专门做名片的网站seo网站推广的主要目的是什么
算法设计题
问题1
现有两个单链表A和B,其中的元素递增有序,在不破坏原链表的情况下,请设计一个算法,求这两个链表的交集,并将结果存放在链表C中。
(1)描述算法的基本设计思想;
(2)根据设计思想,给出C语言描述算法,关键之处请给出简要注释。
(1)基本思想:A、B两个链表的元素均递增有序,所以可以按顺序同时从A中和B中各取出一个结点的值来对比;如果A中结点的值比较小,则A中的指针后移;如果B中结点的值比较小,则B中的指针后移;如果相等,则将结点值取出,赋于s结点;并将s结点插入C链表中;然后A、B中的指针分别后移
LinkList getCommon(LinkList A, LinkList B, LinkList &C){C->next = null; //将C置为空链表LNode *r = C;//初始化指针LNode *p = A->next;LNode *q = B->next;while(p!=null && q!=null){if(q->data < p->data){//谁的值小谁右移q = q->next;}else if(p->data < q->data){p = p->next;}else{//值相等都右移LNode *s = (LNode *)malloc(sizeof(LNode));//创建*s结点s->data = p->data;//*s结点赋值r->next = s;//将*s结点写入链表中r = s;//C链表中的指针右移//A、B链表中剩余的元素继续比较p = p->next;q = q->next;}}r->next = null;
}
问题2
若设二叉树T采用二叉链表存储,设计一个算法,求指定结点p的父结点。要求:
(1)描述算法的基本设计思想;
(2)根据设计思想,给出C语言描述算法,关键之处请给出简要注释。
(1)基本思想:利用栈,对二叉树采用后序遍历非递归的方法,当遍历到p结点时,由于是后序遍历方法,栈中所有元素都是p的祖先结点,栈顶就是p的父节点。
