 30
5.3 系统测试结果 31
结论 32
参考文献 33
致 谢 35
1 绪论
随着互联网技术的迅猛发展,各行各业都开始走上信息化建设的道路。通过信息化建设,实现了将公司资产,公司主营业务,人力资源管理,设备台账等等公司资产放到信息平台统筹规划统一管理。信息化,智能化有助于企业管理,是企业市场竞争的助力器。美容美发行业也是社会上发展迅猛的服务行业之一,有大型的美容美发店,面向高端群体,这些美容美发企业一般都有自己较为成熟的企业经营管理系统。但大部分中低级别小规模的理发店美容店管理松散,基本就是小作坊式的经营模式,没有系统化的管理方法,因此,设计并开发一个城市美发管理系统有助于中小规模美发店提高工作效率,并利用该平台提升知名度走进更多消费者的视野中。
1.2选题意义
中小规模的美发店无法在搜索引擎上搜索到,消费者无法查看消费后的点评,因此对于选择店铺存在犹豫不信任等情况。且在这种美发店消费,用户除了通过联系店家进行预约或者到店排队等候之外别无他法。耗时长,体验感差等问题十分突出。因此整合美发店,理发师信息,设计并开发一个城市美发管理系统是非常有必要的。
1.3相关技术介绍
(1)城市美发管理系统中的web后台管理中的后端不再使用古老的jsp+javabean+servlet技术,而是使用当前主流的springboot框架,它减少java配置代码,简化编程代码,目前springboot框架也是很多企业选择的框架之一。
(2)城市美发管理系统中的web后台管理中的前端使用的是bootstrap框架,它配合ajax和jquery可以美化页面设计。
(3)流行vue框架结合jQuery技术,在jQuery基础上扩展一些插件,通过自己定义插件更好的实现前端的设计。
(4)城市美发管理系统中数据库用的mysql5.7,它执行效率高。
2城市美发管理系统分析
通过了解对城市美发管理系统的真实需求后,将城市美发管理系统所需要的角色划分整理成了下图2-1,图2-2和图2-3。
从开发工具来看,由于城市美发管理系统是基于JAVA的,因此有很多开发工具都可以进行开发,这些功能强大的开发工具可以给我来设计城市美发管理系统带来非常大的方便。
从城市美发管理系统的本身技术来说,对于我来开发一个城市美发管理系统这个毕设是不费事的。城市美发管理系统的开发可以简单的分为前台端、后台端开发以及数据库开发。其中的大部分技术难点在我上学时已经使用过了,同时网络上很多技术点可以让我来借鉴。Web后台管理使用JAVA的springboot架构开发,数据库使用mysql,页面上使用javascript脚本,因此为我在开发 城市美发管理系统 这个毕设上省去了很多多余代码,这给我的毕设项目编写带来了极大的便利。综上所述,从技术层面来看开发城市美发管理系统 是可行的。
从用户体验来看,市面上很多被广泛使用的系统案例可以让我来参考,因此我可以综合它们的页面交互设计的优点,基于我的毕设项目特点来进行改版,最后达到令用户满意的页面交互体验。综上所述,从技术层面来看开发城市美发管理系统是可行的。
从城市美发管理系统的开发成本来看,城市美发管理系统的设计和开发都是我自己完成的,没有其他成本上的开销。
从城市美发管理系统的维护成本来看,城市美发管理系统的开发遵循一套完整的代码编写规范,并且城市美发管理系统的结构设计非常灵活,遵循高内聚低耦合的原则,因此易于维护和迭代开发。
在城市美发管理系统上线之后,上线前期我会根据真实需求来调查,对使用我开发的城市美发管理系统来制定一套符合的使用费。系统运行稳定后我会将推广范围到其他的景点当中,其他景点可以使用我的城市美发管理系统,只需要缴纳一点点的定金,我会给他们引入广告投资和自营业务。
综合以上的分析,城市美发管理系统所带来的经济效益将会带来极大的收益。并且随着我的推广,来使用我开发的城市美发管理系统的市场将越来越大,城市美发管理系统带来的利润也就越来越多。因此,从经济层面来看开发城市美发管理系统的是可行的。
2.2系统业务流程分析
用户权限下的工作流程主要为:用户通过系统提供的注册功能,进行身份验证并注册,而后在登录界面进行个人身份验证,并且进入用户的个人后台界面,并进行相应的操作。
城市美发管理系统的业务流程如下图所示。
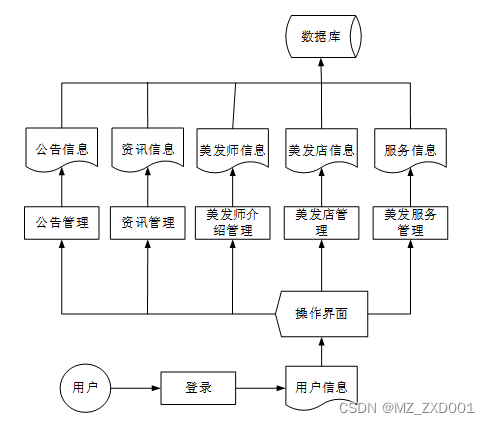
图2-1 系统业务流程图
2.3 系统需求分析
城市美发管理系统从角色上划分为了管理员、美发师以及注册用户三种角色。
管理员角色:
(1)登录:管理员的账号是在数据表表中直接设置生成的,不需要进行注册;
(2)资源管理:当点击“资源管理”这一菜单的时候,会出现美发资讯+资讯分类这两个子菜单,可以对这两个模块进行增删改查操作;
(3)系统用户:当点击“系统用户”这一菜单的时候,会出现管理员+注册用户+美发师这三个子菜单,可以对这三个模块进行增删改查操作;
(4)模块管理:当点击“模块”这一菜单的时候,会出现美发师介绍+服务类型+美发师预约+美发店+美发服务+服务订单这六个子菜单,管理员能够对这六个模块进行增删改查操作;
(5)公告栏:管理员可以对系统前台展示的公告栏进行增删改查,方便用户进行查看。
(6)个人信息:管理员点击“个人信息”按钮,可以对个人的头像、昵称、手机号码等信息进行更新。
(7)修改密码:管理员点击“修改密码”按钮,可以对登录密码进行更改,首先输入原密码,然后再输入新密码和确认密码,当原密码正确,输入两次新密码一致,则修改成功,否则给出错误提示信息。
注册用户角色:
(1)用户注册登录:游客可以随时进入到系统中,对系统中的信息浏览,但是想要实现美发服务以及美发店等操作,就必须有这个系统的账号,如果没有账号的话,可以注册以后进行相关的操作,同时用户还可以通过“我的账户”这以按钮对个人信息以及操作的信息进行管控。
(2)公告消息:在首页导航栏左侧我们会看到“公告消息”这一菜单,我们点击进入进去以后,会看到所有管理员在后台发布的公告信息;
(3)美发资讯:用户可以查看美发资讯信息,在查询到自己想要了解的美发资讯的时候,可以进入查看详细的介绍进行评论、点赞、收藏操作。
(4)个人中心:当用户点击右上角“个人中心”这个按钮,就会进入到对应的后台进行信息的管理了;
(5)我的账户:在前台点击“我的”下面的“我的账户”可以对个人资料+密码修改+自己收藏的信息进行管控。
(6)美发店:用户可以查看美发店信息支持通过搜索关键词的方式对美发店进行查询,在查询到自己想要了解的美发店的时候,可以进入查看详细的介绍。
(7)美发师介绍:用户可以查看美发师介绍,在查询到自己想要了解的美发师介绍的时候,可以进入查看详细的介绍,点击“预约”这一按钮以后会跳转到预约信息填写的界面,根据提示填写好预约的信息,点击“提交”以后预约就完成了,在美发师介绍详情这个界面,同时支持用户对喜欢的美发师介绍进行收藏、点赞的功能。
2.3.2 非功能性分析
城市美发管理系统的非功能性需求比如城市美发管理系统的安全性怎么样,可靠性怎么样,性能怎么样,可拓展性怎么样等。具体可以表示在如下2-1表格中:
表2-1城市美发管理系统非功能需求表
| 安全性 | 主要指城市美发管理系统数据库的安装,数据库的使用和密码的设定必须合乎规范。 |
| 可靠性 | 可靠性是指城市美发管理系统能够安装用户的指示进行操作,经过测试,可靠性90%以上。 |
| 性能 | 性能是影响城市美发管理系统占据市场的必要条件,所以性能最好要佳才好。 |
| 可扩展性 | 比如数据库预留多个属性,比如接口的使用等确保了系统的非功能性需求。 |
| 易用性 | 用户只要跟着城市美发管理系统的页面展示内容进行操作,就可以了。 |
| 可维护性 | 城市美发管理系统开发的可维护性是非常重要的,经过测试,可维护性没有问题 |
根据上一节功能分析,可以得出系统的用例,注册用户角色用例如图2.1所示。

图2.1 城市美发管理系统中注册用户角色用例图
管理员角色用例如图2.2所示。
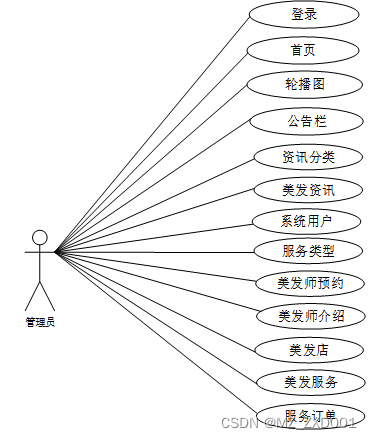
图2.2城市美发管理系统管理员角色用例图
3 城市美发管理系统总体设计
根据第二章中城市美发管理系统的功能分析可知,城市美发管理系统中整体功能模块图如图3.1所示,

图3.1城市美发管理系统功能模块图
下面是整个城市美发管理系统中主要的数据库表总E-R实体关系图。

图3.2城市美发管理系统总E-R关系图
表a_hairdresser (美发师)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | a_hairdresser_id | int | 10 | 0 | N | Y | 美发师ID | |
