广西网站运营网站和自媒体都可以做
一、Flume简介
-
- Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume只能在Unix环境下运行。
-
- Flume基于流式架构,容错性强,也很灵活简单。
-
- Flume、Kafka用来实时进行数据收集,Spark、Flink用来实时处理数据,impala用来实时查询。
二、Flume角色
2.1、Source
用于采集数据,Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel,这个有点类似于Java IO部分的Channel。
2.2、Channel
用于桥接Sources和Sinks,类似于一个队列。
2.3、Sink
从Channel收集数据,将数据写到目标源(可以是下一个Source,也可以是HDFS或者HBase)。
2.4、Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。
三、Flume传输过程
source监控某个文件或数据流,数据源产生新的数据,拿到该数据后,将数据封装在一个Event中,并put到channel后commit提交,channel队列先进先出,sink去channel队列中拉取数据,然后写入到HDFS中。
四、Flume部署及使用
4.1 采集架构
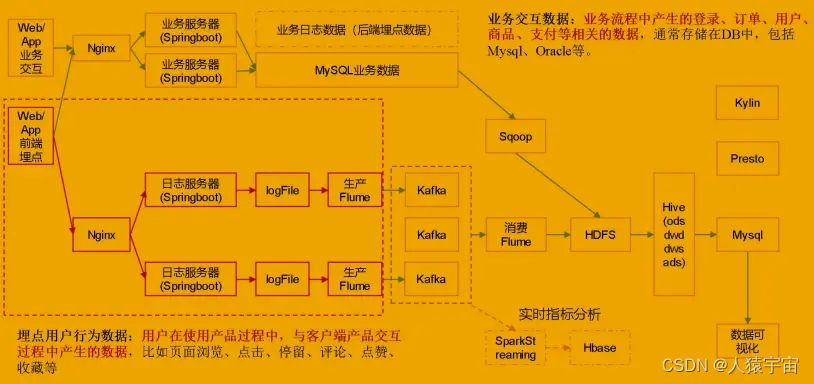
4.2 Flume安装
4.2.1 下载
apache-flume-1.6.0-bin.tar.gz
链接:https://pan.baidu.com/s/1ySmEEObFtKtyT7GsEldnfA
提取码:436t
4.2.2 安装
Flume的安装非常简单,只需要解压即可
tar -zxvf apache-flume-1.6.0-bin.tar.gz
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
在这里,我们使用集群模式,因此,需要把在master节点部署的flume分发到slave节点上:
]# scp -rp apache-flume-1.7.0-bin slave1:KaTeX parse error: Expected 'EOF', got '#' at position 6: PWD ]#̲ scp -rp apache…PWD
4.2.3 测试
采集配置:
vi netcat-logger.conf
# 定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
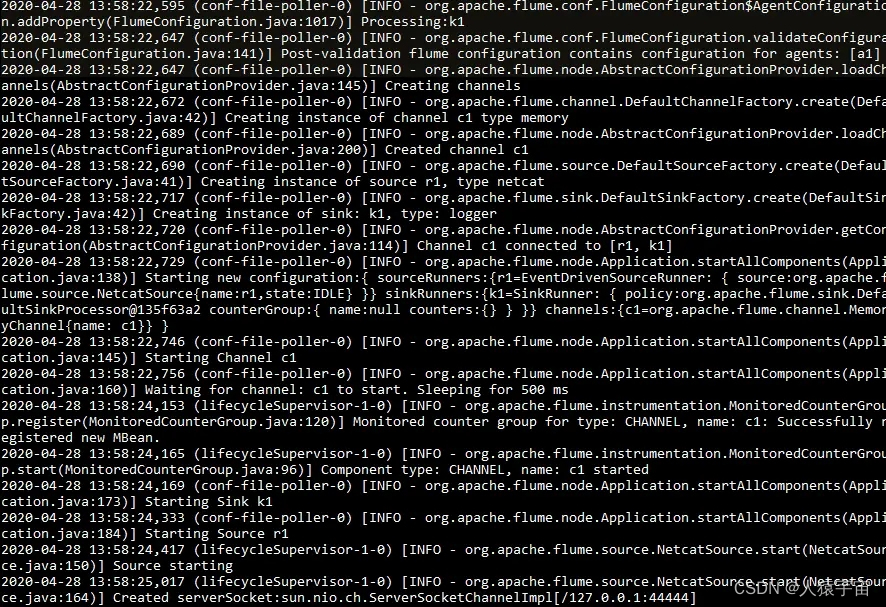
启动agent去采集数据
启动命令:
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
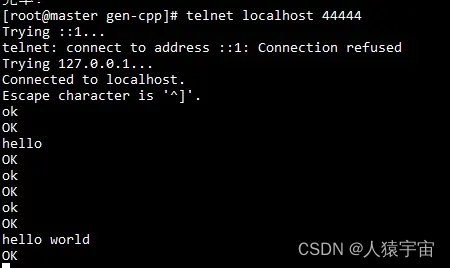
先要往agent采集监听的端口上发送数据,让agent有数据可采
发送命令:
安装telnet:
]# yum install telnet
]# telnet anget-hostname port (telnet localhost 44444)
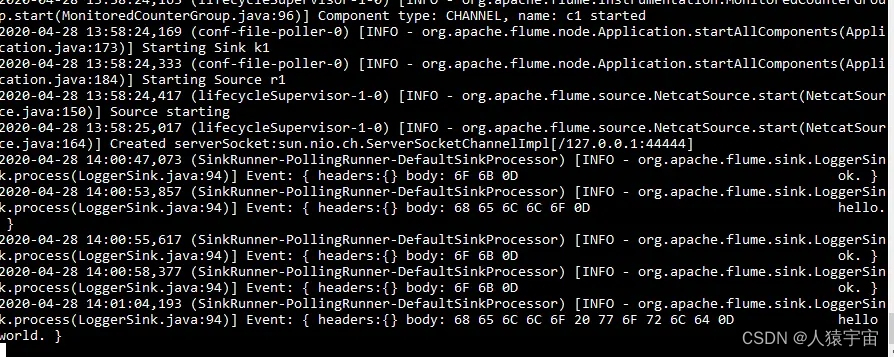
测试输入输出如下图:
4.3 Flume配置
1)Flume 配置分析
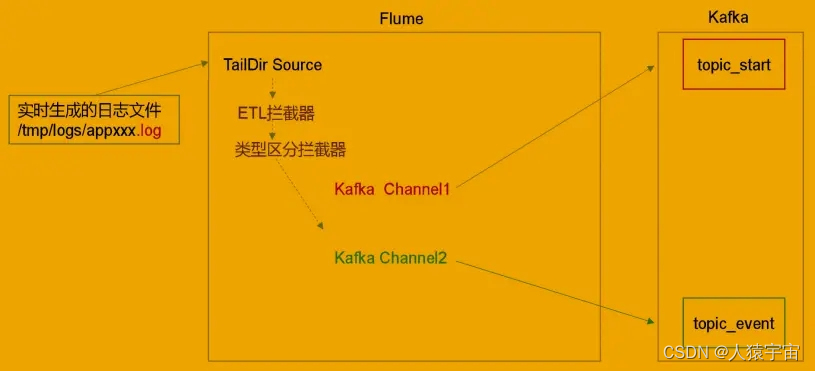
Flume 直接读 log 日志的数据,log 日志的格式是 app-yyyy-mm-dd.log。
2)Flume 的具体配置如下:
(1)在/opt/module/flume/conf 目录下创建 file-flume-kafka.conf 文件
