优秀企业网站欣赏wordpress 分类的地址
SpringBoot+ActiveMQ-发布订阅模式(生产端)
Topic 主题
* 消息消费者(订阅方式)消费该消息
* 消费生产者将发布到topic中,同时有多个消息消费者(订阅)消费该消息
* 这种方式和点对点方式不同,发布到topic的消息会被所有订阅者消费
* 当生产者发布消息,不管是否有消费者,都不会保存消息,如果对订阅消息提前做了持久化操作,还是可以收到的
ActiveMQ版本:apache-activemq-5.16.5
案例源码:SpringBoot+ActiveMQ-发布订阅Demo
SpringBoot集成ActiveMQ topic生产端的pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.5.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>boot.example.topic.provider</groupId><artifactId>boot-example-topic-demo-provider-2.0.5</artifactId><version>0.0.1-SNAPSHOT</version><name>boot-example-topic-demo-provider-2.0.5</name><description>Demo project for Spring Boot</description><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><java.version>1.8</java.version></properties><dependencies><dependency><groupId>boot.example.demo.entity</groupId><artifactId>boot-example-demo-entity-2.0.5</artifactId><version>0.0.1-SNAPSHOT</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- activeMQ依赖组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-activemq</artifactId><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion></exclusions></dependency><!-- spring.activemq.pool.enabled=true --><dependency><groupId>org.apache.activemq</groupId><artifactId>activemq-pool</artifactId><version>5.16.5</version></dependency><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version></dependency><dependency><groupId>com.github.xiaoymin</groupId><artifactId>swagger-bootstrap-ui</artifactId><version>1.9.2</version></dependency></dependencies><build><plugins><!-- 打包成一个可执行jar --><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build></project>application.properties
server.port=8043spring.activemq.broker-url=tcp://127.0.0.1:61616
spring.activemq.user=admin
spring.activemq.password=admin
spring.activemq.in-memory=false
spring.activemq.packages.trust-all=true
spring.activemq.pool.enabled=true
spring.activemq.pool.max-connections=6
spring.activemq.pool.idle-timeout=30000
spring.activemq.pool.expire-timeout=0
spring.jms.pub-sub-domain=false启动类AppTopicProvider
package boot.example.topic.provider;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.jms.annotation.EnableJms;/***蚂蚁舞*/
@SpringBootApplication
@EnableJms
public class AppTopicProvider
{public static void main( String[] args ){SpringApplication.run(AppTopicProvider.class, args);System.out.println( "Hello World!" );}
}
ActiveMqConfig
package boot.example.topic.provider.config;import org.apache.activemq.command.ActiveMQTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jms.annotation.EnableJms;
import org.springframework.jms.config.DefaultJmsListenerContainerFactory;
import org.springframework.jms.config.JmsListenerContainerFactory;import javax.jms.ConnectionFactory;
import javax.jms.Topic;/*** 蚂蚁舞*/@Configuration
