河南专业的做网站的公司wordpress修改code标签
下载opencv
链接:https://opencv.org/releases/

我下载的是4.7.0,选择windows下载。
下载成功后打开exe文件,选择路径安装。

配置环境变量
安装成功后找到安装目录,复制bin目录路径。
我的是放在了D盘
D:\Opencv4.7.0\opencv\build\x64\vc16\bin
右键此电脑,属性->高级系统设置->环境变量




双击Path,进入编辑点击新建,然后将刚才复制的目录粘贴。


点击确定。
环境变量配置完成。
Visual Studio 配置
新建一个项目,建好之后点击调试,onnx(项目名)属性

选择VC++目录


将D:\Opencv4.7.0\opencv\build\include目录包含进来。

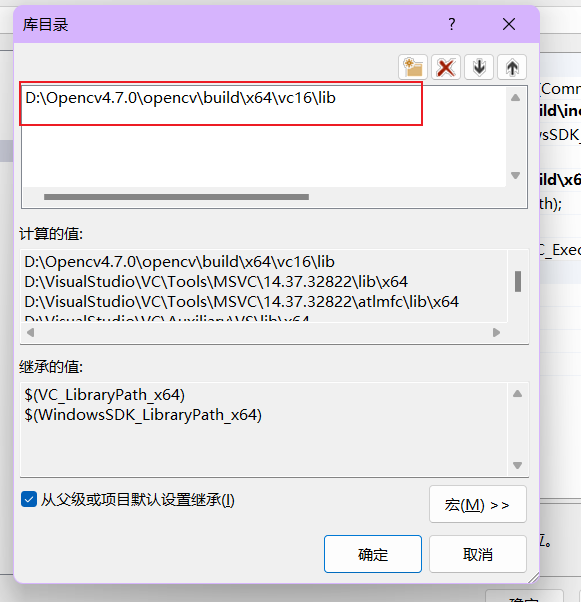
库目录也是一样

将D:\Opencv4.7.0\opencv\build\x64\vc16\lib目录添加在此处。
链接器->输入->附加依赖项,

opencv_world470d.lib
可在D:\Opencv4.7.0\opencv\build\x64\vc16\lib目录下查看自己所下载版本相应的名称。

点击确定。
复制dll文件
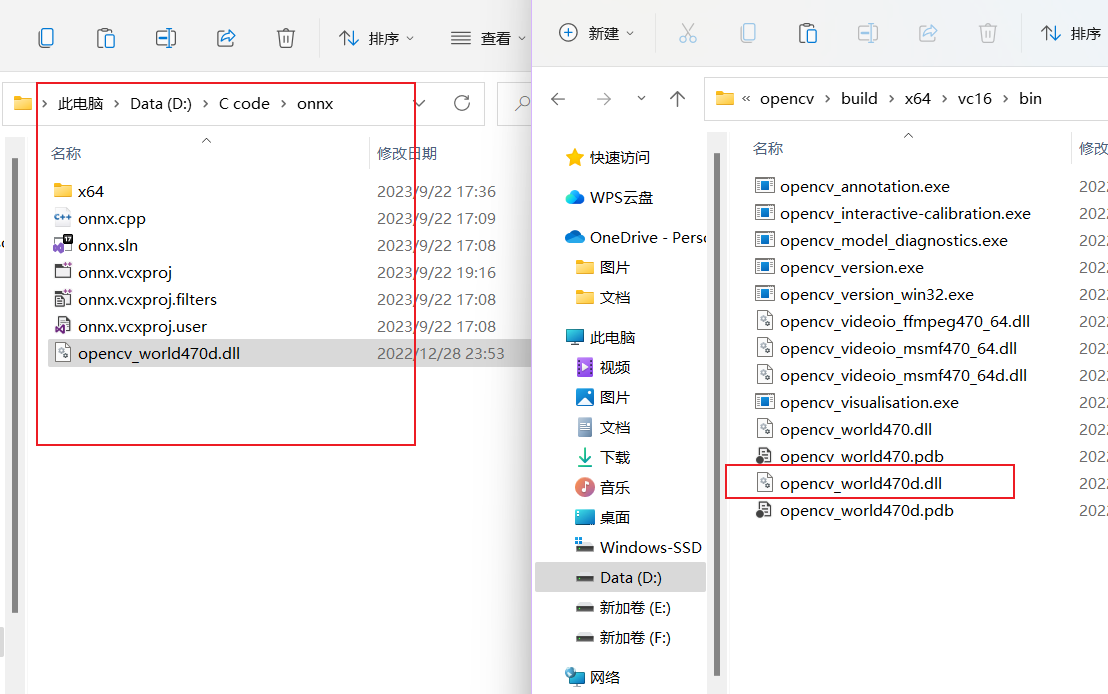
打开项目所在目录

将bin目录下的opencv_world470d.dll复制一份到项目目录。
复制成功之后即可使用。