北京 公司网站制作免费个人网站建站源码
时序反馈移位寄存器建模
- 1,阻塞赋值实现的LFSR,实际上并不具有LFSR功能
- 1.1.1,RTL设计,阻塞赋值
- 1.1.2,tb测试代码
- 1.1.3,波形仿真输出,SIM输出,没实现LFSR
- 1.2.1,RTL设计,非阻塞赋值
- 1.2.2,RTL设计,非阻塞赋值
- 1.2.3,波形功能实现,LFSR
- 三级目录
1,阻塞赋值实现的LFSR,实际上并不具有LFSR功能
线性反馈移位寄存器(LFSR),是带反馈回路的时序逻辑。
反馈回路给习惯于顺序阻塞赋值描述时序逻辑的设计人员带来了麻烦。
1.1.1,RTL设计,阻塞赋值
//
module lfsrb1(q3, clk, pre_n);
output q3;
input clk, pre_n;
reg q1, q2, q3;
wire n1;assign n1 = q1 ^ q3;always@(posedge clk or negedge pre_n)if(!pre_n) beginq3 = 1'b1;q2 = 1'b1;q1 = 1'b1;endelse beginq3 = q2;q2 = n1;q1 = q3;endendmodule
1.1.2,tb测试代码
module test_lfsrb1;
reg clk, pre_n;
wire q3;lfsrb1 u1_lfsrb1(
.q3 (q3 ),
.clk (clk ),
.pre_n (pre_n )
);always #5 clk = ~clk; // T = 10initial begin
clk = 1'b1;
pre_n = 1'b0;#100
pre_n = 1'b1;
endendmodule
1.1.3,波形仿真输出,SIM输出,没实现LFSR
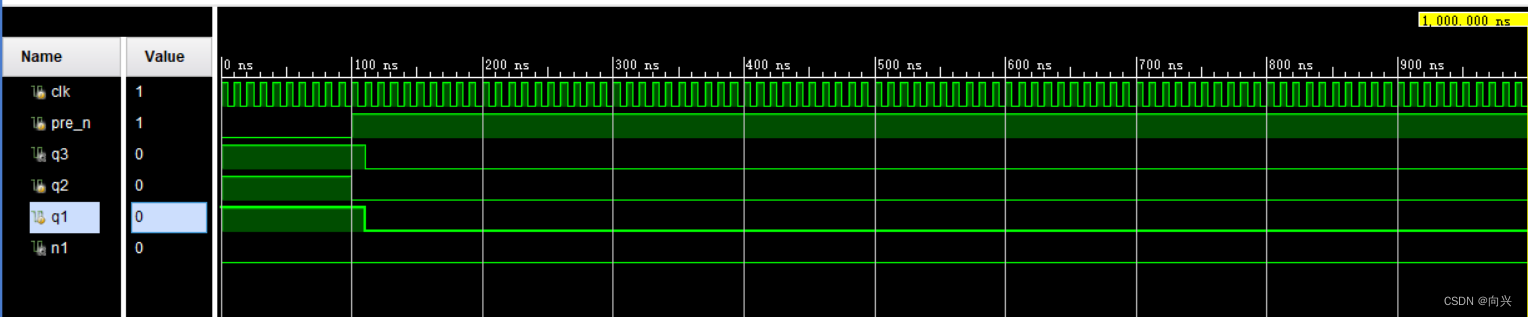
1.2.1,RTL设计,非阻塞赋值
module test_lfsrb1;
reg clk, pre_n;
wire q3;lfsrb1 u1_lfsrb1(
.q3 (q3 ),
.clk (clk ),
.pre_n (pre_n )
);always #5 clk = ~clk; // T = 10initial begin
clk = 1'b1;
pre_n = 1'b0;#100
pre_n = 1'b1;
endendmodule
除非使用中间暂存变量,否则上例所示的赋值是不可能实现反馈逻辑的。
1.2.2,RTL设计,非阻塞赋值
mmodule lfsrb1(q3, clk, pre_n);
output q3;
input clk, pre_n;
reg q1, q2, q3;
wire n1;assign n1 = q1 ^ q3;always@(posedge clk or negedge pre_n)if(!pre_n) beginq3 <= 1'b1;q2 <= 1'b1;q1 <= 1'b1;endelse beginq3 <= q2;q2 <= n1;q1 <= q3;endendmodule
1.2.3,波形功能实现,LFSR
