想建立什么网站展示型网站建设模板
接前一篇文章:PAM从入门到精通(十二)
本文参考:
《The Linux-PAM Application Developers' Guide》
先再来重温一下PAM系统架构:

更加形象的形式:
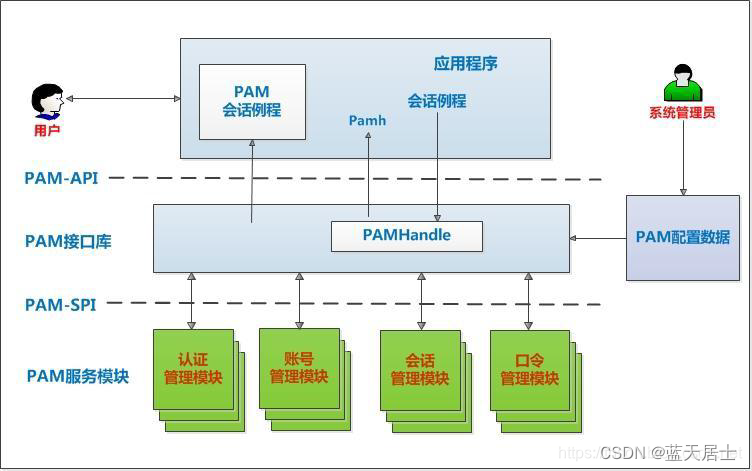
五、主要函数详解
11. pam_open_session
概述:
启动PAM会话管理。
函数声明:
#include <security/pam_appl.h>int pam_open_session ( pamh , flags );pam_handle_t * pamh ;int flags ;
详细描述:
pam_open_session函数为先前成功通过身份验证的用户设置用户会话。会话稍后应通过调用pam_close_session()来终止。
应该注意的是,应用程序的有效uid(通过geteuid()获得)应该具有足够的权限来执行例如创建或挂载用户主目录之类的任务。
参数说明:
- pam_handle_t *pamh
pamh参数是通过先前调用pam_start()获得的身份验证句柄。
- int flags
flags参数是以下值中的零个或多个的二进制或:
PAM_SILENT
不发出任何消息。
返回值:
- PAM_ABORT:一般故障。
- PAM_BUF_ERR:内存缓冲区错误。
- PAM_SESSION_ERR:会话失败。
- PAM_SUCCESS:会话已成功创建。
实例:
实例1. 一般性代码
/* 通过帐户管理检查之后则打开会话 */if (status = pam_open_session(pamh, 0) != PAM_SUCCESS)exit(status);
实例2. SDDM中的代码
参见SDDM包源码目录src/helper/backend/PamHandle.cpp中的PamHandle::openSession函数。
代码如下:
bool PamHandle::openSession() {m_result = pam_open_session(m_handle, m_silent);if (m_result != PAM_SUCCESS) {qWarning() << "[PAM] openSession:" << pam_strerror(m_handle, m_result);}m_open = m_result == PAM_SUCCESS;return m_open;}12. pam_close_session
概述:
终止PAM会话管理。
函数声明:
#include <security/pam_appl.h>int pam_close_session ( pamh , flags );pam_handle_t * pamh ;int flags ;
详细描述:
pam_close_session函数用于指示经过身份验证的会话已结束。会话应该是通过调用pam_open_session()创建的。
应该注意的是,应用程序的有效uid(通过geteuid()获得)应该具有足够的权限来执行例如卸载用户主目录之类的任务。
参数说明:
- pam_handle_t *pamh
pamh参数是通过先前调用pam_start()获得的身份验证句柄。
- int flags
flags参数是以下值中的零个或多个的二进制或:
PAM_SILENT
不发出任何消息。
返回值:
- PAM_ABORT:一般故障。
- PAM_BUF_ERR:内存缓冲区错误。
- PAM_SESSION_ERR:会话失败。
- PAM_SUCCESS:会话已成功终止。
实例:
实例1. 一般性代码
pam_end(pamh, PAM_SUCCESS); /* PAM事务的结束 */实例2. SDDM中的代码
参见SDDM包源码目录src/helper/backend/PamHandle.cpp中的PamHandle::closeSession函数。
代码如下:
bool PamHandle::closeSession() {m_result = pam_close_session(m_handle, m_silent);if (m_result != PAM_SUCCESS) {qWarning() << "[PAM] closeSession:" << pam_strerror(m_handle, m_result);}return m_result == PAM_SUCCESS;}更多函数请看后续文章。