网站优化细节怎么做网店托管代运营费用多少钱
文章目录
- 1.前言
- 2.模块的继承
- 2.1.可继承的标签
- 2.2.超级POM
- 2.3.手动引入自定义父POM
- 3.模块的聚合
- 3.1.聚合的注意事项
- 3.2.反应堆(reactor)
- 4.依赖管理及属性配置
- 4.1.依赖管理
- 4.2.属性配置
- 5.总结
1.前言
本系列文章记录了 Maven 从0开始到实战的过程,Maven 系列历史文章清单:
(一)5分钟做完 Maven 的安装与配置
(二)使用 Maven 创建并运行项目、聊聊 POM 中的坐标与版本号的规则
(三)Maven仓库概念及私服安装与使用 附:Nexus安装包下载地址
(四)图解Maven3依赖的功能特性:依赖范围、依赖传递、依赖冲突
在前面4章的内容中,我们已经知道了怎么从0开始搭建Maven环境、Maven仓库,以及使用Maven来组织和构建简单的项目,本篇会继续在这基础上扩展,讲解Maven的继承与聚合的特性,并通过这样的特性来组织构建多模块的项目。
本篇将会通过一个简单的多模块Demo项目来展开,主要的内容包括:
- 继承的概念与使用,超级POM介绍
- 模块聚合使用上的约定
- 通过反应堆自定义模块是否构建与构建顺序
2.模块的继承
在Java中,继承的作用,往往是为了子类能够复用父类的某些特性、功能、方法等,如果父级是抽象类,还可以抽取子级中的功能特性,如果父级是接口,还可以在父级中定义一些规范(例如抽象方法),让每个子类都按照父级中的约定进行实现。
在Maven中,模块间的继承与Java的继承是类似的,可以将共性抽取到父 pom 中,通过子 pom 继承父 pom 来复用配置和约束。
2.1.可继承的标签
可继承的标签太多了,不一一例举,这里就列一些我们在开发中常用的可继承的标签:
groupId、version:坐标分组和版本,artifactId 不能继承。dependencies:依赖配置denpendencyManagement:依赖管理配置properties:自定义属性,类似于定义一个变量repositories:仓库配置distributionManagement:项目部署的仓库配置build:插件、插件管理、源码输出位置等配置
2.2.超级POM
所有的 pom.xml 文件都会默认继承 super pom,在 super pom 中定义了这么几个配置:
- 构件与插件仓库的地址
- 源码、测试代码以及资源文件
resources的默认路径 - 编译及打包后的文件路径
这也是为什么我们创建一个Maven项目之后,只要在 Maven 约定好的路径中编写我们的代码,其他的几乎什么都不用配置,就可以直接进行构建,也是一种约定优于配置的思想体现。
super pom 的位置在Maven主目录的lib文件夹下面,找到一个叫maven-model-builder.jar 的文件,在这个 jar 包的\org\apache\maven\model\pom-4.0.0.xml 路径下。如果使用的是idea的话,直接双击 shift 输入 pom-4.0.0.xml 即可:

<project><modelVersion>4.0.0</modelVersion><repositories><repository><id>central</id><name>Central Repository</name><url>https://repo.maven.apache.org/maven2</url><layout>default</layout><snapshots><enabled>false</enabled></snapshots></repository></repositories><pluginRepositories><pluginRepository><id>central</id><name>Central