上海传媒公司ceo是谁郑州网站seo多少钱
文章目录
- 编译环境
- 基本类型
- 函数类型
- 函数重载
- 联合类型和函数重载
编译环境
TypeScript最终会被编译成JavaScript来运行,所以我们需要搭建对应的环境。
首先我们要全局安装typescript
# 安装命令
npm install typescript -g
# 查看版本
tsc --version

⭐️ 方式一:通过webpack,配置本地的TypeScript编译环境和开启一个本地服务,可以直接运行在浏览器上
- 安装webpack相关的依赖
使用webpack开发和打开,需要依赖webpack、webpack-cli、webpack-dev-server
npm install webpack webpack-cli webpack-dev-server -D
- 在package.json中添加启动命令
为了方便启动webpack,我们在package.json中添加如下启动命令
"scripts": {"test": "echo \"Error: no test specified\" && exit 1","serve": "cross-env NODE_ENV=development webpack-dev-server --mode=development --config build/webpack.config.js"
},
- 添加webpack的其他相关依赖
依赖一:cross-env
这里我们用到一个插件 “cross-env” ,这个插件的作用是可以在webpack.config.js中通过 process.env.NODE_ENV 来获取当前是开发还是生产环境,我们需要这个插件:
npm install cross-env -D
依赖二:ts-loader
因为我们需要解析.ts文件,所以需要依赖对应的loader:ts-loader
npm install ts-loader -D
依赖三:html-webpack-plugin
编译后的代码需要对应的html模块作为它的运行环境,所以我们需要使用html-webpack-plugin来将它插入到对应的模板中:
npm install html-webpack-plugin -D
- 配置webpack.config.js文件
const HtmlWebpackPlugin = require("html-webpack-plugin");module.exports = {entry: "./src/main.ts",output: {filename: "build.js",},resolve: {extensions: [".tsx", ".ts", ".js"],},module: {rules: [{test: /\.tsx?$/,use: "ts-loader",exclude: /node_modules/,},],},devtool: process.env.NODE_ENV === "production" ? false : "inline-source-map",devServer: {static: "./dist",// stats: "errors-only",compress: false,host: "localhost",port: 8080,},plugins: [new HtmlWebpackPlugin({template: "./index.html",}),],
};
下面我们就可以愉快的在main.ts中编写代码,之后只需要启动服务即可:
在终端中启动服务:npm run serve
方式一: 参考文章:
TypeScript(二)使用Webpack搭建环境
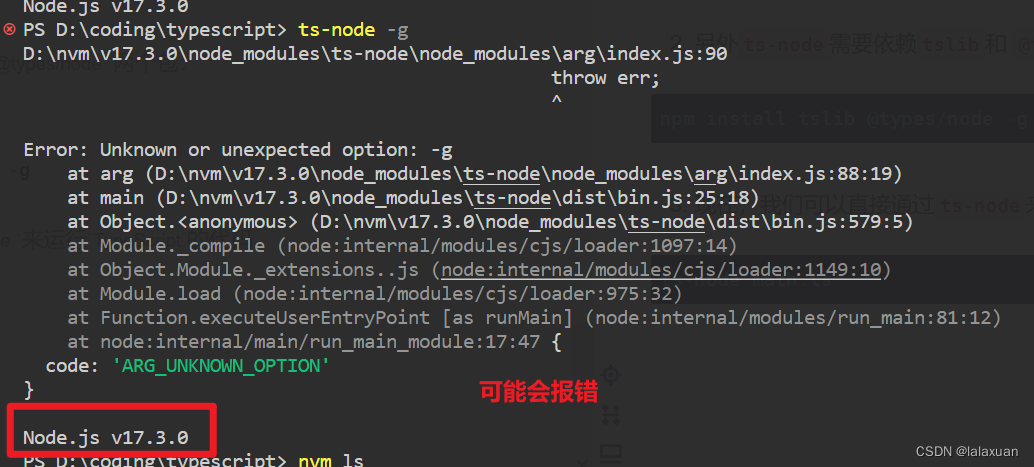
⭐️ 方式二:通过ts-node库,为TypeScript的运行提供执行环境
- 安装ts-node
npm install ts-node -g
- 另外
ts-node需要依赖tslib和@types/node两个包:
npm install tslib @types/node -g
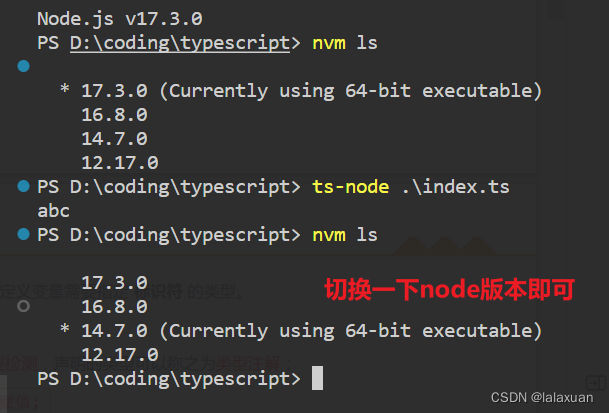
- 现在,我们可以直接通过
ts-node来运行TypeScript的代码
ts-node math.ts
基本类型
// number类型
let num: number = 100;
// string类型
let msg: string = "abc"; // 一般这种可以不写类型注解
// boolean类型
let flag: boolean = true;
// null undefined
let n: null = null;
let u: undefined = undefined;// Array类型
let arr1: string[] = ["abc", "123"];
let arr2: Array<string> = ["aaaa", "ccc"];// Object类型
let obj: {name: string;age: number;