| 2 | hairdresser_id | varchar | 64 | 0 | Y | N | 美发师工号 | |
| 3 | hairdresser_name | varchar | 64 | 0 | Y | N | 美发师姓名 | |
| 4 | level | varchar | 64 | 0 | Y | N | 级别 | |
| 5 | store | varchar | 64 | 0 | Y | N | 所属门店 | |
| 6 | gender | varchar | 64 | 0 | Y | N | 性别 | |
| 7 | examine_state | varchar | 16 | 0 | N | N | 已通过 | 审核状态 |
| 8 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 9 | user_id | int | 10 | 0 | N | N | 0 | 用户ID |
| 10 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 11 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表collect (收藏)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | collect_id | int | 10 | 0 | N | Y | 收藏ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 收藏人ID: |
| 3 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 4 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 5 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 6 | title | varchar | 255 | 0 | Y | N | 标题: | |
| 7 | img | varchar | 255 | 0 | Y | N | 封面: | |
| 8 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 9 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
表comment (评论)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | comment_id | int | 10 | 0 | N | Y | 评论ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 评论人ID: |
| 3 | reply_to_id | int | 10 | 0 | N | N | 0 | 回复评论ID:空为0 |
| 4 | content | longtext | 2147483647 | 0 | Y | N | 内容: | |
| 5 | nickname | varchar | 255 | 0 | Y | N | 昵称: | |
| 6 | avatar | varchar | 255 | 0 | Y | N | 头像地址:[0,255] | |
| 7 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 8 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 9 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 10 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 11 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
表hairdresser_appointment (美发师预约)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | hairdresser_appointment_id | int | 10 | 0 | N | Y | 美发师预约ID | |
| 2 | hairdresser_id | int | 10 | 0 | Y | N | 0 | 美发师工号 |
| 3 | hairdresser_name | varchar | 64 | 0 | Y | N | 美发师姓名 | |
| 4 | hairdresser_level | varchar | 64 | 0 | Y | N | 美发师级别 | |
| 5 | user | int | 10 | 0 | Y | N | 0 | 用户 |
| 6 | appointment_service_time | datetime | 19 | 0 | Y | N | 预约服务时间 | |
| 7 | contact_number | varchar | 64 | 0 | Y | N | 联系电话 | |
| 8 | full_name | varchar | 64 | 0 | Y | N | 姓名 | |
| 9 | service_content | text | 65535 | 0 | Y | N | 服务内容 | |
| 10 | examine_state | varchar | 16 | 0 | N | N | 未审核 | 审核状态 |
| 11 | examine_reply | varchar | 16 | 0 | Y | N | 审核回复 | |
| 12 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 13 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 14 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表hairdresser_introduction (美发师介绍)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | hairdresser_introduction_id | int | 10 | 0 | N | Y | 美发师介绍ID | |
| 2 | hairdresser_id | int | 10 | 0 | Y | N | 0 | 美发师工号 |
| 3 | hairdresser_name | varchar | 64 | 0 | Y | N | 美发师姓名 | |
| 4 | store | varchar | 64 | 0 | Y | N | 所属门店 | |
| 5 | level | varchar | 64 | 0 | Y | N | 级别 | |
| 6 | photo | varchar | 255 | 0 | Y | N | 照片 | |
| 7 | gender | varchar | 64 | 0 | Y | N | 性别 | |
| 8 | entire_period_of_actual_operation | varchar | 64 | 0 | Y | N | 从业年限 | |
| 9 | areas_of_expertise | text | 65535 | 0 | Y | N | 擅长领域 | |
| 10 | career | text | 65535 | 0 | Y | N | 职业生涯 | |
| 11 | personal_introduction | longtext | 2147483647 | 0 | Y | N | 个人介绍 | |
| 12 | hits | int | 10 | 0 | N | N | 0 | 点击数 |
| 13 | praise_len | int | 10 | 0 | N | N | 0 | 点赞数 |
| 14 | examine_state | varchar | 16 | 0 | N | N | 未审核 | 审核状态 |
| 15 | examine_reply | varchar | 16 | 0 | Y | N | 审核回复 | |