Repository</name><url>https://repo.maven.apache.org/maven2</url><layout>default</layout><snapshots><enabled>false</enabled></snapshots><releases><updatePolicy>never</updatePolicy></releases></pluginRepository></pluginRepositories><build><directory>${project.basedir}/target</directory><outputDirectory>${project.build.directory}/classes</outputDirectory><finalName>${project.artifactId}-${project.version}</finalName><testOutputDirectory>${project.build.directory}/test-classes</testOutputDirectory><sourceDirectory>${project.basedir}/src/main/java</sourceDirectory><scriptSourceDirectory>${project.basedir}/src/main/scripts</scriptSourceDirectory><testSourceDirectory>${project.basedir}/src/test/java</testSourceDirectory><resources><resource><directory>${project.basedir}/src/main/resources</directory></resource></resources><testResources><testResource><directory>${project.basedir}/src/test/resources</directory></testResource></testResources> </build>
</project>
2.3.手动引入自定义父POM
父 pom 的引入语法很简单,在parent标签中添加构件坐标即可,类似于dependency引入依赖:
<parent><groupId></groupId><artifactId></artifactId><version></version><relativePath></relativePath>
</parent>
这里的 relativePath 指的是父 pom.xml 所在的相对路径,默认值是 ../pom.xml,如下图:
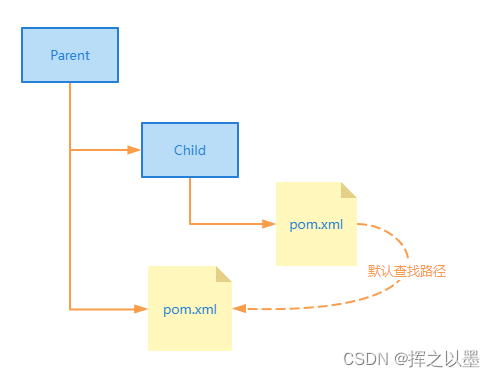
这也是 Maven 建议的目录组织形式,如果想将 parent 与 child 放到同一级目录,则需要修改为:<relativePath>../parent/pom.xml</relativePath>,如下图:
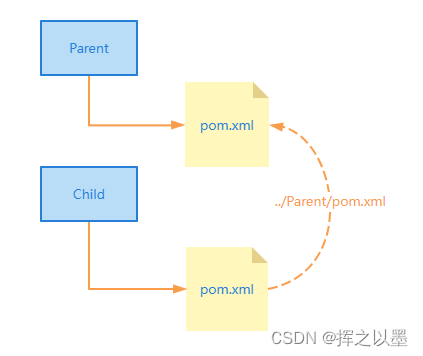
修改到其他目录同理,同步修改相对路径即可,但这里建议使用默认的目录组织形式。
在配置好<relativePath>,子模块会优先从上级目录中查找pom.xml,如果查不到则到本地仓库中查找,如果还是查不到则会从远程仓库中查找,我们经常使用的 SpringBoot 就是通过这种方式引入的:
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.6.RELEASE</version>
</parent>
3.模块的聚合
在上一篇 Maven 依赖中我们创建了一个拥有三个子模块的 Maven 项目 dependency-demo:
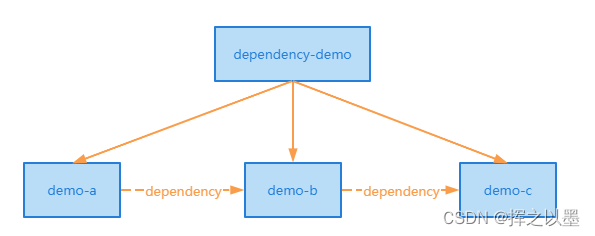
在这个项目中,demo-a 依赖 demo-b, demo-b 依赖 demo-c , 在这种情况下,我们需要先 install c ,再 install b ,最后再构建 a,执行起来非常麻烦,为了处理这个问题,Maven 引入了聚合机制,可以将这三个模块聚合在一起,一次性完成构建。
3.1.聚合的注意事项
聚合的语法也非常简单,只需要在父目录的 pom.xml 中添加 <modules> 即可:
<modules><module>demo-a</module><module>demo-b</module><module>demo-c</module>
</modules>
这里需要注意的是,<module> 中填写的并不是 artifactId,而是需要被聚合的模块的 文件目录 的相对路径,注释里面的描述是:
Each module listed is a relative path to the directory containing the module.
