服装销售网站建设策划书智能魔方网站
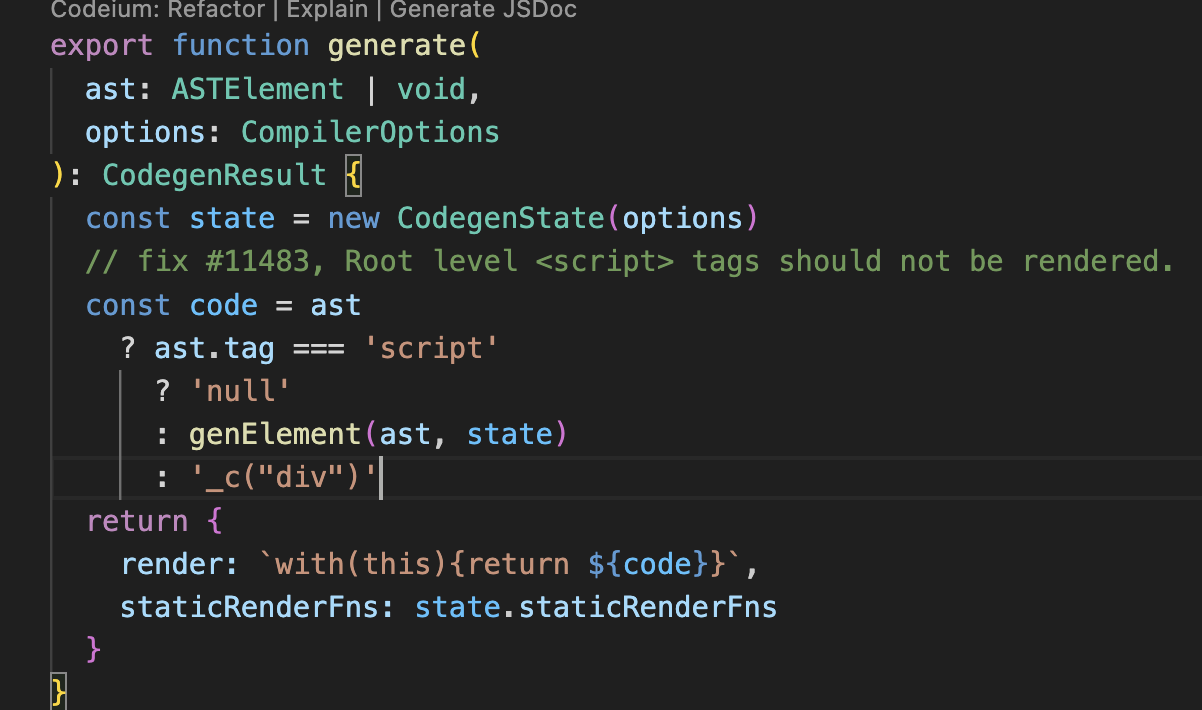
代码生成器是模版编译的最后以后,它的作用是将AST转换成渲染函数中的内容,这个内容可以称为代码字符串。
代码字符串可以被包装在函数中执行,这个函数就是我们通常说的渲染函数。
渲染函数被执行之后,可以生成一份VNode,而虚拟DOM可以通过这个VNode来渲染视图。
AST生成代码字符串
比如下面这个代码。
<div id="el">hello {{name}}
</div>
它转换成AST并且经过优化器的优化之后是下面这个样子。
{"type": 1,"tag": "div","attrsList": [{"name": "id","value": "el","start": 5,"end": 12}],"attrsMap": {"id": "el"},"rawAttrsMap": {"id": {"name": "id","value": "el","start": 5,"end": 12}},"children": [{"type": 2,"expression": "\"\\n hello \"+_s(name)+\"\\n \"","tokens": ["\n hello ",{"@binding": "name"},"\n "],"text": "\n hello {{name}}\n ","start": 13,"end": 41,"static": false}],"start": 0,"end": 47,"plain": false,"attrs": [{"name": "id","value": "\"el\"","start": 5,"end": 12}],"static": false,"staticRoot": false
}
代码生成器可以通过上面这个AST来生成代码字符串,生成后的代码字符串。
with (this) {return _c('div',{ attrs: { "id": "el" } },[_v("\n hello " + _s(name) + "\n ")])
}
仔细观察生成后的代码字符串,这是一个嵌套的函数调用。函数_c的参数中执行了函数_v,而_v的参数中又执行了_s。
这个字符串中_c其实是createElement的别名。createElement是虚拟DOM中所提供的方法,它的作用是创建虚拟节点,有三个参数,分别是:
- 标签名
- 一个包含模版相关属性的数据对象
- 子节点列表
调用createElement方法,我们可以得到一个VNode。
这也就是是渲染函数可以生成VNode的原因:渲染函数其实是执行了createElement,而createElement可以创建一个VNode。