| 16 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 17 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 18 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表hairdressing_services (美发服务)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | hairdressing_services_id | int | 10 | 0 | N | Y | 美发服务ID | |
| 2 | name_of_hair_salon | varchar | 64 | 0 | Y | N | 美发店名称 | |
| 3 | service_name | varchar | 64 | 0 | Y | N | 服务名称 | |
| 4 | service_category | varchar | 64 | 0 | Y | N | 服务类别 | |
| 5 | price | int | 10 | 0 | Y | N | 0 | 价格 |
| 6 | service_content | text | 65535 | 0 | Y | N | 服务内容 | |
| 7 | purchase_instructions | text | 65535 | 0 | Y | N | 购买须知 | |
| 8 | details | longtext | 2147483647 | 0 | Y | N | 详情 | |
| 9 | hits | int | 10 | 0 | N | N | 0 | 点击数 |
| 10 | praise_len | int | 10 | 0 | N | N | 0 | 点赞数 |
| 11 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 12 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 13 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表hair_salon (美发店)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | hair_salon_id | int | 10 | 0 | N | Y | 美发店ID | |
| 2 | name_of_hair_salon | varchar | 64 | 0 | Y | N | 美发店名称 | |
| 3 | photo | varchar | 255 | 0 | Y | N | 照片 | |
| 4 | address | varchar | 64 | 0 | Y | N | 地址 | |
| 5 | business_hours | varchar | 64 | 0 | Y | N | 营业时间 | |
| 6 | store_size | varchar | 64 | 0 | Y | N | 门店规模 | |
| 7 | customer_service_telephone_numbers | varchar | 64 | 0 | Y | N | 客服电话 | |
| 8 | store_introduction | longtext | 2147483647 | 0 | Y | N | 门店介绍 | |
| 9 | hits | int | 10 | 0 | N | N | 0 | 点击数 |
| 10 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 11 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 12 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表hits (用户点击)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | hits_id | int | 10 | 0 | N | Y | 点赞ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 点赞人: |
| 3 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 4 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
表praise (点赞)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | praise_id | int | 10 | 0 | N | Y | 点赞ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 点赞人: |
| 3 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 4 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 8 | status | bit | 1 | 0 | N | N | 1 | 点赞状态:1为点赞,0已取消 |
表registered_user (注册用户)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | registered_user_id | int | 10 | 0 | N | Y | 注册用户ID | |
| 2 | gender | varchar | 64 | 0 | Y | N | 性别 | |
| 3 | full_name | varchar | 64 | 0 | Y | N | 姓名 | |
| 4 | age | varchar | 64 | 0 | Y | N | 年龄 | |
| 5 | examine_state | varchar | 16 | 0 | N | N | 已通过 | 审核状态 |
| 6 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 7 | user_id | int | 10 | 0 | N | N | 0 | 用户ID |
| 8 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 9 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表service_classification (服务分类)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | service_classification_id | int | 10 | 0 | N | Y | 服务分类ID | |
| 2 | service_category | varchar | 64 | 0 | Y | N | 服务类别 | |
| 3 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 4 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 5 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表service_order (服务订单)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | service_order_id | int | 10 | 0 | N | Y | 服务订单ID | |
| 2 | name_of_hair_salon | varchar | 64 | 0 | Y | N | 美发店名称 | |
| 3 | service_name | varchar | 64 | 0 | Y | N | 服务名称 | |
| 4 | price | varchar | 64 | 0 | Y | N | 价格 | |
| 5 | user | int | 10 | 0 | Y | N | 0 | 用户 |
