怎么免费申请个人网站苏州网站建设caiyiduo
传统RNN模型
- 1 传统RNN模型
- 1.1 RNN结构分析
- 1.2 使用Pytorch构建RNN模型
- 1.3 传统RNN优缺点
1 传统RNN模型
1.1 RNN结构分析
结构解释图:
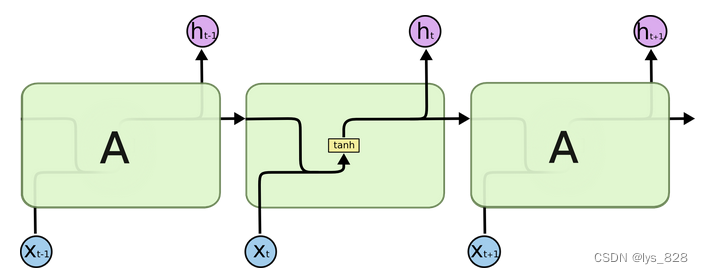
内部结构分析:

我们把目光集中在中间的方块部分, 它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会"融合"到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量[x(t), h(t-1)], 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推.
内部结构过程演示:
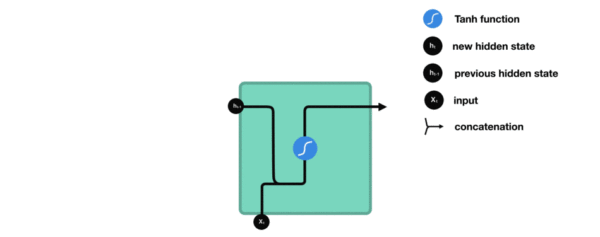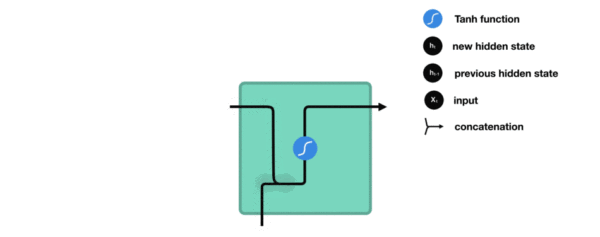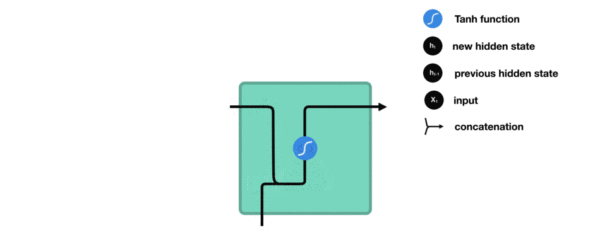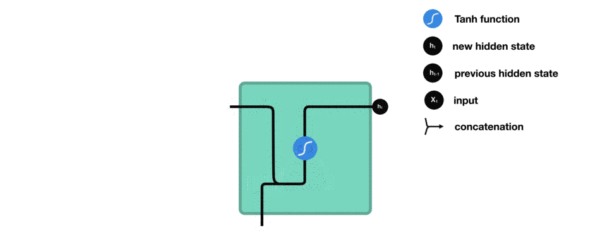
根据结构分析得出内部计算公式: