建e网站甘肃兰州是几线城市
目录
2.18 综合应用-1
2.19 综合应用-2
2.20 综合应用-3
2.21 综合应用-4
2.22 综合应用-5
Synchronized :
2.18 综合应用-1
反射的高级应用
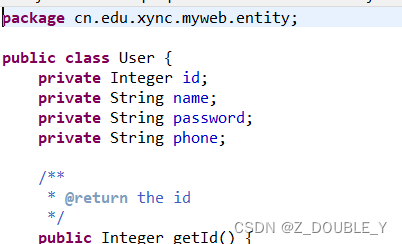
DAO开发中,实体类对应DAO的实现类中有很多方法的代码具有高度相似性,为了提供代码的复用性,降低冗余度,可以通过反射的方式可以定义一个公共的DAO,只要提供实体类名,就可以得到对应数据库表中的所有记录。
用到的知识点:
(1)JDBC的基本操作
(2)单例设计模式
(3)数据库结果集对应的元数据(ResultSetMeteDate)
(4)反射
命名的规范化要求:
(1)实体类类名每个首字母大写,数据库表字段名称要与实体类属性名称一致,数据库表中字段命名的时候每个单词首字母要大写。
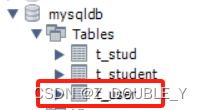
(2)数据库表命名以“t_”开头,后面跟对应的实体类名称,首字母小写。
源码:
package cn.edu.xync.myweb.reflect;import java.lang.reflect.Method;
import java.security.Timestamp;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;class JDBCUtil{private static JDBCUtil util=null;//定义私有的静态成员private JDBCUtil() {//加载驱动try {Class.forName("com.mysql.cj.jdbc.Driver");} catch (ClassNotFoundException e) {e.printStackTrace();}}public static JDBCUtil getInstance() {//判断util这个静态成员属性有没有被实例化synchronized(JDBCUtil.class) {if(util==null) {util=new JDBCUtil();//实例化}return util;} }public Connection getConnection() throws SQLException {//返回链接对象return DriverManager.getConnection("jdbc:mysql://localhost:3306/mysqldb?characterEncoding=UTF-8","root","1234567890");}public void close(ResultSet rs, Statement stmt, Connection con) {try {if (rs != null) // 关闭并释放资源rs.close();if (stmt != null)stmt.close();if (con != null)con.close();} catch (SQLException e) {e.printStackTrace();}}
}JDBCUtil使用了封装类并使用了单例设计模式
2.19 综合应用-2
class CommonDAO {// 定义公共的DAO/** 根据实体类名将其对应的数据库表中所有的记录封装成实体类集合返回 说明:数据库表字段名称要与实体类属性名称一致,数据库表中字段命名的时候每个单词首字母要大写*/public List getBeans(String beanName) throws Exception {// 得到对应的数据库表名称String tableName = this.getTableName(beanName);System.out.println(tableName);String sql = "select * from " + tableName;// select * from t_accountList lists = new ArrayList();// 把表里的每一行转换成实体类存放在集合里JDBCUtil util = JDBCUtil.getInstance();try {Connection con = util.getConnection();Statement stmt = con.createStatement();ResultSet rs = stmt.executeQuery(sql);ResultSetMetaData rsmd = rs.getMetaData();// 结果集元数据:通过它能够知道结果集对应的表有几列,// 这些列的名称,数据类型等信息都在结果集元数据当中// 得到当前表共有几个字段int columnCount = rsmd.getColumnCount();while (rs.next()) {// 对结果集遍历,每执行一次就要通过反射的方法把对应的实体类的clazz对象创建出来// 实体类必须放到cn.xysfxy.sprintboot.entity包中Class clazz = Class.forName("cn.edu.xync.myweb.entity." + beanName);// 实例化对象Object obj = clazz.newInstance();//对列进行循环
for (int i = 1; i <= columnCount; i++) {System.out.println(rsmd.getColumnName(i));// 拿到列名System.out.println(rsmd.getColumnTypeName(i));// 拿到列对应的数据类型的名称// 将数据表字段第一个字母转换成大写,为下边拿到setXXX方法使用String methodName = this.firstCharToUppercase(rsmd.getColumnName(i));// 根据反射调用setXXX方法给实体类对象属性赋值Method method = clazz.getDeclaredMethod("set" + methodName,this.getAttributeClassType(rsmd.getColumnTypeName(i)));
//得到setId方法传入的java类型// setIdmethod.invoke(obj, rs.getObject(i));//传值}lists.add(obj);// 添加到集合里}} catch (SQLException e) {e.printStackTrace();}return lists;}// 根据数据库表中某个列的数据类型返回对应的Java数据类型的Class对象private Class getAttributeClassType(String columnType) {Class clazz = null;if ("VARCHAR".equalsIgnoreCase(columnType))clazz = String.class;if ("INT".equalsIgnoreCase(columnType))clazz = Integer.class;if ("Float".equalsIgnoreCase(columnType))clazz = Float.class;if ("DATETIME".equalsIgnoreCase(columnType))clazz = Timestamp.class;return clazz;}// 将数据表列名第一个字母转换成大写private String firstCharToUppercase(String columnName) {String uppercaseString = columnName.toUpperCase();char firstChar = uppercaseString.charAt(0);String firstCharString = String.valueOf(firstChar);return firstCharString.concat(columnName.substring(1, columnName.length()));}/** 根据实体类名称得到对应的数据表名称 命名必须遵守的规范 例如Account,对应的表名称为t_account*/private String getTableName(String beanName) {char oldFirstChar = beanName.charAt(0);// 实体类名首字母先转换成字符串形式,再转换成小写String newFirstChar = String.valueOf(oldFirstChar).toLowerCase();// 拼接字符串String tableName = "t_" + beanName.replaceFirst(String.valueOf(oldFirstChar), newFirstChar);//替换字符return tableName;// 把Account-->t_account}
}2.20 综合应用-3
2.21 综合应用-4
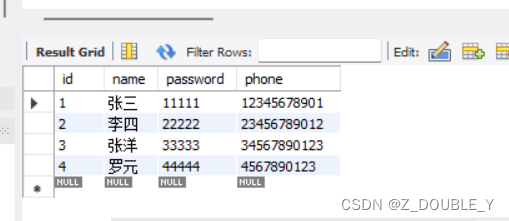
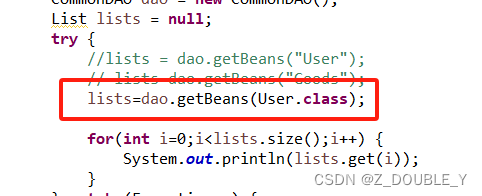
public class GenericTest {public static void main(String[] args) {CommonDAO dao = new CommonDAO();List lists = null;try {lists = dao.getBeans("User");// lists=dao.getBeans("Goods");for(int i=0;i<lists.size();i++) {System.out.println(lists.get(i));}} catch (Exception e) {e.printStackTrace();}}
}运行结果:

