厦门网站建设680元机关网站建设方案
C语言经典游戏扫雷
- 前言
- 一.游戏规则
- 二.所需文件
- 三.创建菜单
- 四.游戏核心内容实现
- 1.创建棋盘
- 2.打印棋盘
- 3.布置雷
- 4.排查雷
- 5.game()函数具体实现
- 五.游戏运行实操
- 六.全部码源
前言
😀C语言实现扫雷是对基础代码能力的考察。通过本篇文章你将学会如何制作出扫雷,坚持一段时间的复习相信你肯定能够掌握扫雷 (文末附三子棋全部代码).
👉扫雷游戏网页版 - Minesweeper

一.游戏规则
🚦设计游戏前先了解三子棋基本规则,以围绕规则用C语言实现
一个扫雷盘面由许多方格(cell)组成,方格中随机分布着一定数量的雷(mine),一个格子中至多只有1雷。胜利条件是打开所有安全格(非雷格,safe cell),失败条件是打开了一个雷格(踩雷)。
二.所需文件
🧐扫雷并不是一项容易的代码,需要我们进行分文件编写。
🤔什么是分文件编写?
就是把我们的程序代码划分成多个文件,这样就不会把所有的代码都放在main.c里面,采用分模块的编程思想,进行功能划分,把每个功能不一样的单独放在一个c文件里,然后写头文件把它封装成可调用的一个函数,在主函数调用这个封装好的函数,编译的时候一起编译即可
✌好处:
a.功能责任划分
b.方便调试
c.主程序简洁
👀来让给我们看看具体操作如下:
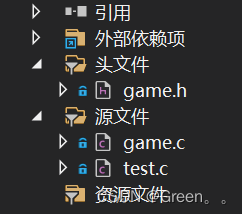
头文件中创建game.h ----用来声明函数
源文件中创建game.c—函数具体实现 / test.c—主题流程
三.创建菜单
先创建一个菜单以展示进入退出游戏功能:
void menu()
{printf("**********************\n");printf("****** 1.play ******\n");printf("****** 0.exit ******\n");printf("**********************\n");
}
用do…while循环实现菜单使用,switch语句进行菜单选择
int main()
{int input = 0;do{menu();printf("请输入选项>");scanf("%d", &input);switch (input){case 1:game();break;case 0:printf("退出游戏>\n");break;default:printf("选择错误,重新选择>\n");break;}} while (input);return 0;
}
四.游戏核心内容实现
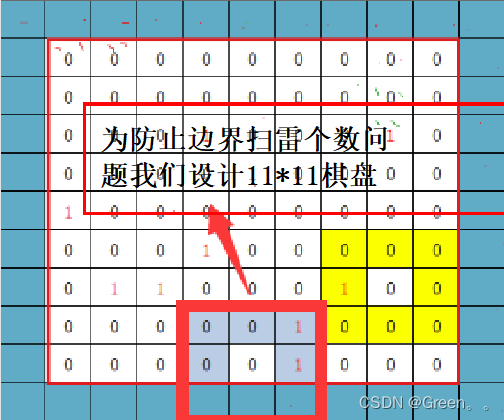
😇这里我们简化游戏,设置一个9*9的棋盘,安置10个雷。
排查过程如下:
1.如果这个位置是雷,那么游戏结束。
2.如果把不是雷的位置都找出来了,那么游戏结束。
3.如果这个位置不是雷,就计算这个位置的周围的8个格子有几个雷,并显示出雷的个数。
game()函数中实现整个游戏,先数组棋盘
1.创建棋盘
先创建数组(两个数组,为区别设置雷为1和统计雷个数为1做区分)

图一:”1“为雷(mine)
图二:”1“为雷的个数(show)

char mine[ROWS][COLS] = { 0 };char show[ROWS][COLS] = { 0 };
注:由于行,列频繁使用在game.h中宏定义
#define ROW 9
#define COL 9#define ROWS ROW + 2
#define COLS COL + 2
在game.h文件中声明创建棋盘函数:
//初始化棋盘
void InitBoard(char board[ROWS][COLS], int rows, int cols, char set);
在game.c文件中实现初始化棋盘函数
void InitBoard(char board[ROWS][COLS], int rows, int cols, char set)
{int i = 0;int j = 0;for (i = 0; i < rows; i++){for (j = 0; j < cols; j++){board[i][j] = set;}}
}
在test.c文件中实现调用
InitBoard(mine, ROWS, COLS, '0');
InitBoard(show, ROWS, COLS, '*');
2.打印棋盘
在game.h中声明打印棋盘函数
//打印棋盘
void DisplayBoard(char board[ROWS][COLS], int row, int col);
在game.c中实现打印棋盘函数
void DisplayBoard(char board[ROWS][COLS], int row, int col)
{int i = 0;int j = 0;printf("------------扫雷------------\n");for (i = 0; i <= row; i++){printf("%d ", i);}printf("\n");for (i = 1; i <= row; i++){printf("%d ", i);for (j = 1; j <= col; j++){printf("%c ", board[i][j]);}printf("\n");}printf("------------扫雷------------\n");
}
3.布置雷
在game.h中声明布置雷函数
//布置雷
void SetMine(char mine[ROWS][COLS], int row, int col);