public class ActiveMqConfig {public static final String defaultTopic = "myw_topic";@Beanpublic Topic topic() {return new ActiveMQTopic(defaultTopic);}// // topic模式的ListenerContainer
// @Bean
// public JmsListenerContainerFactory<?> jmsListenerContainerTopic(ConnectionFactory activeMQConnectionFactory) {
// DefaultJmsListenerContainerFactory bean = new DefaultJmsListenerContainerFactory();
// bean.setPubSubDomain(true);
// bean.setConnectionFactory(activeMQConnectionFactory);
// return bean;
// }}ProviderDefaultTopicService
package boot.example.topic.provider.service;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jms.core.JmsMessagingTemplate;
import org.springframework.stereotype.Service;import javax.jms.Topic;@Service
public class ProviderDefaultTopicService {@Autowiredprivate Topic topic;@Autowiredprivate JmsMessagingTemplate jmsMessagingTemplate;/*** 使用默认bean配置的名称发送数据*/public void sendStringDefaultTopic(String message) {this.jmsMessagingTemplate.convertAndSend(topic, message);}}
ProviderTopicService
package boot.example.topic.provider.service;import boot.example.queue.entity.BootProvider;
import org.apache.activemq.command.ActiveMQTopic;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jms.core.JmsMessagingTemplate;
import org.springframework.stereotype.Service;import java.util.List;/*** 蚂蚁舞*/
@Service
public class ProviderTopicService {@Autowiredprivate JmsMessagingTemplate jmsMessagingTemplate;/*** 发送字符串消息主题** @param topicName 主题名称* @param message 字符串*/public void sendStringTopic(String topicName, String message) {this.jmsMessagingTemplate.convertAndSend(new ActiveMQTopic(topicName), message);}/*** 发送字符串集合消息主题** @param topicName 主题名称* @param list 字符串集合*/public void sendStringListTopic(String topicName, List<String> list) {this.jmsMessagingTemplate.convertAndSend(new ActiveMQTopic(topicName), list);}/*** 发送对象消息主题** @param topicName 主题名称* @param obj 对象*/public void sendObjTopic(String topicName, BootProvider obj) {this.jmsMessagingTemplate.convertAndSend(new ActiveMQTopic(topicName), obj);}/*** 发送对象集合消息主题** @param topicName 主题名称* @param objList 对象集合*/public void sendObjListTopic(String topicName, List<BootProvider> objList) {this.jmsMessagingTemplate.convertAndSend(new ActiveMQTopic(topicName), objList);}}
BootDefaultTopicProviderController
package boot.example.topic.provider.controller;import boot.example.topic.provider.service.ProviderDefaultTopicService;
import org.springframework.web.bind.annotation.*;import javax.annotation.Resource;/*** 蚂蚁舞*/
@RestController
@RequestMapping(value="/provider")
public class BootDefaultTopicProviderController {@Resourceprivate ProviderDefaultTopicService providerDefaultTopicService;@PostMapping(value = "/sendStringDefaultTopic")@ResponseBodypublic String sendStringDefaultTopic(@RequestParam(name="message",required = true) String message) throws Exception {providerDefaultTopicService.sendStringDefaultTopic(message);return "success";}}
