淮南最新消息今天seo网站排名优化培训教程
【面试干货】throw 和 throws 的区别
- 1、throw
- 1.1 示例
- 2、throws
- 2.1 示例
- 3、总结
| 💖The Begin💖点点关注,收藏不迷路💖 |
在Java中,throw和throws都与异常处理紧密相关,但它们在使用和含义上有明显的区别。
1、throw
throw 语句用于在方法体内明确地抛出一个异常。 当throw语句被执行时,它会立即终止当前方法的执行,并将指定的异常对象传递给调用该方法的代码。
重要概念:
-
throw 是具体向外抛出异常的动作:它抛出的是一个异常实例。 -
执行 throw 一定是抛出了某种异常:在throw语句后,代码的执行会立即中断,并跳转到相应的异常处理代码(如catch块)。
1.1 示例
package com.example;public class ExceptionExample {public static void main(String[] args) {// 创建一个实例并调用可能抛出异常的方法// 注意:传递true来触发IllegalArgumentException异常ExceptionExample example = new ExceptionExample();example.exampleMethod(true); // 传递true以触发异常// 也可以尝试 example.exampleMethod(false); 来避免异常}public void exampleMethod(boolean someCondition) {try {// 假设这里有一些可能引发异常的代码if (someCondition) {// 如果someCondition为true,则抛出IllegalArgumentException异常// 提示:当someCondition为true时,将抛出异常throw new IllegalArgumentException("无效的参数");}// 如果someCondition为false,则不会抛出异常,并且可以继续执行下面的代码(如果有的话)// 提示:当someCondition为false时,不会抛出异常} catch (IllegalArgumentException e) {// 捕获IllegalArgumentException异常并打印堆栈跟踪// 提示:捕获到IllegalArgumentException异常,打印堆栈跟踪e.printStackTrace();}// 注意:catch块之后的代码将在捕获异常后继续执行,除非在catch块中再次抛出异常或遇到return语句// 提示:无论是否捕获到异常,此处的代码都会执行System.out.println("在可能的异常之后,方法继续执行。");}
}

由于main方法中调用exampleMethod时传递了true,因此会触发IllegalArgumentException,会在控制台看到异常的堆栈跟踪信息,并且随后会输出“在可能的异常之后,方法继续执行。”。
如果将main方法中的exampleMethod(true)改为exampleMethod(false),则不会抛出异常,并且只会输出“在可能的异常之后,方法继续执行。”。

2、throws
throws 关键字用于在方法声明中声明该方法可能会抛出的异常类型。
这并不意味着该方法一定会抛出这些异常,但它告诉方法的调用者需要准备处理这些类型的异常。
重要概念:
-
throws 主要是声明这个方法会抛出某种类型的异常:它允许方法的调用者知道需要捕获哪些类型的异常。
-
throws 表示出现异常的一种可能性:它并不保证方法在执行过程中一定会抛出这些异常。
2.1 示例
示例展示了如何在Java中定义一个可能抛出IOException的方法,并在该方法中模拟执行可能引发IOException的代码。当这个方法被调用时,如果发生IOException,调用者需要处理这个异常,或者继续向上抛出。
package com.example;
import java.io.IOException;public class ExceptionHandlingExample {// 定义一个可能抛出IOException的方法public void anotherExampleMethod() throws IOException {try {// 假设这里我们试图打开一个文件,但文件不存在,或者我们没有读取文件的权限// 这将会抛出IOException// new FileInputStream("nonexistentfile.txt");// 为了演示,我们直接抛出一个IOExceptionthrow new IOException("模拟的IO异常");} catch (IOException e) {// 在这个方法内部,我们选择处理这个异常// 但由于我们声明了throws IOException,所以我们选择不处理它,而是将它抛出throw e; // 或者使用 throw new IOException("新的错误信息", e); 来包装并重新抛出} finally {// finally块中的代码无论是否发生异常都会执行// 这是一个清理资源的好地方,比如关闭文件流或数据库连接System.out.println("finally块中的代码被执行了,用于清理资源。");}// 注意:由于我们在catch块中重新抛出了异常,所以这里的代码不会被执行// 因此,这行代码将会导致“无法访问的语句”编译错误// System.out.println("如果没有异常,这行代码将被执行。"); // 这行代码应该被删除或移到try块内部}public static void main(String[] args) {ExceptionHandlingExample example = new ExceptionHandlingExample();try {// 调用可能抛出IOException的方法example.anotherExampleMethod();} catch (IOException e) {// 在main方法中处理异常e.printStackTrace();System.out.println("捕获到了IOException,并进行了处理。");}// 注意:即使anotherExampleMethod抛出了异常,main方法中的后续代码仍然可以执行System.out.println("main方法继续执行...");}
}
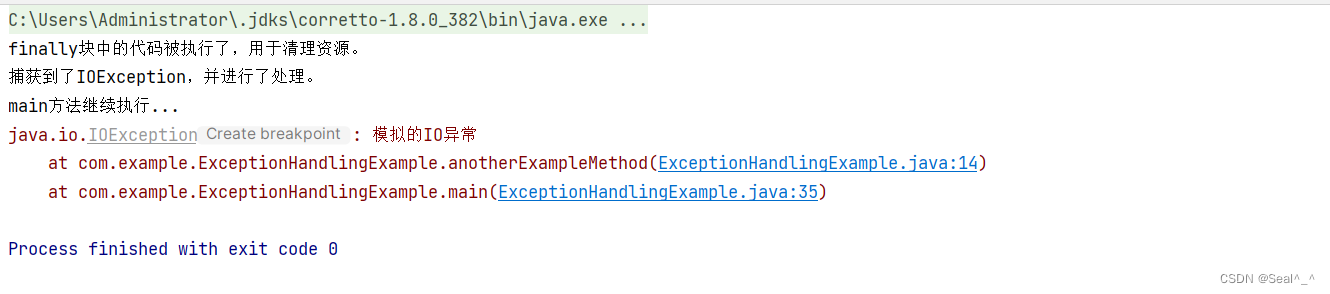
anotherExampleMethod方法中抛出了一个IOException,并且这个异常被main方法中的catch块捕获并处理了。
当Java代码抛出一个异常且这个异常没有被立即捕获时,JVM(Java虚拟机)会开始寻找一个能够处理这个异常的catch块。
它首先会在抛出异常的try块中查找,如果没有找到,就会沿着方法调用栈向上查找,直到找到一个能够处理这个异常的catch块,或者直到到达方法调用栈的顶部(即程序的最顶层),这时JVM会终止程序并打印出未捕获的异常信息。
3、总结
1、throw 是实际抛出异常的动作,它中断方法的执行并传递异常对象。
2、throws 是声明方法可能会抛出的异常类型,它告诉方法的调用者需要准备处理这些异常。

| 💖The End💖点点关注,收藏不迷路💖 |