假如我们将 demo-a 的文件夹名称修改为 demo-aa,即使artifactId没有变,这里也需要填写为:
<modules><module>demo-aa</module><module>demo-b</module><module>demo-c</module>
</modules>
同理,如果不是 parent 项目在聚合子模块,而在a、b、c 同一级目录下,新建一个聚合模块来做聚合,则此处应该修改为。
<modules><module>../demo-a</module><module>../demo-b</module><module>../demo-c</module>
</modules>
综上,一般情况下,我们都将文件目录与 artifactId 保持一致,同时也会直接在父 pom.xml 中聚合子模块,这样的配置最简洁、最不容易出错,这也是 Maven 中约定由于配置的体现。
3.2.反应堆(reactor)
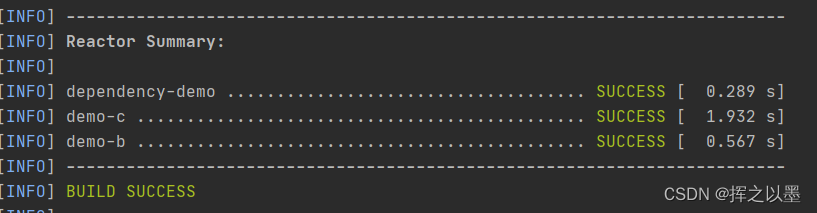
Maven 的反应堆是将多个模块的项目按照一定的顺序进行构建,我们使用上面聚合的项目来做一次构建:
mvn clean install
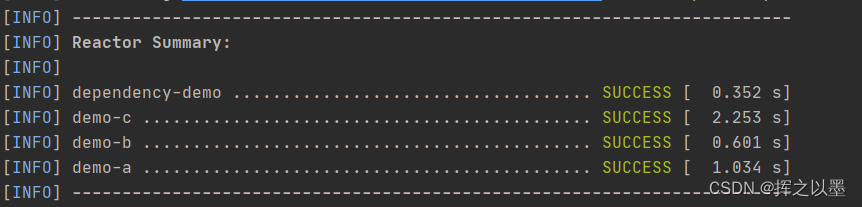
注意上面的执行顺序,先构建的是配置了聚合关系的聚合模块,然后才是子模块,子模块构建的时候会检查有没有依赖的模块,如果有就先构建依赖的模块。所以这里按照被依赖的顺序,由底层向上层进行构建。
因此,我们的模块之间不能出现循环依赖的情况,假如在demo-c中引入demo-a的依赖,此时构建就会报错。
The projects in the reactor contain a
cyclic reference: Edge between ‘Vertex{label=‘com.ls.maven:demo-c:1.0.0’}’ and ‘Vertex{label=‘com.ls.maven:demo-a:1.0.0’}’ introduc
es to cycle in the graph com.ls.maven:demo-a:1.0.0 --> com.ls.maven:demo-b:1.0.0 --> com.ls.maven:demo-c:1.0.0 --> com.ls.maven:demo-a:1.0.0
在实际的开发中,有时候我们的项目比较庞大,如果每次都完整的进行构建,耗时就会很长。此时我们可以在构建指令上加上一些参数,以便于我们选择性的构建我们需要的项目,通过mvn -h 查看。
usage: mvn [options] [<goal(s)>] [<phase(s)>]Options:-am,--also-make If project list is specified, alsobuild projects required by thelist-amd,--also-make-dependents If project list is specified, alsobuild projects that depend onprojects on the list-B,--batch-mode Run in non-interactive (batch)mode (disables output color)-b,--builder <arg> The id of the build strategy touse-C,--strict-checksums Fail the build if checksums don'tmatch-c,--lax-checksums Warn if checksums don't match-cpu,--check-plugin-updates Ineffective, only kept forbackward compatibility-pl,--projects <arg> Comma-delimited list of specifiedreactor projects to build insteadof all projects. A project can bespecified by [groupId]:artifactIdor by its relative path这里有特别多的参数,我随便复制了一部分,上面的-pl和-am是比较常用的参数,意思是,构建指定的项目以及它所依赖的项目。
pl:指定构建某一个项目am:构建项目的同时,构建它依赖的项目
假如我想指定构建demo-b及其依赖的模块demo-c,则可以用下面的指令:
mvn clean install -pl demo-b -am
4.依赖管理及属性配置
我们在做Java开发的时候,往往会将一些常量,公用的配置抽取到一个单独的文件中进行管理,这样我们在修改这些配置的时候,就有一个统一的入口,而不需要在这个项目中到处去找。
Maven的配置也是一样的,我们往往会把子模块中使用到的依赖以及版本号等,抽取到父模块中由子模块直接继承。
4.1.依赖管理
以Mysql连接为例,一般只有持久化相关的模块才会需要引入这个包。我们既要做到统一配置,又要做到只有部分模块引入,就可以在parent使用依赖管理:<dependencyManagement/>:
<dependencyManagement><dependencies><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.29</version></dependency></dependencies>
</dependencyManagement>
然后在需要使用到MySQL子模块中使用dependency进行引入,这里就不需要填写版本号了:
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId>