BootTopicProviderController
package boot.example.topic.provider.controller;import boot.example.queue.entity.BootProvider;
import boot.example.topic.provider.service.ProviderTopicService;
import org.springframework.web.bind.annotation.*;import javax.annotation.Resource;
import java.util.List;/*** 蚂蚁舞*/
@RestController
@RequestMapping(value="/provider")
public class BootTopicProviderController {// 指定Topicpublic static final String stringTopic = "stringTopic";// 指定list<String>public static final String stringListTopic = "stringListTopic";// 指定Objectpublic static final String objTopic = "objTopic";// 指定List<Object>public static final String objListTopic = "objListTopic";@Resourceprivate ProviderTopicService providerTopicService;@PostMapping(value = "/sendStringTopic")@ResponseBodypublic String sendStringTopic(@RequestParam(name="message",required = true) String message) throws Exception {providerTopicService.sendStringTopic(stringTopic, message);return "success";}@PostMapping(value = "/sendStringListTopic")@ResponseBodypublic String sendStringListTopic(@RequestBody List<String> list) throws Exception {if(list.isEmpty()){return "fail";}providerTopicService.sendStringListTopic(stringListTopic, list);return "success";}@PostMapping(value = "/sendObjTopic")@ResponseBodypublic String sendObjTopic(@RequestBody BootProvider bootProvider) throws Exception {if(bootProvider == null){return "fail";}providerTopicService.sendObjTopic(objTopic, bootProvider);return "success";}@PostMapping(value = "/sendObjListTopic")@ResponseBodypublic String sendObjListTopic(@RequestBody List<BootProvider> list) throws Exception {if(list.isEmpty()){return "fail";}providerTopicService.sendObjListTopic(objListTopic, list);return "success";}}
SwaggerConfig UI界面测试用
package boot.example.topic.provider.config;import com.google.common.base.Predicates;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;/*** 蚂蚁舞*/
@Configuration
@EnableSwagger2
public class SwaggerConfig {@Beanpublic Docket createRestApi(){return new Docket(DocumentationType.SWAGGER_2).apiInfo(apiInfo()).select().apis(RequestHandlerSelectors.any()).paths(PathSelectors.any()).paths(Predicates.not(PathSelectors.regex("/error.*"))).paths(PathSelectors.regex("/.*")).build().apiInfo(apiInfo());}private ApiInfo apiInfo(){return new ApiInfoBuilder().title("demo").description("demo接口").version("0.01").build();}/*** http://localhost:XXXX/doc.html 地址和端口根据实际项目查看*/}
BootProvider用来测试的类
package boot.example.queue.entity;import java.io.Serializable;
import java.util.Date;/*** 用在activeMq消息,必须保证package一致,不然序列化后反序列化要出错* 蚂蚁舞*/
public class BootProvider implements Serializable {private int id;private String name;private Date date = new Date();public BootProvider() {}public BootProvider(int id, String name) {this.id = id;this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Date getDate() {return date;}public void setDate(Date date) {this.date = date;}@Overridepublic String toString() {return "BootProvider{" +"id=" + id +", name='" + name + '\'' +", date=" + date +'}';}