} = {name: "zhangsan",age: 18,
};
console.log(obj.age);// Symbol类型
const s1: symbol = Symbol("title");
const s2: symbol = Symbol("title");const person = {[s1]: "程序员",[s2]: "老师",
};// any
let a: any = "why";
a = 123;let flag = true;
function foo(): string {return "foo";
}
function bar(): number {return 123;
}
// unknow
let result: unknown;
if (flag) {result = foo();
} else {result = bar();
}// void
function sum(num1: number, num2: number): void {console.log(num1 + num2);
}
// never类型 永远不会发生值的类型
// tuple
const tInfo: [string, number, number] = ["abc", 18, 22];export {};函数类型
// 函数的参数类型注解
function greet(name: string) {console.log("hello" + name.toUpperCase());
}console.log(greet("world"));// 函数的返回值类型
function sum(num1: number, num2: number): number {return num1 + num2;
}const names = ["abc", "cba", "nba"];
// 并未指定item的类型 但是item是string类型
names.forEach((item) => {console.log(item.toUpperCase());
});// 函数接收的参数是一个对象 z?可选类型
function printCoordinate(point: { x: number; y: number; z?: number }) {console.log("x坐标", point.x);console.log("y坐标", point.y);
}
printCoordinate({ x: 10, y: 30 });// 联合类型
type ID = number | string;
// function printId(id: number | string) {
function printId(id: ID) {console.log("你的id是:", id);
}
printId(10);
printId("abc");// 类型断言
const myEl = document.getElementById("my-img") as HTMLElement;
// const myEl = document.getElementById("my-img") as HTMLImageElement;// 非空类型断言! 确定某个标识符是有值的
function printMsg(message?: string) {console.log(message!.toUpperCase());
}// ??和!!的作用
// 将一个其他类型转换成 boolean类型
// ?? 逻辑操作符 左侧是null或者undefined时, 返回其右侧操作数函数重载
// 函数重载
// 如果编写了一个add函数,希望可以对字符串和数字类型进行相加
// 应该如何编写?
// 以下是错误方式:
// function sum(a1: number | string, a2: number | string): number | string {
// return a1 + a2;
// }// 正确方式:
function sum(a1: number, a2: number): number;
function sum(a1: string, a2: string): string;
function sum(a1: any, a2: any): any {return a1 + a2;
}
console.log(sum(10, 20));
console.log(sum("aa", "bb"));export {};
联合类型和函数重载
// 联合类型和重载
// 需求:定义一个函数,可以传入字符串或者数组,获取它们的长度
// 1. 联合类型
function getLength(a: string | any[]) {return a.length;
}
// 2. 函数重载
function getLength(a: string): number;
function getLength(a: any[]): number;
function getLength(a: any) {return a.length;
}