建设苏州旅游网站的方案策划书单仁营销网站的建设
AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统的 70%+提升到 80%+
该网络的亮点在于:
(1)首次利用 GPU 进行网络加速训练。
(2)使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数。
(3)使用了 LRN 局部响应归一化。
(4)在全连接层的前两层中使用了 Dropout 随机失活神经元操作,以减少过拟合。
模型:
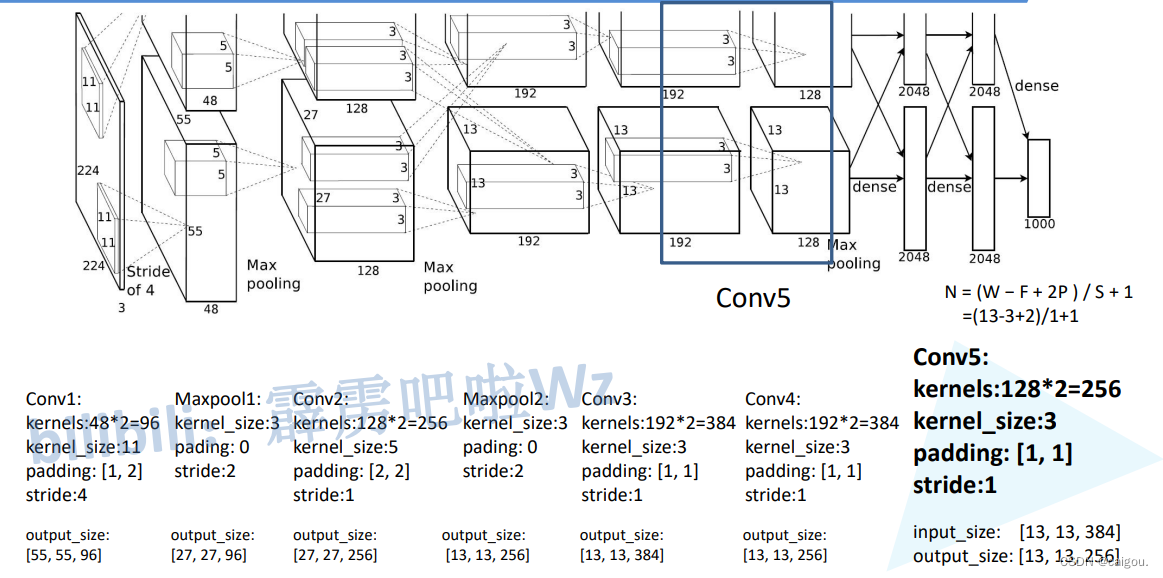
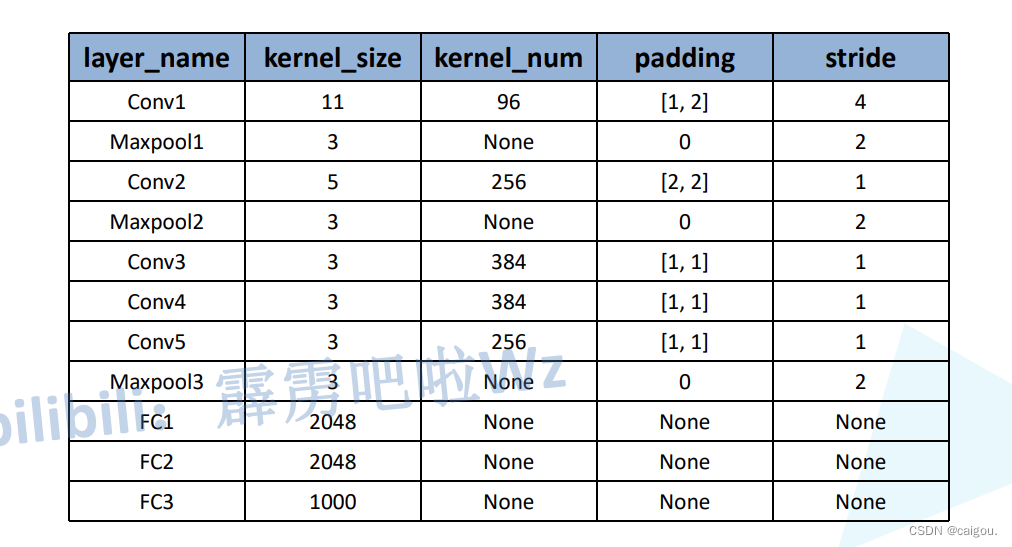
模型参数表:
model.py
import torch.nn as nn
import torchclass AlexNet(nn.Module):def __init__(self, num_classes=1000, init_weights=False):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]: (55-3+0)/4 + 1=27nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6])self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(128 * 6 * 6, 2048),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(2048, 2048),nn.ReLU(inplace=True),nn.Linear(2048, num_classes),)if init_weights:self._initialize_weights()def forward(self, x):x = self.features(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)
train.py
import os
import sys
import jsonimport torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdmfrom model import AlexNetdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))#前期的网络还是用的Normalize标准化,之后的网络会用到BN批标准化data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}data_root = os.path.abspath(os.path.join(os.getcwd(), "../../")) # get data root pathimage_path = os.path.join(data_root, "data_set", "flower_data") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)#注意这里的数据加载还是直接用的torchvision.datasets.ImageFolder加载,#并不需要定义数据加载的脚本,可能是数据比较简单吧#定义数据集时候直接定义数据处理方法,之后torch.utils.data.DataLoader加载数据集加载时候直接调用这里定义的数据处理参数的方法#train文件夹下还有五种花的文件夹,这个具体处理看下面的代码,可能是ImageFolder直接加载文件夹里的图片文件train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])#训练集图片的个数train_num = len(train_dataset)#train_dataset.class_to_idx 是一个字典,将类别名称映射到相应的索引。#下行注释就是flower_list具体内容# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}# cla_dict是一个反转字典,将原始字典 flower_list 的键和值进行交换flower_list = train_dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())# json.dumps() 将 cla_dict 转换为格式化的 JSON 字符串。