建网站麻烦拍照备案审核多久网站域名备案信息
Flink之Task解析
对Flink的Task进行解析前,我们首先要清楚几个角色TaskManager、Slot、Task、Subtask、TaskChain分别是什么
| 角色 | 注释 |
|---|---|
| TaskManager | 在Flink中TaskManager就是一个管理task的进程,每个节点只有一个TaskManager |
| Slot | Slot就是TaskManager中的槽位,一个TaskManager中可以存在多个槽位,取决于服务器资源和用户配置,可以在槽位中运行Task实例 |
| Task | 其实Task在Flink中就是一个类,其中可以包含一个或多个算子,这个取决于算子链的构成 |
| SubTask | SubTask就是Task类的并行实例可以是一个或多个,也就是说当代码执行的那一刻开始,就根据用户所设置或者默认的并行度创建出多个SubTask |
| TaskChain | TaskChain就是算子链,何为算子链?就是在一个Task实例中出现的串行算子,算子间必须是OneToOne模式且并行度相同. |
上面对几个角色进行了一个简单的阐述,后面会结合图解和伪代码进行讲解,这里我们以计算中比较经典wordcount为例子,伪代码如下所示:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 创建流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 设置并行度3env.setParallelism(3)// 读取数据文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 转大写DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 转成tuple2格式,计数1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 按照单词分组KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
上面的代码中我们使用了两次map,一次keyBy,一次sum算子,我们下面就结合这几个算子进行讲解,讲解之前有两个条件需要先记住:
- 同一个Task并行实例不能放在同一个TaskSlot上运行,一个TaskSlot上可以运行多个不同的Task并行实例
- 同一个共享组的算子允许共享槽位,不同共享组的算子决不允许共享槽位
上面这两句话一定要记牢,以便于后面的理解.
算子链划分及Task槽位分配
算子链划分
可以根据上面的代码理解下图:
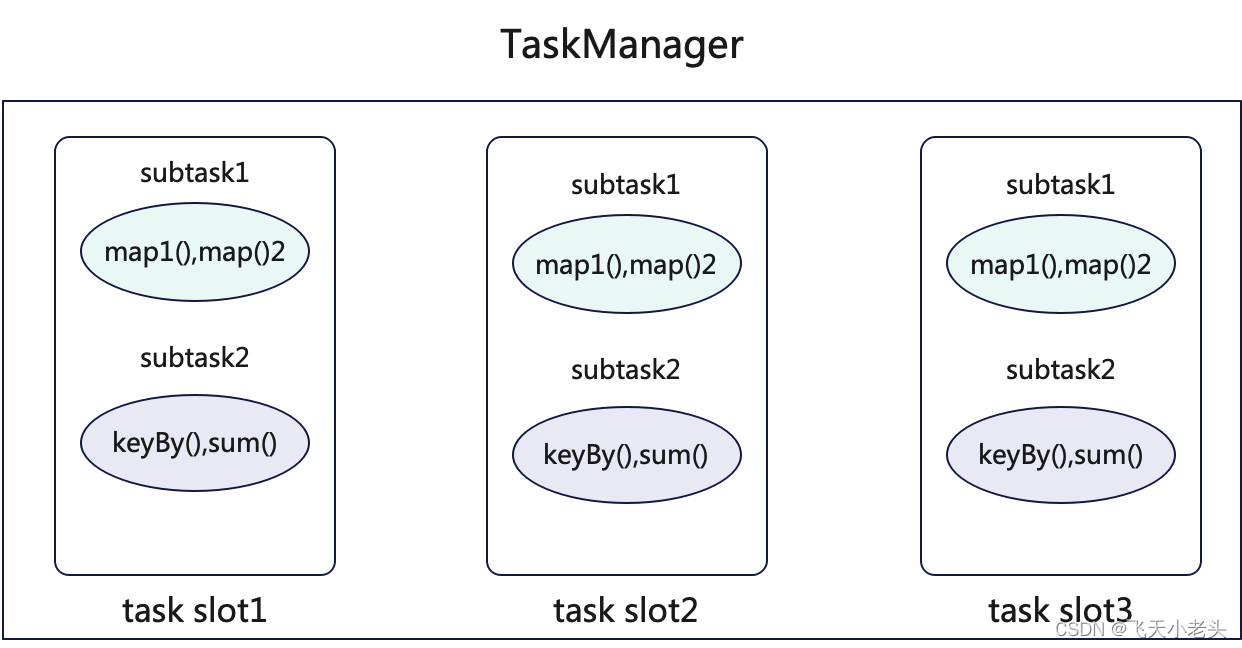
上图中我们可以看到两个map组成一个task chain,keyBy和sum组成一个task chain,这里说一下原因,首先就是两个map的并行度是一致的,而且是OneToOne模式,所以可以将两个map绑定成一个算子链,并将其放入到一个SubTask中,而到了keyBy这里为什么不能再放入到一个task chain中,这里我们可以思考一下,keyBy时会发生什么?以spark的角度来说会发生shuffle对吧,这就导致了不能满足OneToOne的模式,简单来说我们也可以想清楚,如果keyBy和map组成一个task chain那么还怎么做wordcount?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bckucHbv-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task2.png)]](https://img-blog.csdnimg.cn/589a720a88b84aebabb5ef71b1da22af.png)
通过上图应该很容易理解了.