}
代码结构
├─boot-example-demo-entity-2.0.5
│ │ pom.xml
│ │
│ ├─src
│ │ └─main
│ │ └─java
│ │ └─boot
│ │ └─example
│ │ └─queue
│ │ └─entity
│ │ BootProvider.java
│ │
├─boot-example-topic-demo-provider-2.0.5
│ │ pom.xml
│ ├─src
│ │ ├─main
│ │ │ ├─java
│ │ │ │ └─boot
│ │ │ │ └─example
│ │ │ │ └─topic
│ │ │ │ └─provider
│ │ │ │ │ AppTopicProvider.java
│ │ │ │ │
│ │ │ │ ├─config
│ │ │ │ │ ActiveMqConfig.java
│ │ │ │ │ SwaggerConfig.java
│ │ │ │ │
│ │ │ │ ├─controller
│ │ │ │ │ BootDefaultTopicProviderController.java
│ │ │ │ │ BootTopicProviderController.java
│ │ │ │ │
│ │ │ │ └─service
│ │ │ │ ProviderDefaultTopicService.java
│ │ │ │ ProviderTopicService.java
│ │ │ │
│ │ │ └─resources
│ │ │ application.properties
│ │ │
│ │ └─test
│ │ └─java
│ │ └─boot
│ │ └─example
│ │ └─topic
│ │ └─provider
│ │ AppTopicProviderTest.javaActiveMQ在SpringBoot里的Topic代码demo集成完成,(ActiveMQ已启动后)启动程序访问
http://localhost:8043/doc.html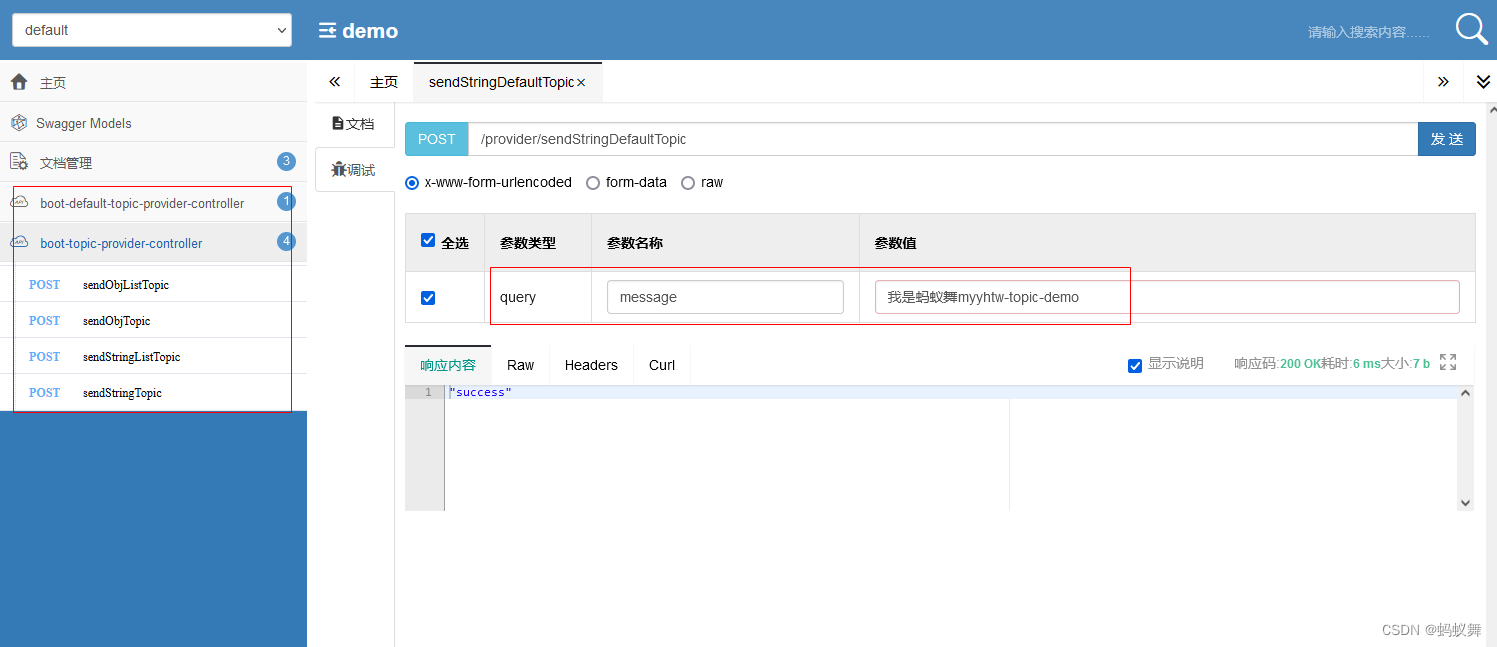
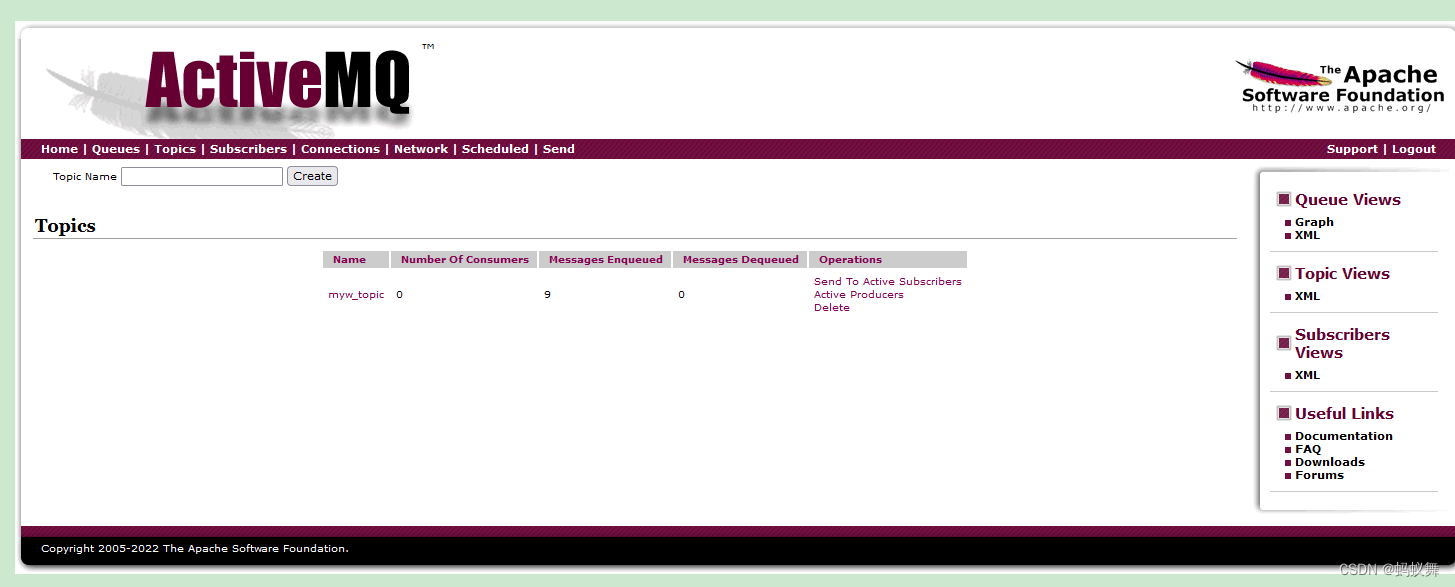
SpringBoot集成activeMQ对于队列(queue)来说是持久化的事物模式,因此拿来即用,但是发布订阅(topic主题)模式不是持久化的,发送端把消息发出后,如果没有消费者,消息不会被消费,即使消费者端启动了,也不会消费之前的消息(除非对发布订阅也做持久化)
典型的案例topic demo测试(支持持久化订阅)
ActiveMQTopicProvider(Topic生产端)
package boot.example.topic.provider;import org.apache.activemq.ActiveMQConnectionFactory;import javax.jms.*;/*** 蚂蚁舞*/
public class ActiveMQTopicProvider {public static void main(String[] args) throws Exception{ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("admin", "admin", "tcp://127.0.0.1:61616");Connection connection = connectionFactory.createConnection();connection.start();//创建会话//第一个参数:是否开启事务 transacted true开启 false不开启//第二个参数:消息是否自动确认 acknowledgeMode//当transacted为true时,acknowledgeMode会默认Session.SESSION_TRANSACTEDSession session = connection.createSession(true, Session.DUPS_OK_ACKNOWLEDGE);//创建TopicTopic topic = session.createTopic("myw_topic_test");MessageProducer producer = session.createProducer(topic);producer.setDeliveryMode(DeliveryMode.PERSISTENT);//持久化设置 默认就是这个Message message = session.createTextMessage("myyhtw蚂蚁也会跳舞");producer.send(message);session.commit(); // 开启事务必须提交这个producer.close();session.close();connection.close();}
}
ActiveMQTopicConsumer(Topic消费端)
package boot.example.topic.provider;import org.apache.activemq.ActiveMQConnectionFactory;import javax.jms.*;/*** 蚂蚁舞*/
