学网站建设与管理有用吗wordpress 文件发送邮件
先说一下自己的情况,大专生,18年通过校招进入武汉某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试,已经让我变得不思进取,谈了2年的女朋友也因为我的心态和工资和我分手了。于是,我决定要改变现状,冲击下大厂。

刚开始准备时,自己都蒙了,四年的功能测试让我的技术没有一丝的进步,提升的只有我的年龄…
没办法,我找到了我在腾讯的老哥,作为他的小老表,在他了解了我的情况后(几乎就是软件测试基础开始),直接甩给我一个网盘,说到:“去吧,这里有你需要的所有东西,不要来找我了,我都嫌丢人!”。
盘里头是一整套软件测试面试必备文档PDF,看完之后直接给我老哥给跪了…这下面试稳了。
内容涵盖:包括测试理论、Linux基础、MySQL基础、Web测试、接口测试、App测试、管理工具、Python基础、Selenium相关、性能测试、LordRunner相关等… 质量非常高,需要的可自行领取!!
全网首发-涵盖16个技术栈
- 第一部分,测试理论(测试基础+需求分析+测试模型+测试计划+测试策略+测试案例等等)
- 第二部分,Linux( Linux基础+Linux练习题)
- 第三部分,MySQL(基础知识+查询练习+万年学生表经典面试题汇总+数据库企业真题)
- 第四部分,Web测试
- 第五部分,API测试
- 第六部分,App测试
- 第七部分,管理工具
- 第八部分,Python基础(Python基础+编程题+集合+函数+Python特性等等)
- 第九部分,Selenium相关
- 第十部分,性能测试
- 第十一部分,LordRunner相关
- 第十二部分,计算机网络
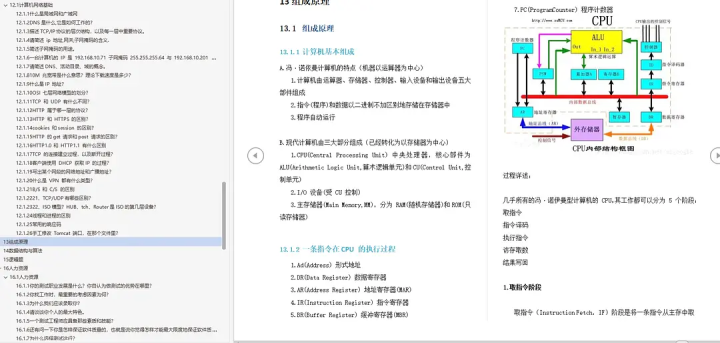
- 第十三部分,组成原理
- 第十四部分,数据结构与算法
- 第十五部分,逻辑题
- 第十六部分,人力资源
-
软件测试基础
- 软件测试的步骤是什么?
- 如何录制测试脚本?
- 应该考虑进行如何测试的测试方法
- 怎样估计测试工作量?
- 测试设计的问题
- 当测试过程发生错误时,有哪几种解决办法?
- 测试执行的问题
- 测试评估的目标
- 如何提高测试?
- C/S模式的优点和缺点
- B/S模式的优点和缺点
- …

-
Linux
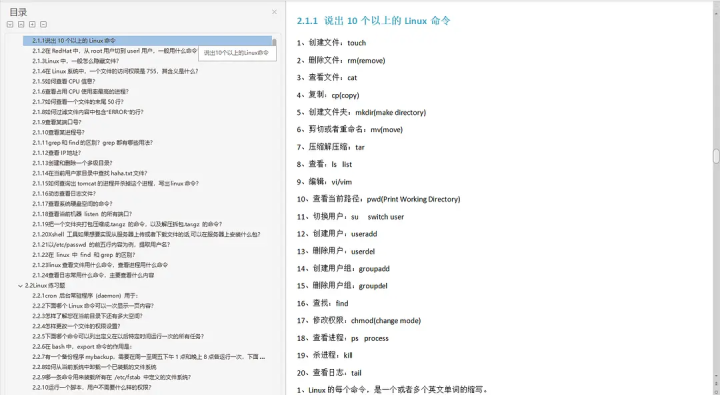
- grep和find的区别? grep 都有哪些用法?
- 查看IP地址?
- 创建和删除一个多级目录?
- 在当前用户家目录中查找haha.txt文件?
- 如何查询出tomcat的进程并杀掉这个进程,写出linux命令?
- 动态查看日志文件?
- 查看系統硬盘空间的命令?
- 查看当前机器listen 的所有端口?
- …
-
Python
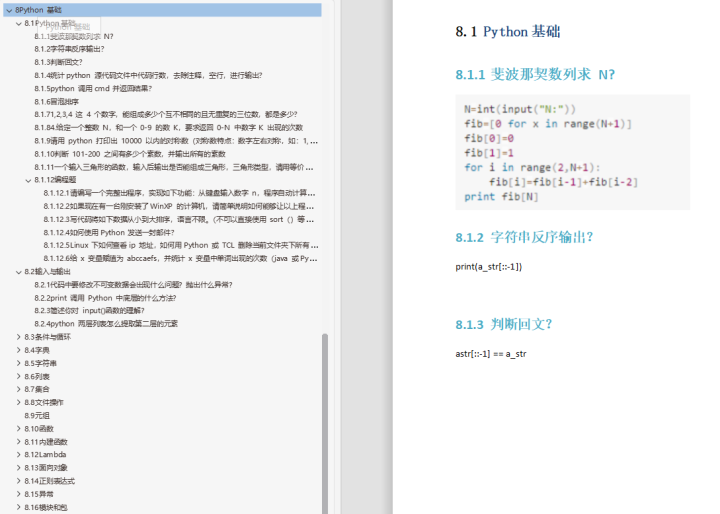
- 统计python源代码文件中代码行数,去除注释,空行,进行输出?
- python调用cmd并返回结果?
- 冒泡排序
- 1,2,3,4 这4个数字,能组成多少个互不相同的且无重复的三位数,都是多少?
- 请用 python 打印出 10000 以内的对称数(对称数特点:数字左右对称,如:1,2,11,121,1221 等)
- 给定一个整数 N,和一个 0-9 的数 K,要求返回 0-N 中数字 K 出现的次数
- 判断 101-200 之间有多少个素数,并输出所有的素数
- 一个输入三角形的函数,输入后输出是否能组成三角形,三角形类型,请用等价类- 划分法设计测试用例
- …
-
MySQL
- 你用的Mysql是哪个引擎,各引擎之间有什么区别?
- 如何对查询命令进行优化?
- 数据库的优化?
- Sql注入是如何产“生的,如何防止?
- NoSQL和关系数据库的区别?
- MySQL与MongoDB本质之间最基本的差别是什么
- Mysql数据库中怎么实现分页?
- Mysql数据库的操作?
- 优化数据库?提高数据库的性能?
- 什么是数据的完整性?
- …

