乐山网站建设流程有没有做图的网站
1.1 什么是Apache Paimon
Apache Paimon的前身属于Flink的子项目:Flink Table Store。
目前业内主流的数据湖存储项目都是面向批处理场景设计的,在数据更新处理时效上无法满足流式数据湖的需求,因此Flink社区在2022年的时候内部孵化了 Flink Table Store (简称 FTS )子项目,一个真正面向流以及实时的数据湖存储项目。
Flink Table Store最开始是作为 Flink 的子项目加入了 Apache 社区的,由 Flink 团队主导研发,后期为了更好的发展,Flink Table Store作为独立项目重新加入 Apache。
在2023年3月12日,Flink Table Store项目顺利通过投票,正式进入 Apache孵化器,并且改名为 Apache Paimon (incubating),也可以简称为Paimon。
Apache Paimon 目前还属于incubating项目,表示正处于孵化阶段。
Apache Paimon的定位是一个流式数据湖平台,他提供了高速数据摄取、Changelog追踪、以及实时查询等能力。
这里面的数据摄取是指获取和导入数据的过程(或者说是读取和写入数据的过程)。
Apache Paimon提供了上层表抽象,使用方式和传统数据库类似。
- 在批处理模式下,它就像一个Hive表,支持批处理 SQL的各种操作。查询的时候默认会查询最新快照中的数据。
- 在流处理模式下,它就像一个消息队列。查询的时候就像从历史数据永不过期的消息队列中查询流更改日志一样。
1.2 Paimon的整体架构
Paimon的整体架构是这样的:
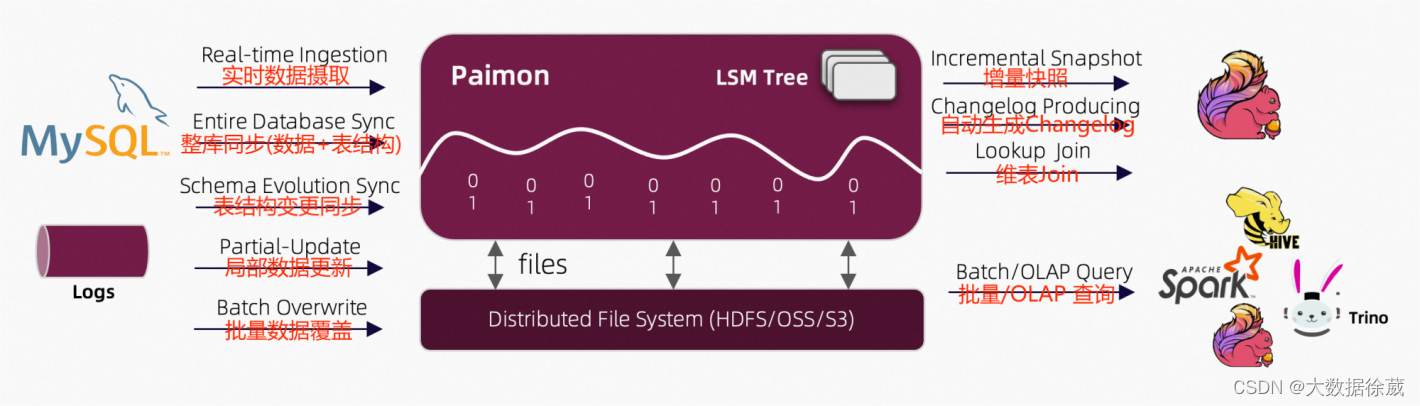
从这个图里面可以看出来,Paimon支持多种方式读写数据和执行OLAP查询。
在读取层面,他可以读取MySQL中的数据,以及消息队列中的数据。
在查询层面,Paimon除了可以和Flink进行交互,还可以和其他计算引擎进行交互,例如: Hive、Spark、Trino等引擎。
在底层,Paimon 会将列式文件存储在分布式文件系统中,例如HDFS、S3,并且内部使用LSM Tree这种数据结构来存储数据,所以可以支持大量数据更新和高性能查询。
1.3 Paimon的核心特点
Paimon主要包含下面这些核心特点:
1. 统一的批处理和流处理
Paimon支持批量写入、批量读取,流式写入、流式更新,以及流式读取。
2. 数据湖功能
作为数据湖存储系统,Paimon具有低成本、高可靠性、可扩展的元数据等特性。
3. 丰富的合并引擎
Paimon支持丰富的合并引擎,针对多条相同主键的数据,可以选择保留最后一条新数据、或者进行局部更新,或者进行聚合,都是可以支持的。
4. 自动生成变更日志
Paimon支持丰富的Changelog 生产者,可以自动从任何数据源生成正确完整的变更日志,简化流式任务的分析。
5. 丰富的表类型
Paimon可以支持主键表和仅追加表,主键表可以支持新增、更新和删除表中的数据。
仅追加表只能支持新增数据,但是可以提供有序的流式数据读取,进而可以替换消息队列。
同时Paimon中也支持内部表、外部表、分区表和临时表这些表类型。
6. 支持表结构变更同步(也可以称为Schema模式演变)
在向Paimon中同步数据时,当数据源表的表结构发生了变化的时候,Paimon可以自动识别并同步到这些变化。
1.4 Paimon支持的生态
Paimon最初来源于Flink,所以他和Flink的兼容度是最好的。
当然,除了Flink之外,他还支持Spark、Hive、Trino、Presto这些流行引擎的读写。
这里面还列出来了Paimon和这些引擎的版本兼容度,以及批量读取、批量写入、创建表、修改表、流式写入、流式读取、批量数据覆盖这些功能的支持情况。
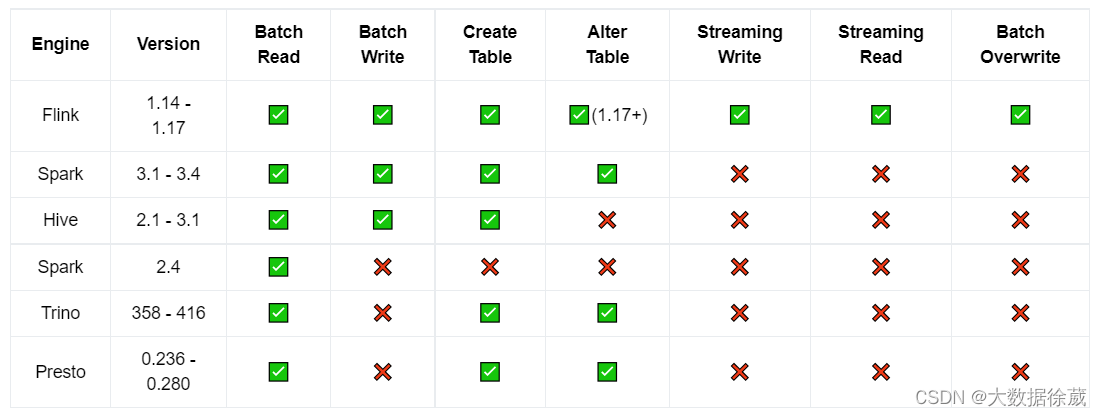
还有一些引擎目前不支持和Paimon进行交互,不过已经正在开发中了:例如:Doris、Seatunnel、Starrocks等等。
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html