</dependency>
4.2.属性配置
属性配置就类似于声明变量,其语法为:
<properties><声明的属性key>声明的属性Value</声明的属性key>
</properties>
然后在其他的标签中可以使用${声明的属性key}这个语法来获取value的值,于是上面的MySQL依赖就可以改为:
<properties><mysql-connector-java.verison>8.0.29</mysql-connector-java.verison>
</properties><dependencyManagement><dependencies><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql-connector-java.verison}</version></dependency></dependencies>
</dependencyManagement>
我们可以通过这种方式灵活的组织项目,将需要经常修改的版本号放到属性配置中管理,例如可以将demo-a 与 demo-b 中的依赖版本抽取到父pom中:
<groupId>com.ls.maven</groupId>
<artifactId>dependency-demo</artifactId>
<packaging>pom</packaging>
<version>1.0.3</version><modules><module>demo-a</module><module>demo-b</module><module>demo-c</module>
</modules><name>dependency-demo</name><properties><demo-dependency.verion>1.0.3</demo-dependency.verion>
</properties><dependencyManagement><dependencies><dependency><groupId>com.ls.maven</groupId><artifactId>demo-b</artifactId><version>${demo-dependency.verion}</version></dependency><dependency><groupId>com.ls.maven</groupId><artifactId>demo-c</artifactId><version>${demo-dependency.verion}</version></dependency></dependencies>
</dependencyManagement>
然后分别修改demo-a、demo-b 中的依赖:
- demo-a:
<parent><artifactId>dependency-demo</artifactId><groupId>com.ls.maven</groupId><version>1.0.2</version></parent><modelVersion>4.0.0</modelVersion><artifactId>demo-a</artifactId><name>demo-a</name><dependencies><dependency><groupId>com.ls.maven</groupId><artifactId>demo-b</artifactId></dependency></dependencies> - demo-b:
<parent><artifactId>dependency-demo</artifactId><groupId>com.ls.maven</groupId><version>1.0.2</version> </parent> <modelVersion>4.0.0</modelVersion><artifactId>demo-b</artifactId><name>demo-b</name><dependencies><dependency><groupId>com.ls.maven</groupId><artifactId>demo-c</artifactId></dependency> </dependencies>
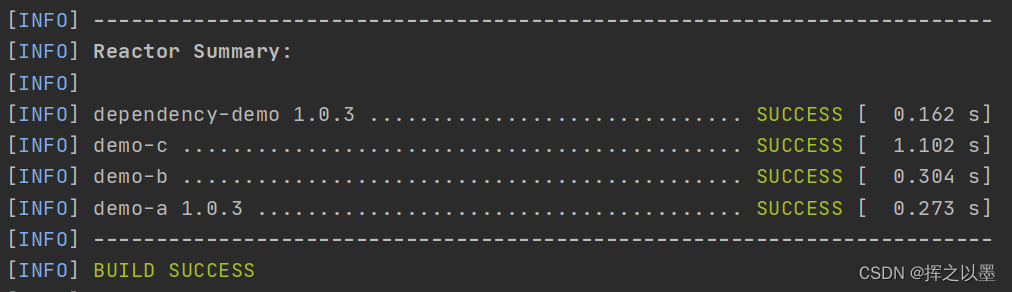
后续开发的过程中,统一修改版本号即可,例如通过Idea的批量修改将1.0.2 修改 为 1.0.3,然后尝试打包:mvn clean install:
5.总结
本篇主要讲述了Maven中的模块继承与聚合、父pom中的依赖管理、属性配置等的特性,并通过一个简单的demo来演示这些特性,总结一下:
-
继承:
- super pom 是Maven最顶层的POM,它的存在让我们几乎不能做任何配置就可以完成项目构建
- 可以通过
<parent>标签,让子模块的pom 继承 父模块的pom - 父模块的打包类型为
<packaging>pom</packaging> - 注意
<relativePath>指的的相对路径,默认为../xml.pom
-
聚合:
- 聚合的目的:将多个模块聚合在一起,一次性构建
<module>中填写的是相对文件目录名,而不是artifactId- 反应堆可以自动先构建依赖的模块,但是要注意不能产生循环依赖
- 如果只需要构建一部分模块,可以使用构建指令裁剪反应堆
-
依赖管理与属性配置:
<dependencyManagement>可以配置好需要继承的依赖坐标,子模块继承后不需要再输入版本号<properties>可以配置变量,并通过${}进行引用
通过本篇的内容,就可以在实际的开发中搭建自己的多模块项目了,Maven部分的内容就接近尾声了,下一篇将会讲 Maven的插件配置。