| 6 | full_name | varchar | 64 | 0 | Y | N | 姓名 | |
| 7 | contact_number | varchar | 64 | 0 | Y | N | 联系电话 | |
| 8 | remarks | text | 65535 | 0 | Y | N | 备注 | |
| 9 | pay_state | varchar | 16 | 0 | N | N | 未支付 | 支付状态 |
| 10 | pay_type | varchar | 16 | 0 | Y | N | 支付类型: 微信、支付宝、网银 | |
| 11 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 12 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 13 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
表slides (轮播图)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | slides_id | int | 10 | 0 | N | Y | 轮播图ID: | |
| 2 | title | varchar | 64 | 0 | Y | N | 标题: | |
| 3 | content | varchar | 255 | 0 | Y | N | 内容: | |
| 4 | url | varchar | 255 | 0 | Y | N | 链接: | |
| 5 | img | varchar | 255 | 0 | Y | N | 轮播图: | |
| 6 | hits | int | 10 | 0 | N | N | 0 | 点击量: |
| 7 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 8 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
4城市美发管理系统设计与实现
城市美发管理系统的详细设计与实现主要是根据前面的城市美发管理系统的需求分析和城市美发管理系统的总体设计来设计页面并实现业务逻辑。主要从城市美发管理系统界面实现、业务逻辑实现这两部分进行介绍。
当进入城市美发管理系统的时候,首先映入眼帘的是系统的导航栏,下面是轮播图以及公告,其主界面展示如下图4.1所示。
图4.1 首页界面图
不是城市美发管理系统中正式用户的是可以在线进行注册的,如果你没有本城市美发管理系统的账号的话,添加“注册”,当填写上自己的账号+密码+确认密码+昵称+邮箱+手机号等后再点击“注册”按钮后将会先验证输入的有没有空数据,再次验证密码和确认密码是否是一样的,最后验证输入的账户名和数据库表中已经注册的账户名是否重复,只有都验证没问题后即可用户注册成功。注册界面实现了用户的注册,其注册界面展示如下图4。2所示。
图4.2 注册界面图
注册逻辑代码如下:
/**
* 注册
* @param user
* @return
*/
@PostMapping("register")
public Map<String, Object> signUp(@RequestBody User user) {
// 查询用户
Map<String, String> query = new HashMap<>();
query.put("username",user.getUsername());
List list = service.select(query, new HashMap<>()).getResultList();
if (list.size()>0){
return error(30000, "用户已存在");
}
user.setUserId(null);
user.setPassword(service.encryption(user.getPassword()));
service.save(user);
return success(1);
}
/**
* 用户ID:[0,8388607]用户获取其他与用户相关的数据
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Integer userId;
/**
* 账户状态:[0,10](1可用|2异常|3已冻结|4已注销)
*/
@Basic
@Column(name = "state")
private Integer state;
/**
* 所在用户组:[0,32767]决定用户身份和权限
*/
@Basic
@Column(name = "user_group")
private String userGroup;
/**
* 上次登录时间:
*/
@Basic
@Column(name = "login_time")
private Timestamp loginTime;
/**
* 手机号码:[0,11]用户的手机号码,用于找回密码时或登录时
*/
@Basic
@Column(name = "phone")
private String phone;
/**
* 手机认证:[0,1](0未认证|1审核中|2已认证)
*/
@Basic
@Column(name = "phone_state")
private Integer phoneState;
/**
* 用户名:[0,16]用户登录时所用的账户名称
*/
@Basic
@Column(name = "username")
private String username;
/**
* 昵称:[0,16]
*/
@Basic
@Column(name = "nickname")
private String nickname;
/**
* 密码:[0,32]用户登录所需的密码,由6-16位数字或英文组成
*/
@Basic
@Column(name = "password")
private String password;
/**
* 邮箱:[0,64]用户的邮箱,用于找回密码时或登录时
*/
@Basic
@Column(name = "email")
private String email;
/**
* 邮箱认证:[0,1](0未认证|1审核中|2已认证)
*/
@Basic
@Column(name = "email_state")
private Integer emailState;
/**
* 头像地址:[0,255]
*/
@Basic
@Column(name = "avatar")
private String avatar;
/**
* 创建时间:
*/
@Basic
@Column(name = "create_time")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private Timestamp createTime;
@Basic
@Transient
private String code;
}
城市美发管理系统中的前台上注册后的用户是可以通过自己的账户名和密码进行登录的,当用户输入完整的自己的账户名和密码信息并点击“登录”按钮后,将会首先验证输入的有没有空数据,再次验证输入的账户名+密码和数据库中当前保存的用户信息是否一致,只有在一致后将会登录成功并自动跳转到城市美发管理系统的首页中;否则将会提示相应错误信息,用户登录界面如下图4.3所示。
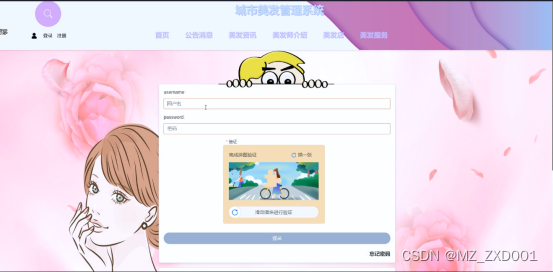
图4.3 登录界面图
登录的逻辑代码如下所示。
/**
* 登录
* @param data
* @param httpServletRequest
* @return
*/
@PostMapping("login")
public Map<String, Object> login(@RequestBody Map<String, String> data, HttpServletRequest httpServletRequest) {
log.info("[执行登录接口]");
String username = data.get("username");
String email = data.get("email");
String phone = data.get("phone");
