阿里云做网站开发吗wordpress4.7.3下载
leetcode 25
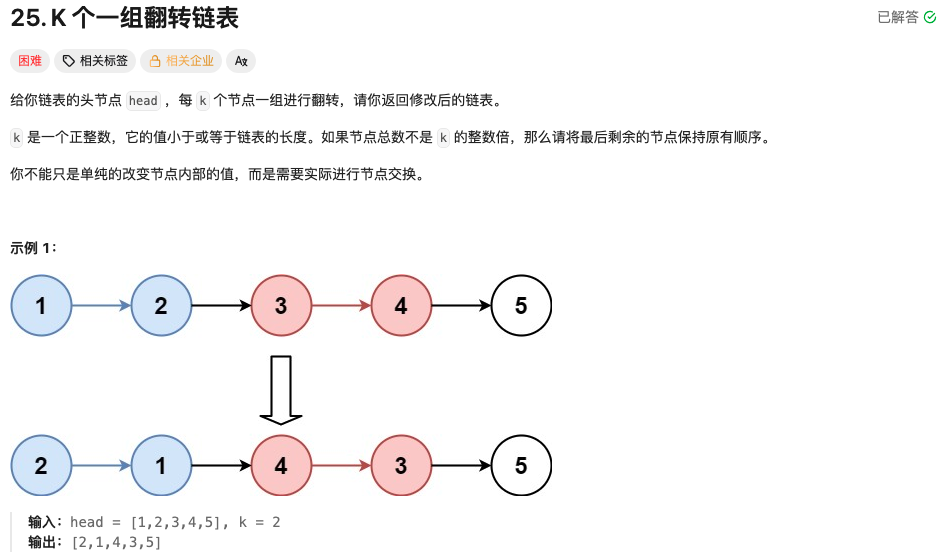
思路
整体思路
解题的核心在于确定每 k 个节点的组,然后对组内节点进行翻转操作,并将翻转后的组正确连接回原链表。为了方便处理,我们引入一个虚拟头节点 dummy ,它的 next 指向链表的真正头节点 head 。这样做的好处是,在处理头节点时可以避免特殊情况的判断,统一代码逻辑
快慢指针的运用
我们使用了快慢两个指针,slow 指针初始指向 dummy ,fast 指针初始指向 dummy.next (即链表的头节点)。fast 指针的作用是向前移动 k 个节点,判断当前组是否有足够的 k 个节点。如果 fast 指针在移动 k 步的过程中遇到了 null ,说明剩余节点不足 k 个,此时直接返回 dummy.next ,因为剩余部分不需要翻转。如果 fast 指针顺利移动了 k 步,说明当前组有足够的节点,可以进行翻转操作
链表翻转操作
当确定当前组有 k 个节点后,我们开始进行链表翻转。设 cur 指针指向当前组的第一个节点(即 slow.next ),pre 指针指向当前组的下一组的第一个节点(即 fast )。通过循环 k 次,不断调整指针指向来实现节点的翻转。每次循环中,先保存 cur 的下一个节点 node ,然后将 cur 的 next 指向 pre ,更新 pre 为 cur ,再将 cur 移动到 node 。循环结束后,当前组的节点顺序就完成了翻转
反转链表可以参考另一篇博客:leetcode206反转链表
重新连接链表
完成一组节点的翻转后,需要将翻转后的组重新连接到原链表中。此时,slow.next 应该指向翻转后的组的头节点(即 pre ),然后将 slow 移动到当前组的尾节点(即翻转前的第一个节点,也就是 temp ),以便下一次循环时处理下一组节点
时间复杂度:O(n) 空间复杂度:O(1)
实现
var reverseKGroup = function (head, k) {if (!head || k === 1) return head;let dummy = { val: 0, next: head }let slow = dummy, fast = dummy.next;while (fast) {for (let i = 0; i < k; i++) {if (fast) {fast = fast.next} else {// 剩余元素不足k个return dummy.next;}}let cur = slow.next, pre = fast;for (let i = 0; i < k; i++) {// 进行反转const node = cur.next;cur.next = pre;pre = cur;cur = node;}const temp = slow.next;slow.next = pre;slow = temp;}return dummy.next;
};