在game.c文件中实现布置雷函数,设置随机雷数EASY_COUNT,进入while循环每设置一个雷,EASY_COUNT减一,直到雷设置完毕跳出循环。为保证雷的随机性需生成随机坐标,判断设置雷是否重复,未重复设置雷”1“。
void SetMine(char board[ROWS][COLS], int row, int col)
{int count = EASY_COUNT;while (count){int x = rand() % row + 1;//x坐标为1-9int y = rand() % col + 1;//y坐标为1-9if (board[x][y] == '0'){board[x][y] = '1';}count--;}
}
随机数在game.h中进行宏定义
#define EASY_COUNT 10
调用rand()需要srand()
srand((unsigned int)time(NULL));
注:包含头文件
#include<stdlib.h>—>srand
#include<time.h>----->time
4.排查雷
在game.h文件中声明排查雷函数
//排查雷
void FindMine(char mine[ROWS][COLS],char show[ROWS][COLS], int row, int col);
在game.c中实现排查雷函数,输入坐标↔️确保坐标在棋盘范围内否则重新输入,判断棋盘范围内坐标是否重复输入,未重复输入判断是否踩雷,.若踩雷”很遗憾炸死“,若没有统计周围雷个数(用GetMineCount函数)。放入while循环,若雷没有排查完持续循环,若被炸死跳出循环。若所有雷被排查出则排雷成功
void FindMine(char mine[ROWS][COLS],char show[ROWS][COLS], int row, int col)
{int x = 0;int y = 0;int win = 0;while (win < row*col - EASY_COUNT){printf("请输入排查坐标>");scanf("%d %d", &x, &y);if (x >= 1 && x <= row && y >= 1 && y <= col){if (show[x][y] != '*'){printf("输入坐标重复,请重新输入\n");}else if (mine[x][y] == '1'){printf("很遗憾,你被炸死了\n");DisplayBoard(mine, ROW, COL);break;}else{//不是雷,就统计x,y坐标周围有几个雷int c = GetMineCount(mine, x, y);show[x][y] = c + '0';DisplayBoard(show, ROW, COL);win++;}}else{printf("输入坐标错误,请重新输入\n");}}if (win == row * col - EASY_COUNT){printf("排雷成功\n");DisplayBoard(mine, ROW, COL);}
}
在game.c文件中实现统计雷个数函数,因为在排查雷函数内部,不需在game.h文件中声明。因为坐标内输入的是字符‘0’,所以统计出个坐标数‘1’之和减去‘0’及为周围雷数
int GetMineCount(char mine[ROWS][COLS], int x, int y)
{return mine[x + 1][y] + mine[x - 1][y] +mine[x][y + 1] + mine[x][y - 1] +mine[x + 1][y + 1] + mine[x - 1][y + 1] +mine[x - 1][y - 1] + mine[x + 1][y - 1] - 8 * '0';
}
5.game()函数具体实现
1实现棋盘初始化,2打印棋盘,3设置棋盘雷数,4排查雷
void game()
{char mine[ROWS][COLS] = { 0 };char show[ROWS][COLS] = { 0 };InitBoard(mine, ROWS, COLS, '0');InitBoard(show, ROWS, COLS, '*');DisplayBoard(show, ROW, COL);SetMine(mine, ROW, COL);FindMine(mine, show, ROW, COL);
}
五.游戏运行实操
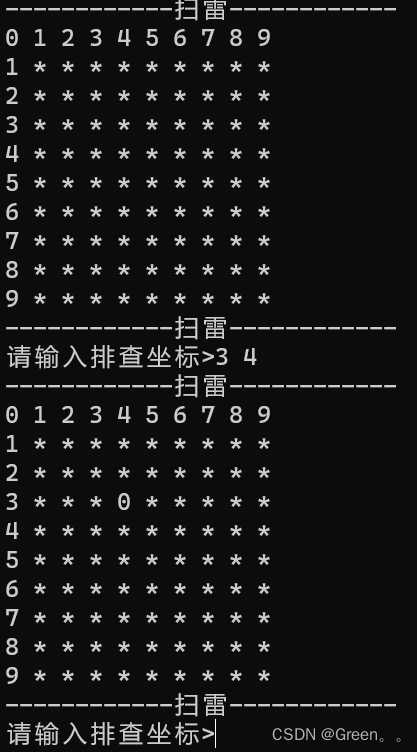
出现菜单进行选择
选1进入游戏
输入坐标开始游戏
坐标重复,重新输入
越界重新输入
踩雷炸死
选择0退出游戏





六.全部码源
test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"game.h"
void menu()
{printf("*************************\n");printf("******* 1. play ******\n");printf("******* 0. exit ******\n");printf("*************************\n");
}
void game()
{char mine[ROWS][COLS] = { 0 };char show[ROWS][COLS] = { 0 };InitBoard(mine, ROWS, COLS, '0');InitBoard(show, ROWS, COLS, '*');DisplayBoard(show, ROW, COL);SetMine(mine, ROW, COL);FindMine(mine, show, ROW, COL);