Task槽位分配
上面讲了关于task chain怎么划分的,为什么这样划分,这里讲一下为什么同一个Task的并行实例(SubTask)不能在同一个task slot中.其实这个也很容易就想清楚,如果同一Task的多个SubTask都出现在一个task slot中那么还有什么意义呢?当这些SubTask出现在一个task slot中时就会发生串行计算,那并行的意义也就没有了.
同时这种机制也保证了任务的容错性,也就是说对于同一个Task一旦某一个task slot出现异常的情况,其他的task slot中的SubTask还能正常运行,如果将这些SubTask放到一个task slot中,当这个task slot出现异常情况时,就会影响整个任务的执行.
总结来说,这种设计保证了Flink任务的隔离性、容错性、资源利用性.这里用图解的方式便于大家记忆,如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rlgqeo6A-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task3.png)]](https://img-blog.csdnimg.cn/c0e80184d18b44cebf8faaaa72c59ca8.png)
槽位共享及算子链断/连
槽位共享
前面讲过同一个Task的多个SubTask不能出现在一个task slot中,但是不同Task的SubTask是可以共享同一个task slot的,但是在Flink中有一个机制,就是用户(开发人员)可以自定义不同的算子间是否可以共享同一个task slot,如上面的例子中两个map的并行度一致并且符合OneToOne的模式,在正常情况下必然会会分到一个task chain中,但是Flink给用户提供了的slot group的概念,也就是说用户可以将这两个map分配到不同的slot group中,这种情况下两个map就不会划分到一个task chain中,试想一下当两个map都不允许共享同一个task slot时,怎么可能划分到同一个task chain中呢?
伪代码如下:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 创建流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 设置并行度3env.setParallelism(1)// 读取数据文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 转大写DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 通过slotSharingGroup()将upperCaseSource作为一个分组"g1"SingleOutputStreamOperator<String> slotGroup1 = upperCaseSource.slotSharingGroup("g1");// 转成tuple2格式,计数1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 通过slotSharingGroup()将mapStream作为一个分组"g3"SingleOutputStreamOperator<Tuple2<String, Integer>> slotGroup2 = mapStream.slotSharingGroup("g2");// 按照单词分组KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
上面的代码中我们将upperCaseSource和mapStream分成了两个task slot,这样两个map就不可以共享相同的task slot,同时代码中将并行度改为了1,这样便于图解,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-saLgMu0Q-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task4.png)]](https://img-blog.csdnimg.cn/c791831068674b58b13c2987e671c6a3.png)
如果说集群中总task slot只有3个,并且在代码中两个map设置了不同的task slot且两个map的并行度都为3时会怎么样?很简单,提交任务时就会报错,因为提交任务所需要的资源已经超出了集群的资源.
这里说一下对于对task slot进行分组处理的实际用处,就以代码中两个map为例子,在实际的业务中如果两个map处理的数据量都极大,如果将两个map的计算都放到一个节点的一个task slot时会发生什么?数据的积压、任务异常失败等等都有可能发生,但是有slotSharingGroup我们就可以保证同一个task slot不会承载过大的计算任务,也就达到了资源合理分配的目的.
算子链断/连
前面讲了关于将两个map进行slotSharingGroup后会将两个map划分到不同的task chain,如果有这样一个情况两个map满足OneToOne的模式且并行度相同时,我们不使用slotSharingGroup能否将两个map划分成不同的task chain?答案是当然可以的,Flink为我们提供了对应的API,伪代码如下:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 创建流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 设置并行度3env.setParallelism(3)// 读取数据文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 转大写DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 转成tuple2格式,计数1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 将mapStream划分到一个新的task chain中SingleOutputStreamOperator<Tuple2<String, Integer>> newTaskChainMapStream = mapStream.startNewChain();// 按照单词分组KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
在上面代码中我们调用了startNewChain()后就可以将mapStream划分到一个新的task chain中,这样的情况下,两个map既属于不同的task chain又可以共享同一个task slot,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jOIlz8uH-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task5.png)]](https://img-blog.csdnimg.cn/2314559b6cad40358b5606dec3b91305.png)
以上就是对于Task的讲解,如有错误欢迎指出,如有问题共同探讨.