南乐网站建设电话vue做的网站百度抓取
目录
一、前言
二、GaussDB中的脱敏策略
1、数据脱敏的定义
2、创建脱敏策略的语法说明
三、在GaussDB中如何创建数据脱敏策略(示例)
1、创建脱敏策略的一般步骤
2、GaussDB数据库中创建脱敏策略的完整示例
1)开启安全策略开关,以初识用户omm登录,检查并开启安全策略开关
2)通过omm用户创建普通用户omm3,用户配置脱敏策略
3)创建测试表及测试数据,并赋权普通用户omm3
4)创建资源标签标记敏感列
5)创建脱敏策略
6)切换用户omm3进行查看
四、小结
一、前言
数据库作为存储和处理海量数据的关键基础设施,其安全性和隐私保护至关重要。在处理敏感数据时,为了保护数据隐私和安全,通常需要对数据进行脱敏处理。脱敏策略是指导如何进行数据脱敏的一系列规则和步骤。
GaussDB作为华为推出的关系型数据库管理系统,同样需要关注数据脱敏的需求。本文旨在为读者提供一个关于GaussDB创建脱敏策略的概述和基本使用,帮助读者更好地理解和学习。
二、GaussDB中的脱敏策略
1、数据脱敏的定义
数据脱敏,指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。这样就可以在开发、测试和其它非生产环境以及外包环境中安全地使用脱敏后的真实数据集。
在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并提供测试使用,如身份证号、手机号、卡号、客户号等个人信息都需要进行数据脱敏。这是数据库安全技术之一。
2、创建脱敏策略的语法说明
CREATE MASKING POLICY policy_name masking_clause[, ...] policy_filter [ENABLE | DISABLE];masking_clause:
masking_function ON LABEL(label_name[, ...])masking_function:
maskall | randommasking | creditcardmasking | basicemailmasking | fullemailmasking | shufflemasking | alldigitsmasking | regexpmaskingGaussDB中预(内)置的脱敏方式:
- maskall: 将字符串类型的所有值脱敏为x。例如:'1234-5678-9012-3456' 被脱敏为 'xxxxxxxxxxxxxxxxxxx'
- randommasking: 使用随机策略脱敏,将字符串随机成字母和数字。
- creditcardmasking: 对所有信用卡信息进行脱敏,仅对后4位之前的数字进行脱敏。例如:'1234-5678-9012-3456' 被脱敏为 'xxxx-xxxx-xxxx-3456'
- basicemailmasking: 对出现第一个'@'之前的文本进行脱敏,将@符号之前的所有数据内容设为x。例如:‘123456@qq.com’被脱敏为‘xxxxxx@qq.com’。
- fullemailmasking: 对出现最后一个'.'之前的文本(除'@'符外)进行脱敏,即对应内容设为x。例如:‘123456@qq.com’被脱敏为‘xxxxxx@xx.com’。
- shufflemasking: 对字符值进行乱序排列脱敏。属于弱脱敏函数,语义较强的字符串不建议使用该函数脱敏。
- alldigitsmasking: 仅对文本中的数字进行脱敏,例如:‘123abc’被脱敏为‘000abc’
- regexpmasking(reg,replace_text,pos,reg_len): 将字符串类型的值进行正则表达式脱敏。参数reg为被替换的字符串,replace_text为替换后的字符串,pos为目标字符串开始替换的初始位置,为整数类型,reg_len为替换长度,为整数类型。reg、replace_text可以用正则表达,pos如果不指定则默认为0,reg_len如果不指定则默认为-1,即pos后所有字符串。如果用户输入参数与参数类型不一致,则会使用maskall方式脱敏。
policy_filter:
FILTER ON FILTER_TYPE(filter_value [,...])[,...]FILTER_TYPE: IP | APP | ROLES
主要参数说明:
- masking_clause:指出使用何种脱敏函数对被label_name标签标记的数据库资源进行脱敏。
- policy_filter:指出该脱敏策略对何种身份的用户生效,若为空表示对所有用户生效。
- filter_value:指具体过滤信息内容,例如指定的IP,具体的APP名称,具体的用户名等。
- ENABLE|DISABLE: 可以打开或关闭脱敏策略。若不指定ENABLE|DISABLE,语句默认为ENABLE。
三、在GaussDB中如何创建数据脱敏策略(示例)
1、创建脱敏策略的一般步骤
在数据库中创建脱敏策略可以帮助保护敏感数据的安全性和隐私性。以下是创建脱敏策略的一般步骤:
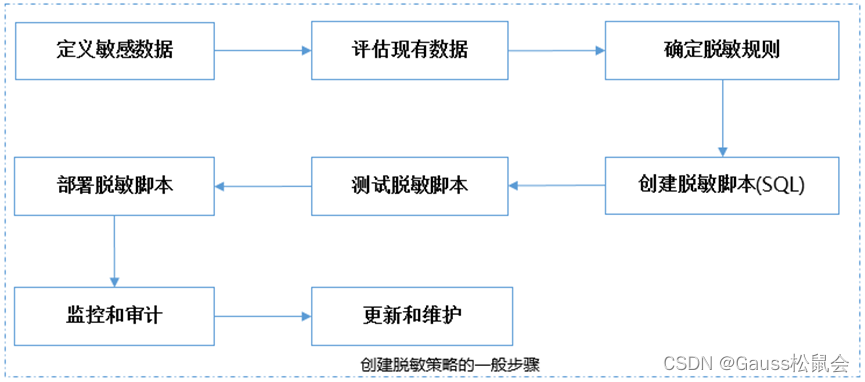
- 定义敏感数据:首先,确定哪些数据是敏感的,需要脱敏。比如个人身份信息(如姓名、身份证号码、电话号码等)、财务数据(如信用卡号、银行账号等)以及其他任何可能泄露敏感信息的字段。
- 评估现有数据:查看数据库中现有的数据,了解敏感数据的分布和频率。这有助于确定哪些数据需要脱敏,以及脱敏的优先级。
- 确定脱敏规则:根据敏感数据的类型和特点,确定适当的脱敏规则。例如,对于电话号码,您可能希望将其替换为无效号码;对于身份证号,您可能希望删除或替换其中的部分数字。
- 创建脱敏脚本:使用如SQL等编写,实现自动执行脱敏操作。您可以使用数据库管理系统(如GaussDB、MySql等)提供的工具或函数等。