String password = data.get("password");
List resultList = null;
Map<String, String> map = new HashMap<>();
if(username != null && "".equals(username) == false){
map.put("username", username);
resultList = service.select(map, new HashMap<>()).getResultList();
}
else if(email != null && "".equals(email) == false){
map.put("email", email);
resultList = service.select(map, new HashMap<>()).getResultList();
}
else if(phone != null && "".equals(phone) == false){
map.put("phone", phone);
resultList = service.select(map, new HashMap<>()).getResultList();
}else{
return error(30000, "账号或密码不能为空");
}
if (resultList == null || password == null) {
return error(30000, "账号或密码不能为空");
}
//判断是否有这个用户
if (resultList.size()<=0){
return error(30000,"用户不存在");
}
User byUsername = (User) resultList.get(0);
Map<String, String> groupMap = new HashMap<>();
groupMap.put("name",byUsername.getUserGroup());
List groupList = userGroupService.select(groupMap, new HashMap<>()).getResultList();
if (groupList.size()<1){
return error(30000,"用户组不存在");
}
UserGroup userGroup = (UserGroup) groupList.get(0);
//查询用户审核状态
if (!StringUtils.isEmpty(userGroup.getSourceTable())){
String sql = "select examine_state from "+ userGroup.getSourceTable() +" WHERE user_id = " + byUsername.getUserId();
String res = String.valueOf(service.runCountSql(sql).getSingleResult());
if (res==null){
return error(30000,"用户不存在");
}
if (!res.equals("已通过")){
return error(30000,"该用户审核未通过");
}
}
//查询用户状态
if (byUsername.getState()!=1){
return error(30000,"用户非可用状态,不能登录");
}
String md5password = service.encryption(password);
if (byUsername.getPassword().equals(md5password)) {
// 存储Token到数据库
AccessToken accessToken = new AccessToken();
accessToken.setToken(UUID.randomUUID().toString().replaceAll("-", ""));
accessToken.setUser_id(byUsername.getUserId());
tokenService.save(accessToken);
// 返回用户信息
JSONObject user = JSONObject.parseObject(JSONObject.toJSONString(byUsername));
user.put("token", accessToken.getToken());
JSONObject ret = new JSONObject();
ret.put("obj",user);
return success(ret);
} else {
return error(30000, "账号或密码不正确");
}
}
用户使用该城市美发管理系统注册完成后,用户对登录密码有修改需求时,系统也可以提供用户修改密码权限。系统中所有的操作者能够变更自己的密码信息,执行该功能首先必须要登入系统,然后选择密码变更选项以后在给定的文本框中填写初始密码和新密码来完成修改密码的操作。在填写的时候,假如两次密码填写存在差异,那么此次密码变更操作失败,下面的图片展示的就是该板块对应的工作面。修改密码界面如下图4.4所示。
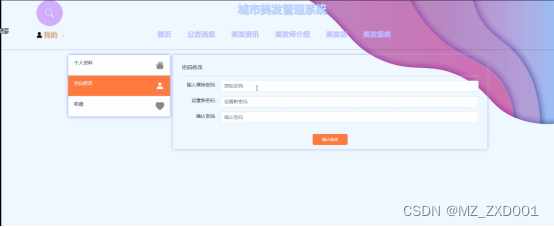
图4.4修改密码界面图
4.5美发师介绍详情界面
用户可以查看美发师介绍,在查询到自己想要了解的美发师介绍的时候,可以进入查看详细的介绍,点击“预约”这一按钮以后会跳转到预约信息填写的界面,根据提示填写好预约的信息,点击“提交”以后预约就完成了,在美发师介绍详情这个界面,同时支持用户对喜欢的美发师介绍进行收藏、点赞的功能,美发师介绍详情展示页面如图4.5所示。
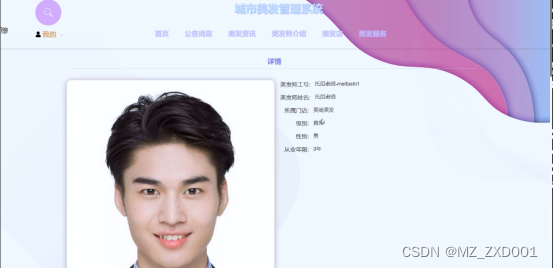
图4.5 美发师介绍详情界面图
美发师介绍逻辑代码如下:
@PostMapping("/add")
@Transactional
public Map<String, Object> add(HttpServletRequest request) throws IOException {
service.insert(service.readBody(request.getReader()));
return success(1);
}
@Transactional
public Map<String, Object> addMap(Map<String,Object> map){
service.insert(map);
return success(1);
}
public Map<String,Object> readBody(BufferedReader reader){
BufferedReader br = null;
StringBuilder sb = new StringBuilder("");
try{
br = reader;
String str;
while ((str = br.readLine()) != null){
sb.append(str);
}
br.close();
String json = sb.toString();
return JSONObject.parseObject(json, Map.class);
}catch (IOException e){
e.printStackTrace();
}finally{
if (null != br){
try{
br.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
return null;
}
public void insert(Map<String,Object> body){
StringBuffer sql = new StringBuffer("INSERT INTO ");
sql.append("`").append(table).append("`").append(" (");
for (Map.Entry<String,Object> entry:body.entrySet()){
sql.append("`"+humpToLine(entry.getKey())+"`").append(",");
}
sql.deleteCharAt(sql.length()-1);
sql.append(") VALUES (");
