昆明微网站魔兽世界做宏网站
1、问题现象:
JAVA类里定义成员变量使用首字母小写,第二个字母大写
@Getter
@Setter
public class BrandQueryObject extends QueryObject{private String pName;
}
结果页面报错,无法找到类型为 cn.wolfcode.ssm.query.BrandQueryObject 的对象上的属性 pName:
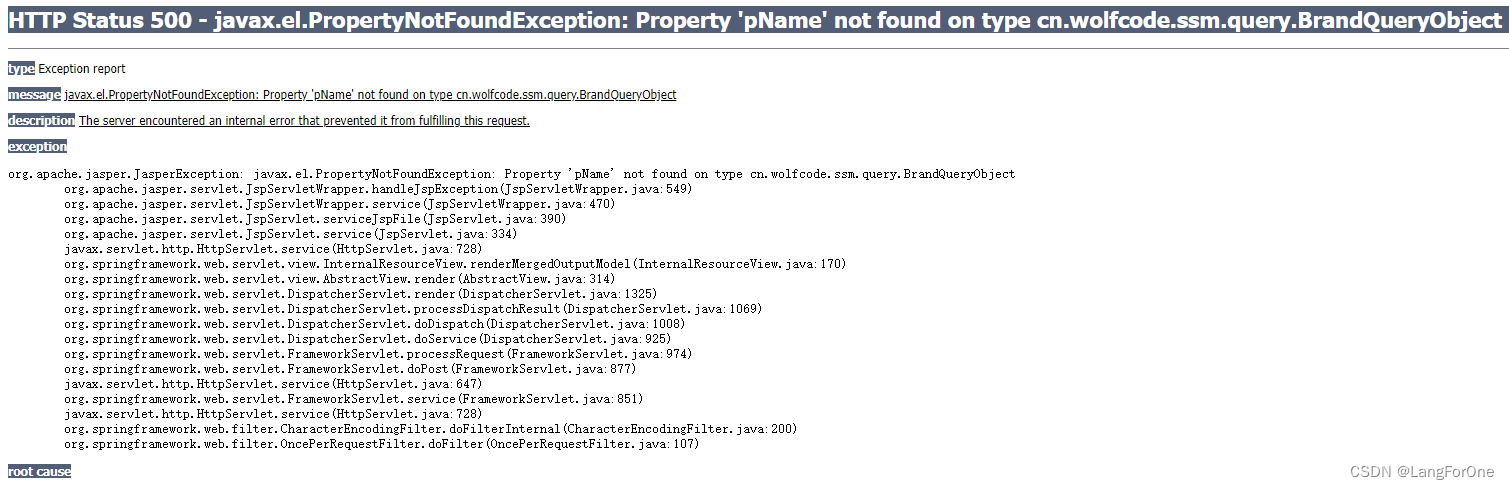
2、问题原因:
针对首字母小写,第二个字母大写的这种驼峰命名时,使用Lombok的@Getter和@Setter注解生成的getter和setter方法分别是:
public String getIPhone() {return iPhone;
}public void setIPhone(String iPhone) {this.iPhone = iPhone;
}
而正常场景下及Spring中对象的getter和setter方法应该是:
public String getiPhone() {return iPhone;
}public void setiPhone(String iPhone) {this.iPhone = iPhone;
}
也就是说Lombok与Spring针对这种首字母小写,第二个字母大写的对象的解析是不同的,而这也就自然而然影响到默认的Jackson的解析,导致返回给前端的属性名称不是我们预期中的名称,则前端判断取得的值为null,继而报错。
3、问题探讨与官方态度:
详见该文章:多年前就有人已经在lombok的github提出过对应的issue
4、解决方案:
- 方案一:不使用该格式命名的成员变量,即避免首字母小写后续直接跟第二个字母大写的命名。
- 方案二:利用Idea生成符合Spring规范的get/set,即手动生成get和set方法,或者使用编译器自动生成的:
public String getpName() {return pName;}public void setpName(String pName) {this.pName = pName;}
- 方案三:利用@JsonProperty(value = “xIndex”),强制Jackson在反序列化时给属性重新命名
完事收工,THX