vim file-flume-kafka.conf
a1.sources=r1
a1.channels=c1 c2
#configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /usr/local/src/apache-flume-1.7.0-bin/test/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/log/2020-11-03/app.*.log
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.zgjy.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.zgjy.flume.interceptor.LogTypeInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_resource = c1
a1.sources.r1.selector.mapping.topic_action = c2
# configure channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
a1.channels.c1.kafka.topic = topic_resource
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
# configure channe2
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
a1.channels.c2.kafka.topic = topic_action
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer
测试日志:
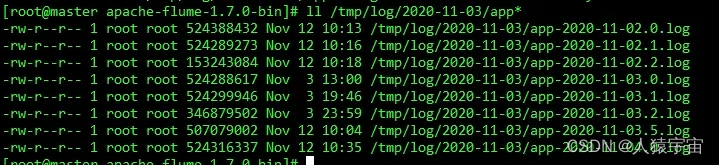
配置说明如下:

4.4 Flume 的 ETL 和分类型拦截器
本项目中自定义了两个拦截器,分别是:ETL 拦截器、日志类型区分拦截器。
ETL 拦截器主要作用:过滤时间戳不合法和 Json 数据不完整的日志
日志类型区分拦截器主要作用:将启动日志和事件日志区分开来,方便发往 Kafka 的不 同 Topic。
1)创建 Maven 工程 flume-interceptor
2)创建包名:com.zgjy.flume.interceptor
3)在 pom.xml 文件中添加如下配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.zgjy</groupId><artifactId>flume-interceptor</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.1.41</version></dependency><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.7.0</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>2.5.3</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration></plugin></plugins></build></project>
4)在 com.zgjy.flume.interceptor 包下创建 LogETLInterceptor 类名
Flume ETL 拦截器 LogETLInterceptor实现代码如下:
package