for (Map.Entry<String,Object> entry:body.entrySet()){
Object value = entry.getValue();
if (value instanceof String){
sql.append("'").append(entry.getValue()).append("'").append(",");
}else {
sql.append(entry.getValue()).append(",");
}
}
sql.deleteCharAt(sql.length() - 1);
sql.append(")");
log.info("[{}] - 插入操作:{}",table,sql);
Query query = runCountSql(sql.toString());
query.executeUpdate();
}
当访客点击城市美发管理系统中导航栏左侧的“美发资讯”后将会进入到该“美发资讯”列表的界面,然后选择想要看的美发资讯信息,点击进入到详细界面,在详细界面可以收藏+赞+评论等操作,美发资讯界面如下图4.7所示。
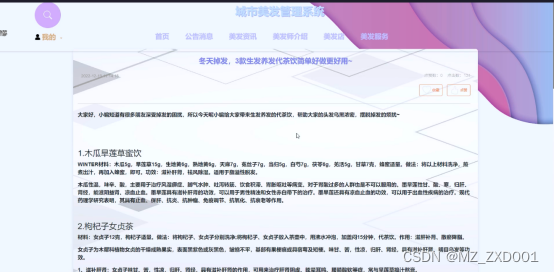
图4.6 美发资讯界面图
美发资讯界面逻辑代码如下:
@RequestMapping(value = {"/count_group", "/count"})
public Map<String, Object> count(HttpServletRequest request) {
Query count = service.count(service.readQuery(request), service.readConfig(request));
return success(count.getResultList());
}
用户可以查看美发店信息,在查询到自己想要了解的美发店的时候,可以进入查看详细的介绍,支持用户对喜欢的美发店进行评论的功能。美发店详情界面如下图4.7所示。

图4.7美发店详情界面图
美发店界面逻辑代码如下:
@RequestMapping(value = {"/avg_group", "/avg"})
public Map<String, Object> avg(HttpServletRequest request) {
Query count = service.avg(service.readQuery(request), service.readConfig(request));
return success(count.getResultList());
}
4.8系统用户管理界面
城市美发管理系统中的管理员在“系统用户”这一菜单是中可以对注册的用户、美发师以及管理员人员进行管控。界面如下图4.8所示。

图4.8系统用户管理界面图
系统用户管理逻辑代码如下:
@PostMapping("/set")
@Transactional
public Map<String, Object> set(HttpServletRequest request) throws IOException {
service.update(service.readQuery(request), service.readConfig(request), service.readBody(request.getReader()));
return success(1);
}
public Map<String,String> readConfig(HttpServletRequest request){
Map<String,String> map = new HashMap<>();
map.put(FindConfig.PAGE,request.getParameter(FindConfig.PAGE));
map.put(FindConfig.SIZE,request.getParameter(FindConfig.SIZE));
map.put(FindConfig.LIKE,request.getParameter(FindConfig.LIKE));
map.put(FindConfig.ORDER_BY,request.getParameter(FindConfig.ORDER_BY));
map.put(FindConfig.FIELD,request.getParameter(FindConfig.FIELD));
map.put(FindConfig.GROUP_BY,request.getParameter(FindConfig.GROUP_BY));
map.put(FindConfig.MAX_,request.getParameter(FindConfig.MAX_));
map.put(FindConfig.MIN_,request.getParameter(FindConfig.MIN_));
return map;
}
public Map<String,String> readQuery(HttpServletRequest request){
String queryString = request.getQueryString();
if (queryString != null && !"".equals(queryString)) {
String[] querys = queryString.split("&");
Map<String, String> map = new HashMap<>();
for (String query : querys) {
String[] q = query.split("=");
map.put(q[0], q[1]);
}
map.remove(FindConfig.PAGE);
map.remove(FindConfig.SIZE);
map.remove(FindConfig.LIKE);
map.remove(FindConfig.ORDER_BY);
map.remove(FindConfig.FIELD);
map.remove(FindConfig.GROUP_BY);
map.remove(FindConfig.MAX_);
map.remove(FindConfig.MIN_);
return map;
}else {
return new HashMap<>();
}
}
@Transactional
public void update(Map<String,String> query,Map<String,String> config,Map<String,Object> body){
StringBuffer sql = new StringBuffer("UPDATE ").append("`").append(table).append("`").append(" SET ");
for (Map.Entry<String,Object> entry:body.entrySet()){
Object value = entry.getValue();
if (value instanceof String){
sql.append("`"+humpToLine(entry.getKey())+"`").append("=").append("'").append(value).append("'").append(",");
}else {
sql.append("`"+humpToLine(entry.getKey())+"`").append("=").append(value).append(",");
}
}
sql.deleteCharAt(sql.length()-1);
sql.append(toWhereSql(query,"0".equals(config.get(FindConfig.LIKE))));
log.info("[{}] - 更新操作:{}",table,sql);
Query query1 = runCountSql(sql.toString());
query1.executeUpdate();
}
public String toWhereSql(Map<String,String> query, Boolean like) {
if (query.size() > 0) {
try {
StringBuilder sql = new StringBuilder(" WHERE ");