}
int main()
{srand((unsigned int)time(NULL));int input = 0;do{menu();printf("请输入选项>");scanf("%d", &input);switch (input){case 1:game();break;case 0:printf("退出游戏");break;default:printf("输入错误,请重新输入");break;}} while (input);return 0;
}
game.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"game.h"void InitBoard(char board[ROWS][COLS], int rows, int cols, char set)
{int i = 0;int j = 0;for (i = 0; i < rows; i++){for (j = 0; j < cols; j++){board[i][j] = set;}}
}void DisplayBoard(char board[ROWS][COLS], int row, int col)
{int i = 0;int j = 0;printf("------------扫雷------------\n");for (i = 0; i <= row; i++){printf("%d ", i);}printf("\n");for (i = 1; i <= row; i++){printf("%d ", i);for (j = 1; j <= col; j++){printf("%c ", board[i][j]);}printf("\n");}printf("------------扫雷------------\n");
}void SetMine(char board[ROWS][COLS], int row, int col)
{int count = EASY_COUNT;while (count){int x = rand() % row + 1;int y = rand() % col + 1;if (board[x][y] == '0'){board[x][y] = '1';}count--;}
}int GetMineCount(char mine[ROWS][COLS], int x, int y)
{return mine[x + 1][y] + mine[x - 1][y] +mine[x][y + 1] + mine[x][y - 1] +mine[x + 1][y + 1] + mine[x - 1][y + 1] +mine[x - 1][y - 1] + mine[x + 1][y - 1] - 8 * '0';
}void FindMine(char mine[ROWS][COLS],char show[ROWS][COLS], int row, int col)
{int x = 0;int y = 0;int win = 0;while (win < row*col - EASY_COUNT){printf("请输入排查坐标>");scanf("%d %d", &x, &y);if (x >= 1 && x <= row && y >= 1 && y <= col){if (show[x][y] != '*'){printf("输入坐标重复,请重新输入\n");}else if (mine[x][y] == '1'){printf("很遗憾,你被炸死了\n");DisplayBoard(mine, ROW, COL);break;}else{//不是雷,就统计x,y坐标周围有几个雷int c = GetMineCount(mine, x, y);show[x][y] = c + '0';DisplayBoard(show, ROW, COL);win++;}}else{printf("输入坐标错误,请重新输入\n");}}if (win == row * col - EASY_COUNT){printf("排雷成功\n");DisplayBoard(mine, ROW, COL);}
}
game.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<time.h>#define ROW 9
#define COL 9#define ROWS ROW + 2
#define COLS COL + 2#define EASY_COUNT 10//初始化棋盘
void InitBoard(char board[ROWS][COLS], int rows, int cols, char set);//打印棋盘
void DisplayBoard(char board[ROWS][COLS], int row, int col);//布置雷
void SetMine(char mine[ROWS][COLS], int row, int col);//排查雷
void FindMine(char mine[ROWS][COLS],char show[ROWS][COLS], int row, int col);
💘本次扫雷学习告一段落,扫雷详解+完整代码,反复阅读,坚持打码,相信你在不久的将来就会拿下扫雷,以扩展更高级代码。期待下次作品与大家见面!!!