public class ActiveMQTopicConsumer {public static void main(String[] args) throws Exception {String clientId = "myw_topic_test_wijwe";//创建连接工厂ActiveMQConnectionFactory connectionFactory = new ActiveMQConnectionFactory("admin", "admin", "tcp://127.0.0.1:61616");// 持久订阅的Client端标识(多个端持久订阅需要保证唯一性,否则可能会出现问题)connectionFactory.setClientID(clientId);//创建连接Connection connection = connectionFactory.createConnection();//开启连接connection.start();// 创建会话// transacted 如果设置true,操作消息队列后,必须使用 session.commit() 如果设置false,操作消息队列后,不使用session.commit();// acknowledgeMode// 1-Session.AUTO_ACKNOWLEDGE 自动应答// 2-Session.CLIENT_ACKNOWLEDGE 手动应答// 3-Session.DUPS_OK_ACKNOWLEDGE 延迟应答// 0-Session.SESSION_TRANSACTED 事务// 当transacted为true时,acknowledgeMode会默认Session.SESSION_TRANSACTEDSession session = connection.createSession(true, Session.AUTO_ACKNOWLEDGE);//创建topicTopic topic = session.createTopic("myw_topic_test");//持久订阅//创建消费者
// // 普通订阅 topic不是持久化的
// MessageConsumer consumer = session.createConsumer(topic);// 持久订阅MessageConsumer consumer = session.createDurableSubscriber(topic,clientId);while(true){//失效时间,如果10秒内没有收到新的消息,说明没有消息存在,此时可以退出当前循环TextMessage message = (TextMessage) consumer.receive(60000);if(message!=null){System.out.println(message.getText());//message.acknowledge();} else {break;}}//关闭连接session.commit();session.close();connection.close();}
}ActiveMQTopicConsumerListener(Topic消费端监听)
package boot.example.topic.provider;import org.apache.activemq.ActiveMQConnectionFactory;import javax.jms.*;/*** 蚂蚁舞*/
public class ActiveMQTopicConsumerListener {public static void main(String[] args) throws Exception {String clientId = "myw_topic_test_www2";//创建连接工厂ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("admin", "admin", "tcp://127.0.0.1:61616");//创建连接Connection connection = connectionFactory.createConnection();// 持久订阅的Client端标识(多个端持久订阅需要保证唯一性,否则可能会出现问题)connection.setClientID(clientId);//开启连接connection.start();// 创建会话// transacted 如果设置true,操作消息队列后,必须使用 session.commit() 如果设置false,操作消息队列后,不使用session.commit();// acknowledgeMode// 1-Session.AUTO_ACKNOWLEDGE 自动应答// 2-Session.CLIENT_ACKNOWLEDGE 手动应答// 3-Session.DUPS_OK_ACKNOWLEDGE 延迟应答// 0-Session.SESSION_TRANSACTED 事务// 当transacted为true时,acknowledgeMode会默认Session.SESSION_TRANSACTEDSession session = connection.createSession(false, Session.CLIENT_ACKNOWLEDGE);//创建topicTopic topic = session.createTopic("myw_topic_test");//创建消费者
// // 普通订阅 topic不是持久化的
// MessageConsumer consumer = session.createConsumer(topic);// 持久订阅MessageConsumer consumer = session.createDurableSubscriber(topic,clientId);//注册消息监听器consumer.setMessageListener(new MessageListener() {@Overridepublic void onMessage(Message message) {try {TextMessage msg = (TextMessage)message;System.out.println(msg.getText());message.acknowledge();} catch (JMSException e) {throw new RuntimeException(e);}}});while (true){}
// consumer.close();
// session.close();
// connection.close();}}
topic持久化需要发布端设置持久化
producer.setDeliveryMode(DeliveryMode.PERSISTENT);//持久化设置 默认就是这个topic消费订阅端在代码里有这几个设置
String clientId = "myw_topic_test_www2";// 持久订阅的Client端标识(多个端持久订阅需要保证唯一性,否则可能会出现问题)
connection.setClientID(clientId);// 持久订阅
MessageConsumer consumer = session.createDurableSubscriber(topic,clientId);