void nonPost(BiTree T, BiTree p){InitStack(S);q = T;tag = null;while(q || !isEmpty(S)){if(q){push(S,q);if(q == p){cout << "find father successfully!";return;//找父节点成功}q = q->next;}else{getTop(S,q);if(q->rchild && q->rchild != tag){q = q->rchild;push(S,q);if(q == p){cout << "find father successfully!";return;//找父节点成功}q = q->lchild;}else{pop(S,q);visit(q->data);tag = p;p = null;}}//else}//while
}
选择题错题整理
1.用一个高效的算法删除有序顺序表(n)中的所有元素值为x的元素时,在查找元素x时采用二分查找,此时的时间复杂度为()。
A.O(1) B.O(n) C.O(n^2) D.O(log2n)
正确答案:
D.O(log2n)
试题分析:
2.求删除循环双向链表(带头结点)中p结点的时间复杂度()。
A.O(1) B.O(n) C.O(n^2) D.O(log2n)
正确答案:
B.O(n)
试题分析:
在双向链表中删除结点,主要时找到待删除结点,然后修改相应指针域即可,不需要移动元素,在链表中查找某一元素只能从表头开始顺序查找,而不能随机查找,故时间复杂度为O(n)。
简答题
1.循环队列是如何提出的?如何判别它的空和满?试简述之。
2.列出先序遍历能得到ABC序列的所有不同的二叉树。
3.简要说明深度优先搜索法(DFS)和广度优先搜索法(BFS)的不同之处。
4.简述堆和二叉排序树的区别。
分析计算题
有一组关键字序列{66,89,8,123,9,44,55,37,200,127,98}:
(1)请将其调整成初始大根堆,并画出初始大根堆的树型表示。
(2)采用堆排序实现按关键字递增排序,请画出当有1个最大的关键字已放置到最终位置时,剩余关键字构成的大根堆。
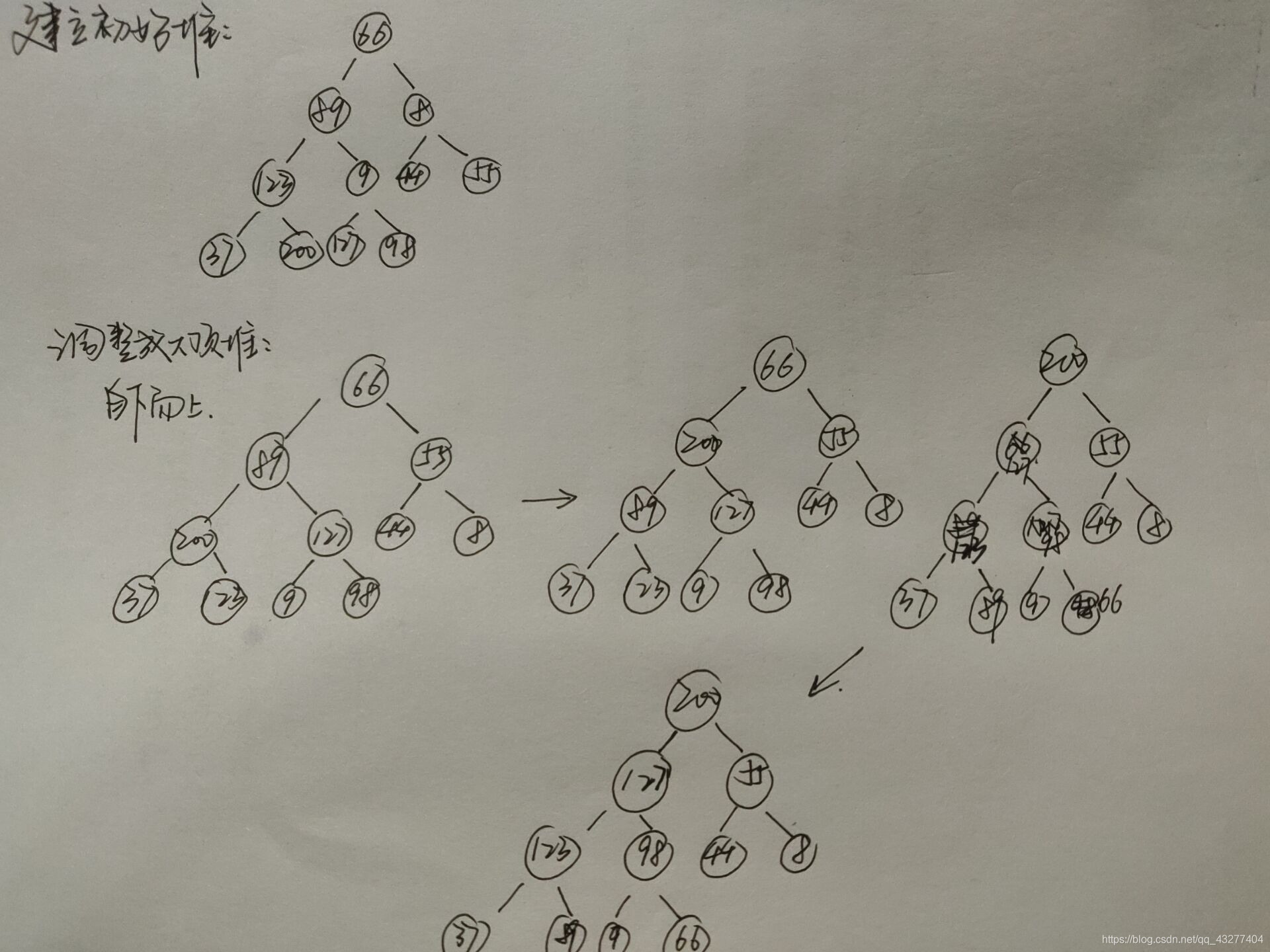
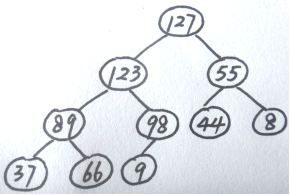
将最终结果最大位,即200输出,200与66替换,继续调整堆,得到以上答案。