总结:这是通过反射和JDBC结果集元数据相结合的一个例子,目的:减少代码的冗余,提高代码的复用性
2.22 综合应用-5
一般我们不会去传递类的名称,我们都是传递类的Class对象
applicationContext.getBean(XXX.class)
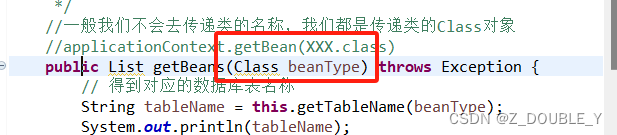

private String getTableName(Class beanType) {//String beanNameWithPackage=beanType.getName();//得到的类名包含了package信息String beanName=beanType.getSimpleName();//得到AccountSystem.out.println(beanName);
// //cn.xxx.xxx.Account
// System.out.println(beanNameWithPackage);
// String subName[] =beanNameWithPackage.split("\\.");//按.转义拆分成字符串数组
// String beanName=subName[subName.length-1];//拿到最后一个字符串char oldFirstChar = beanName(0);// 实体类名首字母先转换成字符串形式.charAt,再转换成小写String newFirstChar = String.valueOf(oldFirstChar).toLowerCase();// 拼接字符串String tableName = "t_" + beanName.replaceFirst(String.valueOf(oldFirstChar), newFirstChar);return tableName;// 把Account-->t_account}//因为我们传递进来的就是Class对象,所以直接调用newInstance()方法就行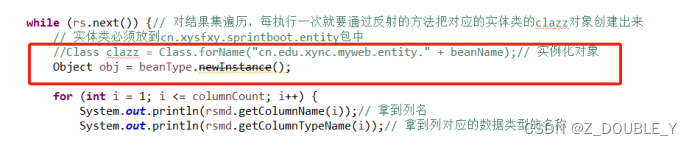

运行结果:

Synchronized :
当多个并发线程(thread1和thread2)访问同一个对象(ThreadSyn)中的synchronized代码块时,就相当于对这个代码块加了锁,在同一时刻只能有一个线程得到执行,其他线程受阻塞,必须等待当前线程执行完这个代码块以后才能执行该代码块。
当多个线程访问 不同对象 的同步代码块,线程访问各自同步代码块,线程不会阻塞,互不干扰。
总结
1、无论synchronized关键字加在方法上还是对象上,如果它作用的对象是非静态的,则它取得的锁是对象;如果synchronized作用的对象是一个静态方法或一个类,则它取得的锁是对类,该类所有的对象同一把锁。
2、每个对象只有一个锁(lock)与之相关联,谁拿到这个锁谁就可以运行它所控制的那段代码。
3、实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。