- 测试脱敏脚本:在将脚本部署到生产环境之前,先在测试环境中进行测试。确保其能正确地脱敏敏感数据,并且不会对其他非敏感数据造成影响。
- 部署脱敏脚本:一旦测试通过,就可以将脱敏脚本或程序部署到生产环境。
- 监控和审计:建立监控和审计机制,以确保脱敏脚本或程序的正常运行和敏感数据的合规性。定期检查和验证脱敏操作的有效性,并记录任何异常或违规行为。
- 更新和维护:随着业务需求的变化和数据安全标准的更新,定期更新和维护脱敏策略。检查新出现的数据类型和敏感信息,调整脱敏规则,确保数据安全和隐私保护的持续有效性。
2、GaussDB数据库中创建脱敏策略的完整示例
1)开启安全策略开关,以初识用户omm登录,检查并开启安全策略开关。
--检查数据库enable_security_policy参数是否为on。
SHOW enable_security_policy;
Tip:设置参数值方式之一:例如直接找到数据库配置文件进行手工更改。

2)通过omm用户创建普通用户omm3,用户配置脱敏策略。
--创建普通用omm3
CREATE USER omm3 PASSWORD 'P@ssw0rd';--赋予用户omm3 public模式的权限。
GRANT ALL ON SCHEMA public TO omm3;
运行结果:
GaussDB=# CREATE USER omm3 PASSWORD 'P@ssw0rd';
NOTICE: The encrypted password contains MD5 ciphertext, which is not secure.
CREATE ROLE
GaussDB=# GRANT ALL ON SCHEMA public TO omm3;
GRANT
3)创建测试表及测试数据,并赋权普通用户omm3。
--创建测试表
CREATE TABLE public.test_5(col1 text,col2 text,col3 text,col4 text,col5 text,col6 text,col7 text,col8 text
);--插入测试数据
INSERT INTO public.test_5(col1,col2,col3,col4,col5,col6,col7,col8
)
VALUES('张三','30岁','1234-5678-9012-3456','123456@qq.com','234567@qq.com','zhangsan','zhangsan9527'
,'1234-5678-9012-3456'
);--赋予用户omm3 测试表权限
GRANT ALL ON public.test_5 TO omm3;
运行结果:
GaussDB=# CREATE TABLE public.test_5( col1 text ,col2 text ,col3 text ,col4 text ,col5 text ,col6 text ,col7 text ,col8 text );
CREATE TABLE
GaussDB=# INSERT INTO public.test_5( col1 ,col2 ,col3 ,col4 ,col5 ,col6 ,col7 ,col8 ) VALUES( '张三' ,'30岁' ,'1234-5678-9012-3456' ,'123456@qq.com' ,'234567@qq.com' ,'zhangsan' ,'zhangsan9527' ,'1234-5678-9012-3456' );
INSERT 0 1
GaussDB=# select * from public.test_5;col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8
------+------+---------------------+---------------+---------------+----------+--------------+---------------------张三 | 30岁 | 1234-5678-9012-3456 | 123456@qq.com | 234567@qq.com | zhangsan | zhangsan9527 | 1234-5678-9012-3456
(1 row)
GaussDB=# GRANT ALL ON public.test_5 TO omm3;
GRANT
4)创建资源标签标记敏感列。
--创建资源标签标记敏感列。
CREATE RESOURCE LABEL mask_l1 ADD COLUMN(public.test_5.col1);
CREATE RESOURCE LABEL mask_l2 ADD COLUMN(public.test_5.col2);
CREATE RESOURCE LABEL mask_l3 ADD COLUMN(public.test_5.col3);
CREATE RESOURCE LABEL mask_l4 ADD COLUMN(public.test_5.col4);
CREATE RESOURCE LABEL mask_l5 ADD COLUMN(public.test_5.col5);
CREATE RESOURCE LABEL mask_l6 ADD COLUMN(public.test_5.col6);
CREATE RESOURCE LABEL mask_l7 ADD COLUMN(public.test_5.col7);
CREATE RESOURCE LABEL mask_l8 ADD COLUMN(public.test_5.col8);
运行结果:
GaussDB=# CREATE RESOURCE LABEL mask_l1 ADD COLUMN(public.test_5.col1); CREATE RESOURCE LABEL mask_l2 ADD COLUMN(public.test_5.col2); CREATE RESOURCE LABEL mask_l3 ADD COLUMN(public.test_5.col3); CREATE RESOURCE LABEL mask_l4 ADD COLUMN(public.test_5.col4); CREATE RESOURCE LABEL mask_l5 ADD COLUMN(public.test_5.col5); CREATE RESOURCE LABEL mask_l6 ADD COLUMN(public.test_5.col6); CREATE RESOURCE LABEL mask_l7 ADD COLUMN(public.test_5.col7); CREATE RESOURCE LABEL mask_l8 ADD COLUMN(public.test_5.col8);
CREATE RESOURCE LABEL
CREATE RESOURCE LABEL
CREATE RESOURCE LABEL
CREATE RESOURCE LABEL
CREATE RESOURCE LABEL
CREATE RESOURCE LABEL
CREATE RESOURCE LABEL
CREATE RESOURCE LABEL
5)创建脱敏策略。
脱敏策略详解参将上文“GaussDB中预(内)置的脱敏方式”:
--创建脱敏策略。
CREATE MASKING POLICY mask_p1 maskall ON LABEL(mask_l1);
CREATE MASKING POLICY mask_p2 randommasking ON LABEL(mask_l2);
CREATE MASKING POLICY mask_p3 creditcardmasking ON LABEL(mask_l3);
CREATE MASKING POLICY mask_p4 basicemailmasking ON LABEL(mask_l4);
CREATE MASKING POLICY mask_p5 fullemailmasking ON LABEL(mask_l5);
CREATE MASKING POLICY mask_p6 shufflemasking ON LABEL(mask_l6);
CREATE MASKING POLICY mask_p7 alldigitsmasking ON LABEL(mask_l7);
CREATE MASKING POLICY mask_p8 regexpmasking('[\d+]','*',3,15) ON LABEL(mask_l8);
运行结果:
GaussDB=# CREATE MASKING POLICY mask_p1 maskall ON LABEL(mask_l1); CREATE MASKING POLICY mask_p2 randommasking ON LABEL(mask_l2);CREATE MASKING POLICY mask_p3 creditcardmasking ON LABEL(mask_l3); CREATE MASKING POLICY mask_p4 basicemailmasking ON LABEL(mask_l4); CREATE MASKING POLICY mask_p5 fullemailmasking ON LABEL(mask_l5); CREATE MASKING POLICY mask_p6 shufflemasking ON LABEL(mask_l6); CREATE MASKING POLICY mask_p7 alldigitsmasking ON LABEL(mask_l7); CREATE MASKING POLICY mask_p8 regexpmasking('[\d+]','*',3,15) ON LABEL(mask_l8);
CREATE MASKING POLICY
CREATE MASKING POLICY
CREATE MASKING POLICY
CREATE MASKING POLICY
CREATE MASKING POLICY
CREATE MASKING POLICY
CREATE MASKING POLICY
CREATE MASKING POLICY
6)切换用户omm3进行查看。
GaussDB=> SELECT * FROM public.test_5;col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8
------+------+---------------------+---------------+---------------+----------+--------------+---------------------xx | 8dd | xxxx-xxxx-xxxx-3456 | xxxxxx@qq.com | xxxxxx@xx.com | hnaanzgs | zhangsan0000 | 123*-****-****-***6
(1 row)
对比脱敏前的结果:

通过以上示例,您可以创建一个有效的数据库脱敏策略,保护敏感数据的安全性和隐私性。请注意,具体的实现细节可能因数据库类型、编程语言和安全要求而有所不同。在实际操作中,请根据具体情况进行调整和定制化设置。
四、小结
在GaussDB数据库中实施脱敏策略,指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。在数据脱敏过程中,通常会采用不同的算法和技术,以根据不同的需求和场景对数据进行处理。
总的来说,实施脱敏策略,不仅可以防止未经授权的访问和滥用敏感数据,还可以降低数据泄露的风险,提高企业的合规性。通过脱敏处理,企业可以更好地平衡数据利用与隐私保护之间的关系,满足各种合规要求
——结束