for (Map.Entry<String, String> entry : query.entrySet()) {
if (entry.getKey().contains(FindConfig.MIN_)) {
String min = humpToLine(entry.getKey()).replace("_min", "");
sql.append("`"+min+"`").append(" >= '").append(URLDecoder.decode(entry.getValue(), "UTF-8")).append("' and ");
continue;
}
if (entry.getKey().contains(FindConfig.MAX_)) {
String max = humpToLine(entry.getKey()).replace("_max", "");
sql.append("`"+max+"`").append(" <= '").append(URLDecoder.decode(entry.getValue(), "UTF-8")).append("' and ");
continue;
}
if (like == true) {
sql.append("`"+humpToLine(entry.getKey())+"`").append(" LIKE '%").append(URLDecoder.decode(entry.getValue(), "UTF-8")).append("%'").append(" and ");
} else {
sql.append("`"+humpToLine(entry.getKey())+"`").append(" = '").append(URLDecoder.decode(entry.getValue(), "UTF-8")).append("'").append(" and ");
}
}
sql.delete(sql.length() - 4, sql.length());
sql.append(" ");
return sql.toString();
} catch (UnsupportedEncodingException e) {
log.info("拼接sql 失败:{}", e.getMessage());
}
}
return "";
}
4.9资源管理界面
资源管理主要管理员是对美发资讯以及美发资讯所属的分类进行管控,包含了用户对美发资讯提交的评论信息,界面如下图4.9所示。
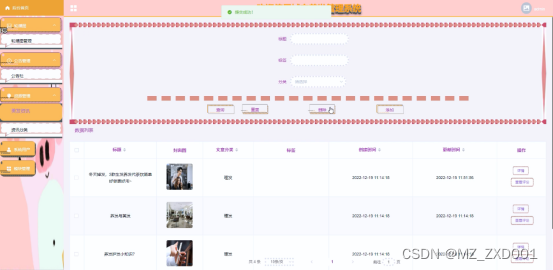
图4.9 资源管理界面图
资源管理关键代码如下:
@RequestMapping("/get_list")
public Map<String, Object> getList(HttpServletRequest request) {
Map<String, Object> map = service.selectToPage(service.readQuery(request), service.readConfig(request));
return success(map);
4.10模块管理界面
城市美发管理系统中的管理人员在“模块管理”这一菜单下是可以对城市美发管理系统内的美发师介绍、服务类型、美发师预约、美发店、美发服务、服务订单进行管控的,其管理界面如下图4.10所示。
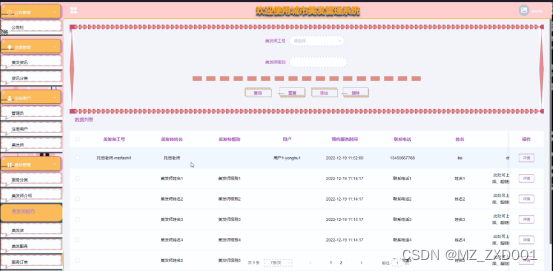
图4.10模块管理界面图
5城市美发管理系统测试
城市美发管理系统测试是为了检验软件是否达到设计要求,是否存在错误,通过测试的方法来检查城市美发管理系统,以便发现城市美发管理系统中的错误。测试工作是保证城市美发管理系统质量的关键。
问题1:数据库无法添加中文。
解决过程:重新创建数据库,将库的编码格式改为utf8。
效果:能在新库的表中添加中文。
问题2:控制台报错前台与后台参数不一致
解决过程:检查代码,找到报错参数完成修改,继续报错,服务器移除项目重新运行。
效果:重启项目不再报错。
问题3:报错No bean named 'sysLogServiceImpl' available找不到名为sysLogServiceImpl的bean的对象。
解决过程:询问导师报错原因,发现错误原因是未添加注解@Service,需要在在impl实现类的外面添加@Service注解。
效果:重新debug项目无报错。
问题4:启动项目时报错:Mapped Statements collection does not contain value for
解决过程:网上搜索解决办法,出错可能的原因有多个,经过努力排查,错误原因是mapper映射地址有误。在mybatis-config里重新配置地址。
效果:项目启动正常
系统测试包括:用户登录功能测试、美发师介绍展示功能测试、美发师介绍添加、美发师介绍搜索、密码修改功能测试,如表5-1、5-2、5-3、5-4、5-5所示:
用户登录功能测试:
表5-1 用户登录功能测试表
| 用例名称 | 用户登录系统 |
| 目的 | 测试用户通过正确的用户名和密码可否登录功能 |
| 前提 | 未登录的情况下 |
| 测试流程 | 1) 进入登录页面 2) 输入正确的用户名和密码 |
| 预期结果 | 用户名和密码正确的时候,跳转到登录成功界面,反之则显示错误信息,提示重新输入 |
| 实际结果 | 实际结果与预期结果一致 |
美发师介绍查看功能测试:
表5-2 美发师介绍查看功能测试表
| 用例名称 | 美发师介绍查看 |
| 目的 | 测试美发师介绍查看功能 |
| 前提 | 用户登录 |
| 测试流程 | 点击美发师介绍列表 |
| 预期结果 | 可以查看到所有美发师介绍 |
| 实际结果 | 实际结果与预期结果一致 |
管理员添加美发师介绍界面测试:
表5-3 管理员添加美发师介绍界面测试表
| 用例名称 | 美发师介绍发布测试用例 |
| 目的 | 测试美发师介绍发布功能 |
| 前提 | 用户正常登录情况下 |
| 测试流程 | 1)管理员点击美发师介绍管理就,然后点击添加后并填写信息。 2)点击进行提交。 |
| 预期结果 | 提交以后,页面首页会显示新的美发师介绍 |
| 实际结果 | 实际结果与预期结果一致 |
美发师介绍搜索功能测试:
表5-4美发师介绍搜索功能测试表
| 用例名称 | 美发师介绍搜索测试 |
| 目的 | 测试美发师介绍搜索功能 |
| 前提 | 无 |
| 测试流程 | 1)在搜索框填入搜索关键字。 2)点击搜索按钮。 |
| 预期结果 | 页面显示包含有搜索关键字的美发师介绍 |
| 实际结果 | 实际结果与预期结果一致 |
密码修改功能测试:
表5-5 密码修改功能测试表
| 用例名称 | 密码修改测试用例 |
| 目的 | 测试管理员密码修改功能 |
| 前提 | 管理员用户正常登录情况下 |
| 测试流程 | 1)管理员密码修改并完成填写。 2)点击进行提交。 |
| 预期结果 | 使用新的密码可以登录 |
| 实际结果 | 实际结果与预期结果一致 |
5.3 系统测试结果
通过编写城市美发管理系统的测试用例,已经检测完毕用户登录模块、美发师介绍查看模块、美发师介绍添加模块、美发师介绍搜索模块、密码修改功能测试,通过这5大模块为城市美发管理系统的后期推广运营提供了强力的技术支撑。
结论
至此,城市美发管理系统已经结束,在开发前做了许多的准备,在本系统的设计和开发过程中阅览和学习了许多文献资料,从中我也收获了很多宝贵的方法和设计思路,对系统的开发也起到了很重要的作用,系统的开发技术选用的都是自己比较熟悉的,比如springboot、JAVA技术、MYSQL,这些技术都是在以前的学习中学到了,其中许多的设计思路和方法都是在以前不断地学习中摸索出来的经验,其实对于我们来说工作量还是比较大的,但是正是由于之前的积累与准备,才能顺利的完成这个项目,由此看来,积累经验跟做好准备是十分重要的事情。
当然在该系统的设计与实现的过程中也离不开老师以及同学们的帮助,正是因为他们的指导与帮助,我才能够成功的在预期内完成了这个系统。同时在这个过程当中我也收获了很多东西,此系统也有需要改进的地方,但是由于专业知识的浅薄,并不能做到十分完美,希望以后有机会可以让其真正的投入到使用之中。
参考文献
[1]卢生玉. 基于Java的大学生综合测评管理系统的设计与实现[J]. 山西电子技术,2022,(05):69-71+81.
