推广活动策划方案范文中山短视频seo教程
一、说明
成功分析和预测后的绘图预测。
LSTM的核心是递归神经网络(RNN)的变体,专门用于解决困扰传统RNN的梯度消失问题。梯度消失问题是指网络中早期层的梯度变得越来越小,阻碍了它们捕获长期依赖性的能力的现象。LSTM 通过整合存储单元、门和精心设计的连接来克服这一限制,使其能够在较长的时间间隔内有选择地保留和传播信息。这种独特的架构使 LSTM 模型能够捕获顺序数据中错综复杂的时间关系,使其特别适合预测时间序列数据,例如股票价格。
二、LSTM记忆网络
要了解更多回合 LSTM ,请访问 :
了解长短期记忆 (LSTM) 算法
LSTM 算法是帮助机器理解和预测复杂数据的强大工具。了解 LSTM 如何适用于机器学习...
让我们来看看我们的股票数据分析和预测。
2.1 导入所需库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
import math
from sklearn.metrics import mean_squared_error在这里,我们导入了熊猫,用于绘图的matplotlib,用于预处理的numpy,sklearn用于预处理,尺度调整和误差计算,以及用于模型构建的张量流。
2.2 我移植数据集
您可以在以下 GitHub 存储库中找到我使用的数据集。
GitHub - mwitiderrick/stockprice: Stock Price Prediction 教程的数据和笔记本
股票价格预测教程的数据和笔记本 - GitHub - mwitiderrick/stockprice:数据和笔记本...
github.com
df = pd.read_csv('D:/stockprice-master/NSE-TATAGLOBAL.csv')
df.head()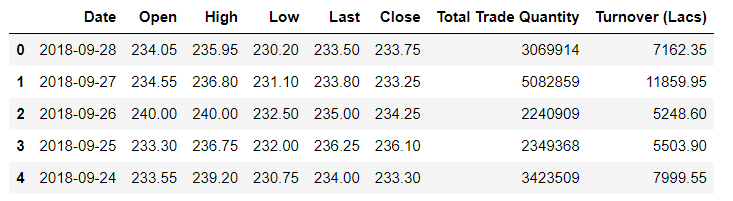
三、数据分析
df2 = df.reset_index()['Close']
plt.plot(df2)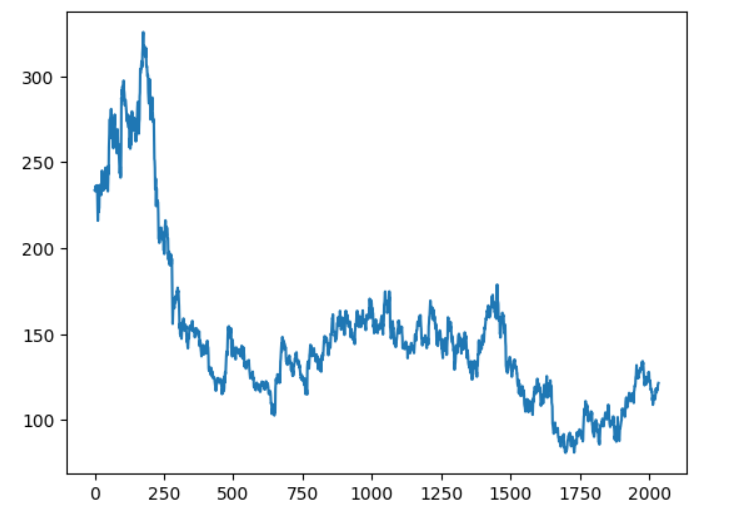
图表显示数据集中的库存流
我们将在收盘价列上进行股票预测。
3.1 数据预处理
scaler = MinMaxScaler()
df2 = scaler.fit_transform(np.array(df2).reshape(-1,1))
df2.shape(2035, 1)
在这里,我们缩小 (0,1) 之间的值。
3.2 训练-测试拆分
train_size = int(len(df2)*0.65)
test_size = len(df2) - train_size
train_data,test_data = df2[0:train_size,:],df2[train_size:len(df2),:1]在这里,我们获取了 65% 的数据用于训练,其余 35% 用于测试。
def create_dataset(dataset, time_step = 1):dataX,dataY = [],[]for i in range(len(dataset)-time_step-1):a = dataset[i:(i+time_step),0]dataX.append(a)dataY.append(dataset[i + time_step,0])return np.array(dataX),np.array(dataY)创建一个函数作为 create_dataset(),它根据我们采取的时间步长将数据集分成 2 个。第一个数据集,即;dataX 将值作为其输入,第二个数据集 dataY 将值作为输出。基本上,它从上述数据集创建一个数据集矩阵。
# calling the create dataset function to split the data into
# input output datasets with time step 100
time_step = 100
X_train,Y_train = create_dataset(train_data,time_step)
X_test,Y_test = create_dataset(test_data,time_step)# checking values
print(X_train.shape)
print(X_train)
print(X_test.shape)
print(Y_test.shape)(1221, 100)
[[0.62418301 0.62214052 0.62622549 ...0.83455882 0.86213235 0.85273693]
[0.62214052 0.62622549 0.63378268 ...0.86213235 0.85273693 0.87111928]
[0.62622549 0.63378268 0.62234477 ...0.85273693 0.87111928 0.84497549]
...