-
Web
- Web测试和app测试区别?
- WEB测试环境搭建和测试方法
- WEB测试教程
- WEB测试要点及基本方法
- Web测试页面总结
- …

-
接口测试
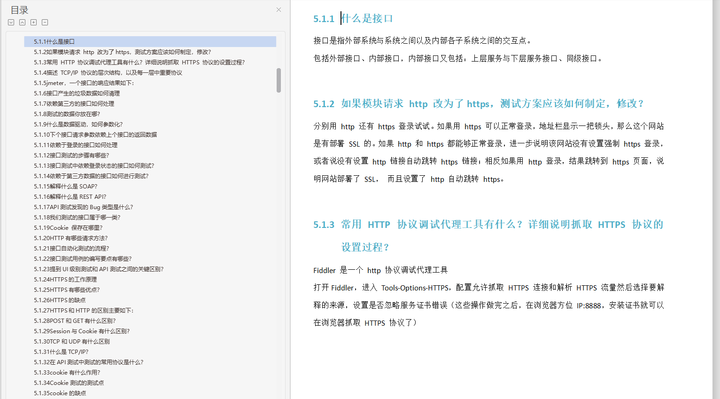
- 什么是接口
- 如果模块请求http改为了https,测试方案应该如何制定,修改?
- 常用HTTP 协议调试代理I具有什么?详细说明抓取HTTPS协议的设置过程?
- 描述TCP/IP协议的层次结构,以及每一-层中重要协议
- jmeter,一个接口的响应结果如下:
- 接口产生的垃圾数据如何清理
- 依赖第三方的接口如何处理
- 测试的数据你放在哪?
- 什么是数据驱动,如何参数化?
- …
-
性能测试
- 你认为性能测试的目的是什么?做好性能测试的工作的关键是什么?
- 服务端性能分析都从哪些角度来进行?
- 如何理解压力测试,负裁测试以及性能测试?
- 如何判断是否有内存泄漏及关注的指标?
- 描述软件产“生内存泄露的原因以及检查方式。(可以结合- 种开发语言进行描述)
- 简述什么是值传递,什么是地址传递,两者区别是什么?
- 什么是系统瓶颈?
- …

-
selenium
- 如何开展自动化测试框架的构建?
- 如何设计自动化测试用例:
- webdriver如何开启和退出一个浏览器?
- 什么是自动化测试框架?
- Selenium是什么,流行的版本有哪些?
- 你如何从命令行启动Selenium RC?
- 在我的机器端口4444不是免费的。我怎样才能使用另一个端口?
- 什么是Selenium Server,它与Selenium Hub有什么不同?
- 你如何从Selenium连接到数据库?
- 你如何验证多个页面上存在的一个对象?
- XPath中使用单斜杠和双斜杠有什么区别?
- 如何编写SeleniumIDE/ RC的用户扩展?
- 如何在页面加载成功后验证元素的存在?
- 你对Selenium Grid有什么了解?它提供了什么功能?
- 如何从你的Java Class启动Selenium服务器?
- Selenium中有哪些验证点?
- 什么是XPath?什么时候应该在Selenium中使用XPath?
- …
-
计算机与网络
- 一台计算机的IP是192.168.10.71子网掩码255.255.255.64与192.168.10.201 …
- 请简述DNS、活动目录、域的概念。
- 10M兆宽带是什么意思?理论下载速度是多少?
- 什么是IP地址?
- OSI七层网络模型的划分?
- TCP和UDP有什么不同?
- HTTP属于哪一层的协议?
- HTTP和HTTPS的区别?
- cookies和session的区别?
- HTTP的get请求和post请求的区别?
- HTTP1.0和HTTP1.1有什么区别
- TCP的连接建立过程,以及断开过程?
- 客户端使用DHCP获取IP的过程?
- 写出某个网段的网络地址和广播地址?
- …

-
-
人力资源
- 你的测试职业发展是什么?你自认为做测试的优势在哪里?
- 你找工作时,最重要的考虑因素为何?
- 为什么我们应该录取你?
- 请谈谈你个人的最大特色。
- 一个测试工程师应具备那些素质和技能?
- 还有问一下你是怎样保证软件质量的,也就是说你觉得怎样才能最大限度地保证软件质量?
- 为什么选择测试这行?
- 如果我雇用你,你能给部门带来什么贡献?
- …

-
最后
- 整份文档一共有将近 200 页,全部为大家展示出来肯定是不太现实的,为了不影响大家的阅读体验就只展示了部分内容,还望大家海涵,希望能帮助到您面试前的复习且找到一个好的工作,也节省大家在网上搜索资料的时间来学习!