做电商网站需要注意哪些莱芜网络营销
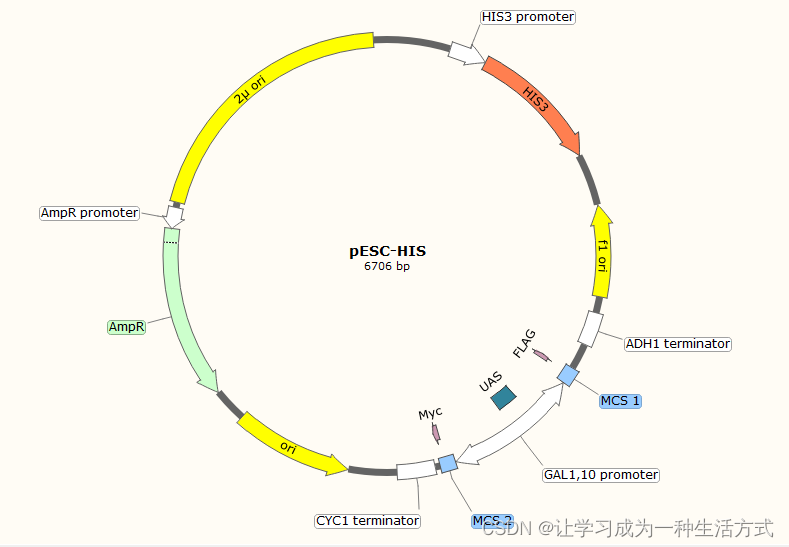
01 典型的pESC-HIS质粒遗传图谱
 02 介绍
02 介绍
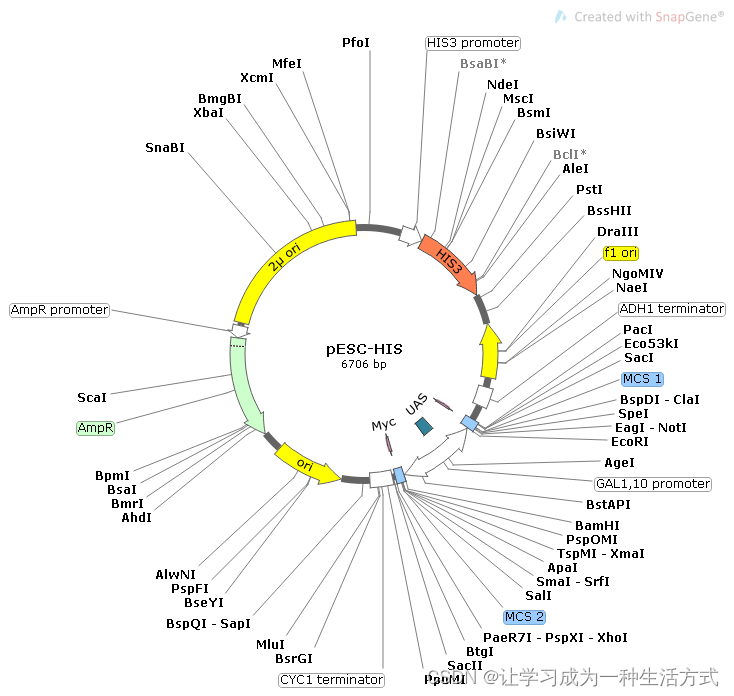
质粒类型:酿酒酵母蛋白表达载体
表达水平:高拷贝
诱导方法:半乳糖
启动子:GAL1和GAL10
克隆方法:多克隆位点,限制性内切酶
载体大小:6706bp
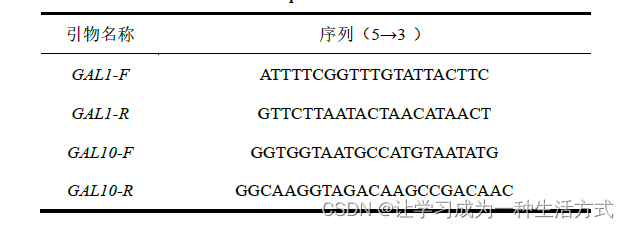
5' 测序引物及序列:
GAL1-F:ATTTTCGGTTTGTATTACTTC GAL10-F: GGTGGTAATGCCATGTAATATG
3' 测序引物及序列:
GALI-R:GTTCTTAATACTAACATAACT GAL10-R: GGCAAGGTAGACAAGCCGACAAC
载体标签:C-Flag,C-Myc
载体抗性:氨苄
筛选标记:His3
备注:利用半乳糖诱导,可以同时使两个基因在酿酒酵母中表达,这个就是双表达载体,可以很好的执行一个功能基因和一个协调辅助蛋白基因的表达,发挥两个蛋白的协同作用,比如伴侣蛋白,协调手性形成蛋白等等。用于真核蛋白表达,后接提取膜蛋白微粒体等试验。
pET-28a(+)是什么,怎么看?-实验操作系列-1