[0.34517974 0.31781046 0.33047386 ...0.2816585 0.27001634 0.26531863]
[0.31781046 0.33047386 0.32128268 ...0.27001634 0.26531863 0.27389706]
[0.33047386 0.32128268 0.34007353 ...0.26531863 0.27389706 0.25347222]](612, 100)(612,)
四、创建和拟合 LSTM 模型
model = Sequential()
model.add(LSTM(50,return_sequences = True,input_shape = (X_train.shape[1],1)))
model.add(LSTM(50,return_sequences = True))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(loss = 'mean_squared_error',optimizer = 'adam')在这里,我们添加了 4 层 LSTM,其中 1 层作为输入层,2 层作为隐藏层,1 层作为输出层作为 Dense。 在前 3 层中,我们取了 50 个神经元和 1 个用于输出。
我们使用亚当优化器编译模型,该优化器将使用均方误差计算损失。
model.summary()
model.fit(X_train,Y_train,validation_data = (X_test,Y_test),epochs = 100,batch_size = 64,verbose = 1)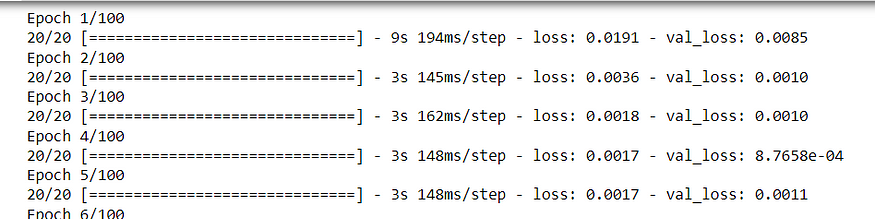

在这里,该模型已经训练了 100 个 epoch,每个 epoch 的批大小为 64。
五、预测和检查性能矩阵
train_predict = model.predict(X_train)
test_predict = model. Predict(X_test)# transform to original form
train_predict = scaler.inverse_transform(train_predict)
test_predict = scaler.inverse_transform(test_predict)当我们在 0 和 1 中缩小数据集的值时,我们需要再次反转变换,以便在图上获得准确的预测值,因此,这里我们反转两个预测的变换。
现在是计算rmse性能矩阵的时候了。
print(math.sqrt(mean_squared_error(Y_train,train_predict)))
print(math.sqrt(mean_squared_error(Y_test,test_predict)))166.74853517776896
116.51567464682968
在这里,计算的两个值都非常接近,即;差值小于 50,表示模型精度良好。
六 图形绘制
look_back = 100trainPredictPlot = np.empty_like(df2)
trainPredictPlot[:,:] = np.nan
trainPredictPlot[look_back : len(train_predict)+look_back,:] = train_predict回看变量采用当前值后面的值数,即;记住与 LSTM 相同的前 100 个值。在这里,每次绘制图形时,trainPredictionPlot 都会在它们后面取 100 个值并绘制它。绘图从前 100 个值开始,一直到火车预测的长度 + 回溯,即 100。
testPredictPlot = np.empty_like(df2)
testPredictPlot[:,:] = np.nan
testPredictPlot[len(train_predict)+(look_back)*2 + 1 : len(df2) - 1,:] = test_predictTestPredictionPlot 也是如此,但这次它采用Train_predict旁边的值。这里回顾将从火车预测结束的地方开始。
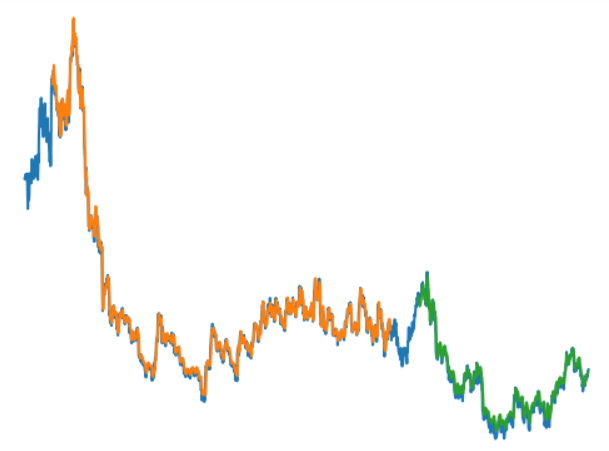
plt.plot(scaler.inverse_transform(df2))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()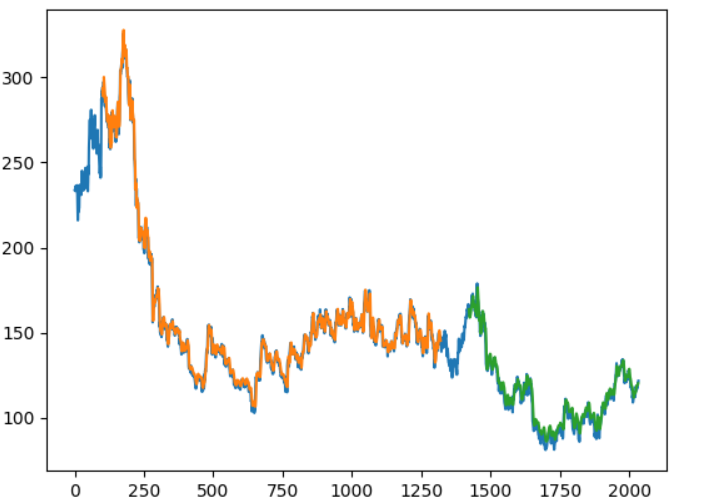
在这里,橙色是TrainPredictionPlot,绿色是TestPredictionPplot,蓝色是实际数据集。因此,我们可以看到我们的模型很好地预测了股票价格。
该模型仅用于学习目的,不建议用于任何未来的投资。普拉吉瓦尔·乔汉
七、结论
总之,利用长期短期记忆(LSTM)进行股票市场预测代表了财务预测领域的重大飞跃。这种基于深度学习力量的创新方法展示了其捕获历史股票市场数据中复杂模式和依赖关系的潜力。通过将LSTM模型纳入投资策略,交易者和投资者可以在驾驭股票市场的不可预测性中获得宝贵的优势。