# 最后,将 JSON 字符串写入名为 class_indices.json 的文件中# indent 参数表示有几类json_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)batch_size = 32#这个代码片段的目的是为了确定在并行计算时使用的最大工作进程数,并确保不超过系统的逻辑 CPU 核心数量和其他限制nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=4, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))# test_data_iter = iter(validate_loader)# test_image, test_label = test_data_iter.next()## def imshow(img):# img = img / 2 + 0.5 # unnormalize# npimg = img.numpy()# plt.imshow(np.transpose(npimg, (1, 2, 0)))# plt.show()## print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))# imshow(utils.make_grid(test_image))net = AlexNet(num_classes=5, init_weights=True)net.to(device)loss_function = nn.CrossEntropyLoss()# pata = list(net.parameters())optimizer = optim.Adam(net.parameters(), lr=0.0002)epochs = 10save_path = './AlexNet.pth'best_acc = 0.0#一个epoch训练多少批次的数据,一批数据32个CWH,即32张图片train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0#这段代码使用了 tqdm 库来创建一个进度条,用于迭代训练数据集 train_loader 中的批次数据#file=sys.stdout 的作用是将进度条的输出定向到标准输出流,即将进度条显示在终端窗口中train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()#更新进度条的描述信息,显示当前训练的轮数、总轮数和损失值#这个loss是批次损失,在进度条上显示出来train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# 验证是训练完一个epoch后进行在验证集上验证,验证准确率net.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:#val_bar 的类型是 tqdm.tqdm,它是 tqdm 库中的一个类。该类提供了迭代器的功能,# 可以用于包装迭代器对象,并在循环中显示进度条和相关信息val_images, val_labels = val_dataoutputs = net(val_images.to(device)) #outputs:[batch_size,num_classes]predict_y = torch.max(outputs, dim=1)[1] #torch.max 返回的第一个元素是张量数值,第二个是对应的索引acc += torch.eq(predict_y, val_labels.to(device)).sum().item()#验证完后计算验证集里所有的正确个数/总个数val_accurate = acc / val_num#总损失/训练总批次,求得平均每批的损失print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()
训练过程:
using cuda:0 device.