[2]葛萌,李闯楠,高凯. 基于SpringBoot的地方精准扶贫管理系统[J]. 软件,2022,43(09):17-19+31.
[3]庄帅,吕波. 基于Java设计实现职工信息管理系统[J]. 信息系统工程,2022,(07):149-152.
[4]李伟. 基于Java技术平台的办公管理系统设计与实现[J]. 信息与电脑(理论版),2022,34(13):152-154.
[5]陈颖灵,朱映辉,江玉珍,黄栾雅. 基于SpringBoot学生实训管理系统的设计与实现[J]. 电脑知识与技术,2022,18(19):49-51.
[6]向兵,董晓红. 基于SpringBoot的高校教材管理系统的设计与实现[J]. 电脑知识与技术,2022,18(14):12-15.
[7]陈谦民,高越,叶益成,谌科,吉星. 基于Java的美发管理系统的设计与应用[J]. 现代信息科技,2022,6(07):1-7.
[8]张军. 基于Java的企业人力资源管理系统的设计与实现[J]. 中国信息化,2022,(03):42-44.
[9]杨士永. 基于Java的对象存储管理系统的设计与实现[J]. 电子技术与软件工程,2022,(04):253-257.
[10]罗超. 基于Java Web教研信息管理系统的概要设计[J]. 信息记录材料,2022,23(01):22-25.
[11]胡素娟. 基于Java图书管理系统的设计与实现[J]. 信息记录材料,2021,22(12):161-163.
[12]蒋晟,陈科. 基于SpringBoot的学生宿舍管理系统的设计与实现[J]. 现代信息科技,2021,5(12):6-9.
[13]Fuyuan Cheng. Talent Recruitment Management System for Small and Micro Enterprises Based on Springboot Framework[J]. Advances in Educational Technology and Psychology,2021,5(2).
[14]Randeep Singh,Amit Bindal,Ashok Kumar. A framework to improve quality of a Java system by performing refactoring[J]. International Journal of System of Systems Engineering,2020,10(4).
[15]Guanhong Chen,Jiangming Xu. Design and implementation of efficient Learning platform based on SpringBoot Framework[J]. Journal of Electronics and Information Science,2020,6(1).
[16]刘安旺. 便利店数据管理系统的设计与实现[D].东北农业大学,2020.
致 谢
时间过的很快,不知不觉,在中北大学的学习生活即将结束。毕业之际,我真诚地向帮助过我的老师、家人、同学、朋友们表达感谢。首先要感谢的是我的母校。感谢母校给了我美好的生活和优越的学习环境,使我能学到了很多知识,也不断的变得优秀;感谢家人在这四年期间一直给与我的爱和无条件的支持,让我没有后顾之忧地完成学业;感谢软件学院的任课老师们给我鼓励和认可,让我有信心去做好每一件事情;感谢同学们的帮助,让我的大学生活更有意义。在此次毕业设计的实现过程中, 我得到了老师们的耐心指导让我顺利完成了该设计。从最初的选题和开题开始,老师就给予我很多帮助,他们认真负责的态度、丰富的景点经验让我学到了很多。
同时也要感谢我敬爱的班主任和实训美发师介绍的老师,他们在各个方面都教给了我丰富的经验,在面对各种困难时如何处理。因为今年的特殊性,老师们不仅在学习中给我以精心的指导,同时还在其它方面给予我观关怀,指导老师不辞辛苦的为大家录制视频和一遍遍讲解让我心怀感激之情。在此,我真诚的感恩、感谢我的指导健身教练们。
还要感谢实习期间不厌其烦教导我鼓励我的技术师傅,他指导了我各个方面的技巧,尤其是编程方面,迄今我的很多技巧和编写规范都有赖于他的指导、纠正。
最后还要特别感谢身边的各位同学们,一直支持鼓励我,无论何时何种境况。我很荣幸获得同学们的帮助,也很开心能够和大家共度大学四年的时光。
最后的最后,再次发自肺腑的感谢所有帮助过我的人。
免费领取项目源码,请关注❥点赞收藏并私信博主,谢谢~