网站建设辶金手指排名十一遵义网站制作一般需要多少钱
其实除了Character Controller, Rigidbody,我们还可以使用NavMeshAgent去做。这么做的好处是能避免玩家去莫名其妙的地方(毕竟基于烘焙过的导航网格),一般常见于元宇宙应用和mmo。
根据Unity手册,NavMeshAgent 也有和Character Controller 一样的move函数。
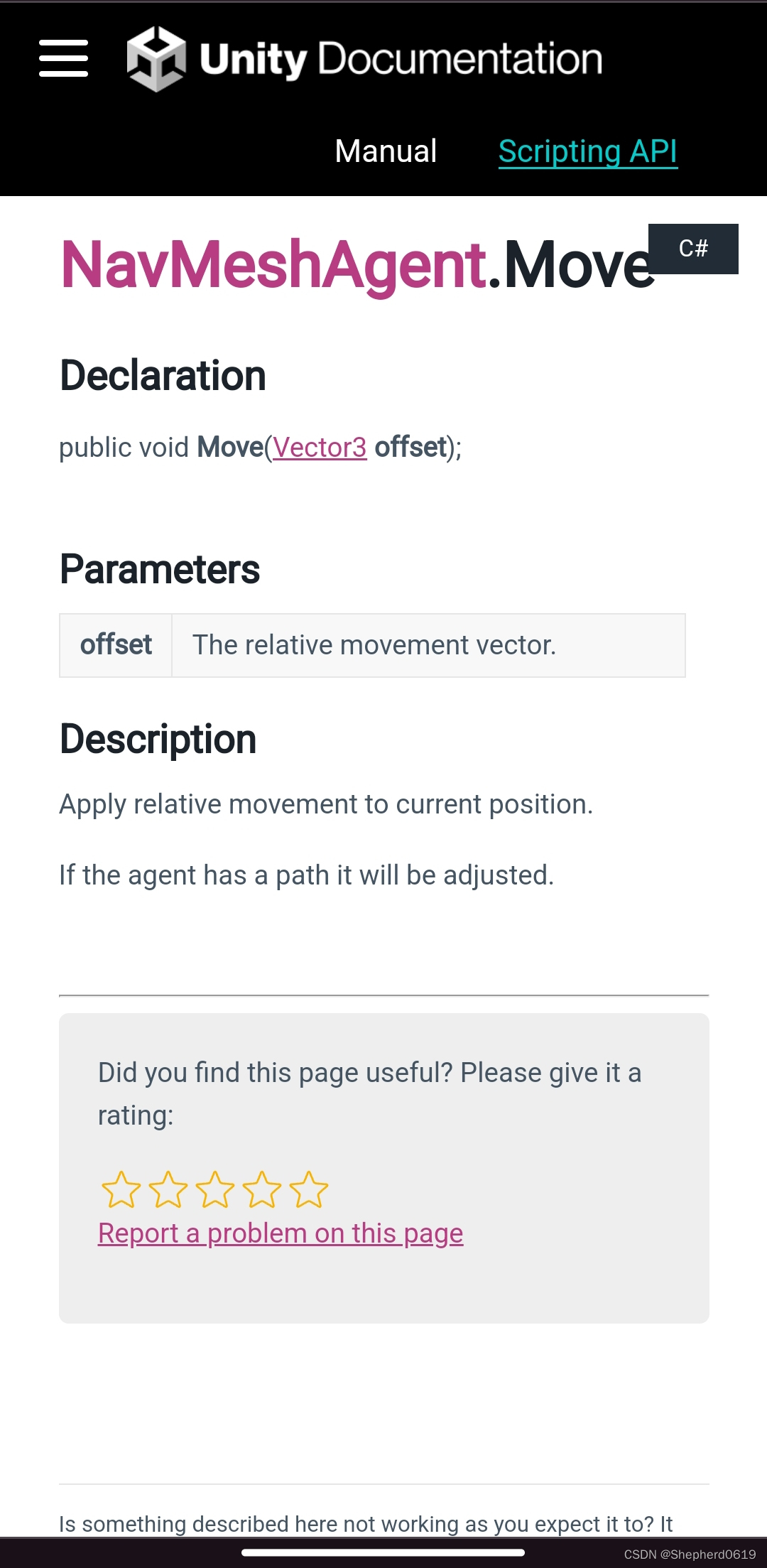
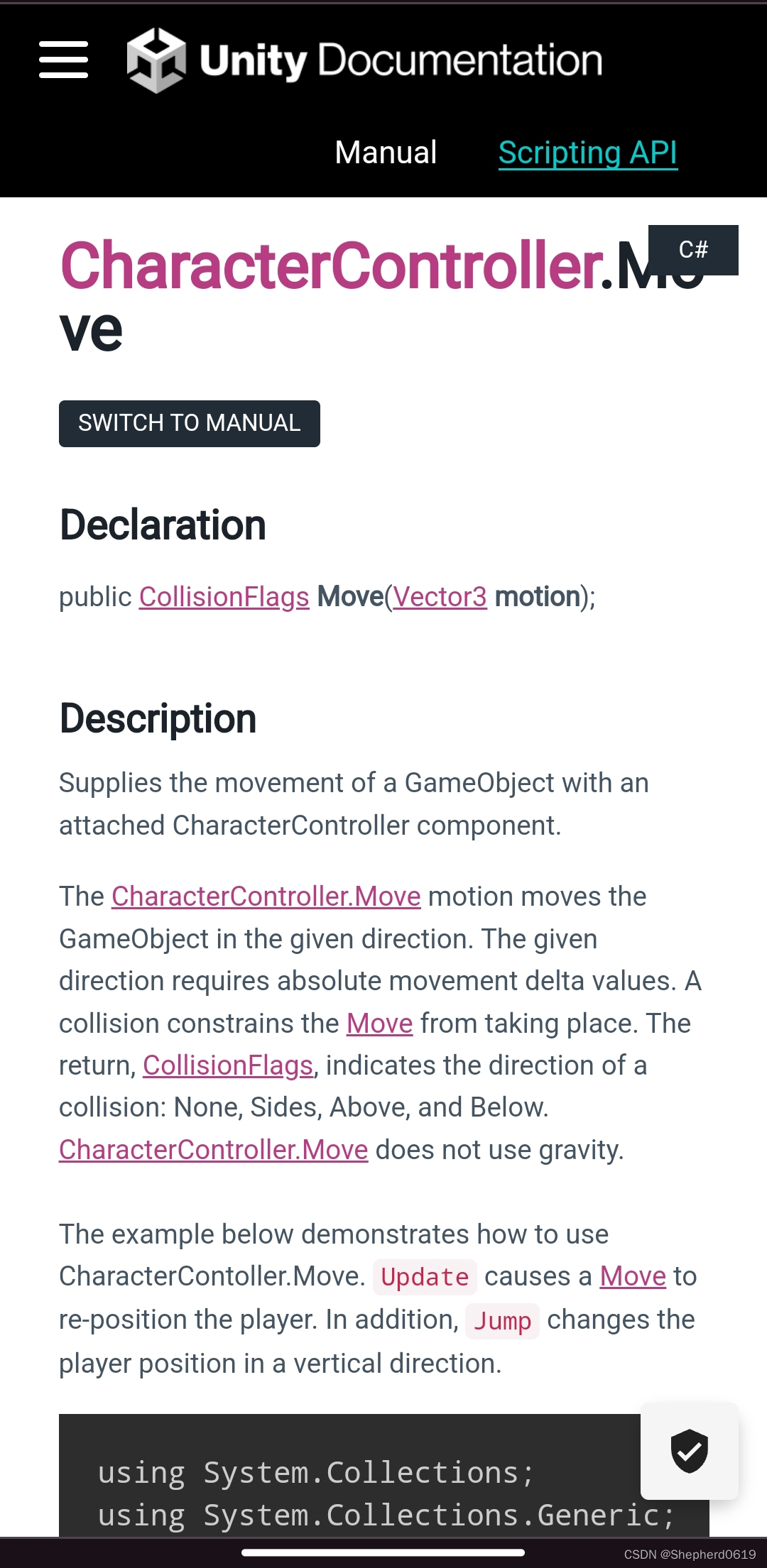
如果你现有的脚本用的是Character Controller,那移动这块应该很容易换成NavMeshAgent。
以下是一个基于NavMeshAgent 的简单玩家控制器代码示例:
Vector3 movement;NavMeshAgent agent;// Start is called before the first frame updatevoid Start(){agent = GetComponent<NavMeshAgent>();}// Update is called once per framevoid Update(){float horizontalInput = Input.GetAxisRaw("Horizontal");float verticalInput = Input.GetAxisRaw("Vertical");movement.Set(horizontalInput, 0f, verticalInput);agent.Move(movement * Time.deltaTime * agent.speed);}注意,agent.Move可能会抛空(如果角色不在烘焙网格上),你可以使用一个try catch去处理,如果抛了异常给它送到附近表面也可以(干脆不处理也行,或者这个时候换成Character Controller去操作也可,看你的应用情况)。
try{agent.Move(movement * Time.deltaTime * agent.speed);}catch(Exception ex){if (!agent.isOnNavMesh){NavMeshHit hit;if (NavMesh.SamplePosition(transform.position, out hit, 1.0f, NavMesh.AllAreas)){// 获取最近的NavMesh位置Vector3 nearestPos = hit.position;// 设置代理的目标位置为最近的NavMesh位置agent.Warp(nearestPos);}}}最后,Happy programming!