Using 8 dataloader workers every process
using 3306 images for training, 364 images for validation.
train epoch[1/10] loss:1.215: 100%|██████████| 104/104 [00:23<00:00, 4.38it/s]
100%|██████████| 91/91 [00:15<00:00, 5.73it/s]
[epoch 1] train_loss: 1.342 val_accuracy: 0.478
train epoch[2/10] loss:1.111: 100%|██████████| 104/104 [00:19<00:00, 5.30it/s]
100%|██████████| 91/91 [00:15<00:00, 5.75it/s]
[epoch 2] train_loss: 1.183 val_accuracy: 0.533
train epoch[3/10] loss:1.252: 100%|██████████| 104/104 [00:19<00:00, 5.30it/s]
100%|██████████| 91/91 [00:15<00:00, 5.75it/s]
[epoch 3] train_loss: 1.097 val_accuracy: 0.604
train epoch[4/10] loss:0.730: 100%|██████████| 104/104 [00:19<00:00, 5.32it/s]
100%|██████████| 91/91 [00:15<00:00, 5.74it/s]
[epoch 4] train_loss: 1.025 val_accuracy: 0.607
train epoch[5/10] loss:0.961: 100%|██████████| 104/104 [00:19<00:00, 5.28it/s]
100%|██████████| 91/91 [00:16<00:00, 5.65it/s]
[epoch 5] train_loss: 0.941 val_accuracy: 0.676
train epoch[6/10] loss:0.853: 100%|██████████| 104/104 [00:19<00:00, 5.31it/s]
100%|██████████| 91/91 [00:15<00:00, 5.82it/s]
[epoch 6] train_loss: 0.915 val_accuracy: 0.659
train epoch[7/10] loss:1.032: 100%|██████████| 104/104 [00:19<00:00, 5.34it/s]
100%|██████████| 91/91 [00:15<00:00, 5.82it/s]
[epoch 7] train_loss: 0.864 val_accuracy: 0.684
train epoch[8/10] loss:0.704: 100%|██████████| 104/104 [00:19<00:00, 5.32it/s]
100%|██████████| 91/91 [00:15<00:00, 5.80it/s]
[epoch 8] train_loss: 0.842 val_accuracy: 0.706
train epoch[9/10] loss:1.279: 100%|██████████| 104/104 [00:19<00:00, 5.30it/s]
100%|██████████| 91/91 [00:15<00:00, 5.83it/s]
[epoch 9] train_loss: 0.825 val_accuracy: 0.714
train epoch[10/10] loss:0.796: 100%|██████████| 104/104 [00:19<00:00, 5.31it/s]
100%|██████████| 91/91 [00:15<00:00, 5.82it/s]
[epoch 10] train_loss: 0.801 val_accuracy: 0.703
Finished TrainingProcess finished with exit code 0predict.py:
import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom model import AlexNetdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")data_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load imageimg_path = "./test.jpg"assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path)plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)# read class_indictjson_path = './class_indices.json'assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)with open(json_path, "r") as f:class_indict = json.load(f)# create modelmodel = AlexNet(num_classes=5).to(device)# load model weightsweights_path = "./AlexNet.pth"assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)#torch.load() 函数会根据路径加载模型的权重,并返回一个包含模型参数的字典#load_state_dict() 函数将加载的模型参数字典应用到 model 中,从而将预训练模型的参数加载到 model 中model.load_state_dict(torch.load(weights_path))model.eval()with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],predict[predict_cla].numpy())plt.title(print_res)for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))plt.show()if __name__ == '__main__':main()
预测结果:
我感觉pycharm的plt显示并不是特别明了
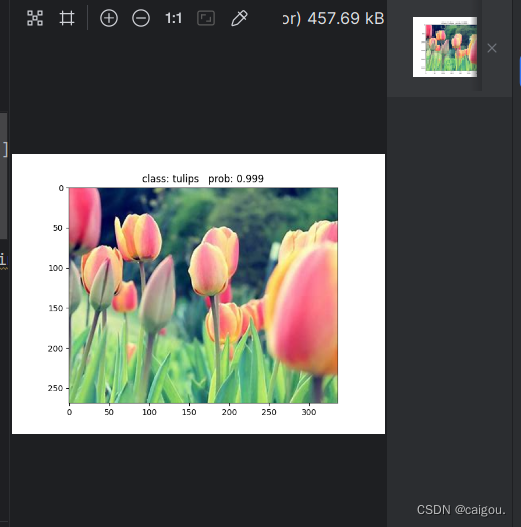
class: daisy prob: 4.2e-06
class: dandelion prob: 9.61e-07
class: roses prob: 0.000773
class: sunflowers prob: 1.28e-05
class: tulips prob: 0.999