一级a做爰片免费网站性恔wordpress一键优化
什么是singleflight
singleflight是一种并发编程设计模式,将同一时刻的多个并发请求合并成一个请求,以减少对下游服务的压力
为什么叫singleflight
fly可以理解为请求数,singleflight就是单个请求
使用场景
该模式主要用于防止缓存击穿
例如当本地缓存失效时,为了防止大量请求都打到远程缓存redis,可以用singleflight保证该时刻只会有一个请求发到远程缓存:

或者当远程缓存失效时,为了防止大量请求都打到db,可以用singleflight保证该时刻只有一个请求发往db查询数据:

本文将比较go-zero和官方库对singleflight的实现
Go-zero
代码地址:https://github.com/zeromicro/go-zero/blob/master/core/syncx/singleflight.go
go-zero中对singleflight的定义如下:
type (SingleFlight interface {Do(key string, fn func() (any, error)) (any, error)DoEx(key string, fn func() (any, error)) (any, bool, error)}call struct {wg sync.WaitGroupval anyerr error}flightGroup struct {calls map[string]*calllock sync.Mutex}
)
-
SingleFlight:接口定义,调Do或DoEx用单并发的方式对资源发起请求
- 参数key:资源的标识
- 参数fn:真正请求获取资源的方法
- DoEx的第二个返回值bool: 表示从共享获取的,还是发起真实请求获取的
-
call:表示同一时刻对一个资源的一组请求
- wg:这一组的goroutine都阻塞在该wg上
- val,err:请求的返回值,err
-
flightGroup:总控结构
- calls:维护了正在执行中的call
我们看Do做了啥
func (g *flightGroup) Do(key string, fn func() (any, error)) (any, error) {c, done := g.createCall(key)if done {return c.val, c.err}g.makeCall(c, key, fn)return c.val, c.err
}
首先调g.createCall(key)创建call
如果此时已经有其他协程发起了对call的请求,当前协程就阻塞住,等待拿到结果后直接返回
如果done为false,表示当前协程是第一个发起 call 的协程,那执行g.makeCall(c, key, fn)发起真正的call请求
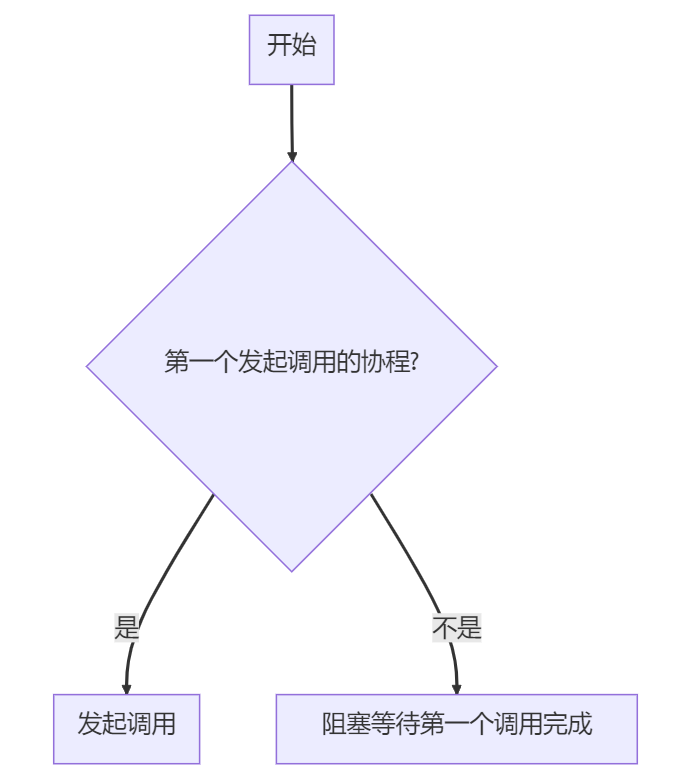
createCall实现如下:
func (g *flightGroup) createCall(key string) (c *call, done bool) {g.lock.Lock()if c, ok := g.calls[key]; ok {g.lock.Unlock()c.wg.Wait()return c, true}c = new(call)c.wg.Add(1)g.calls[key] = cg.lock.Unlock()return c, false
}
- 其实就干了一件事:判断是不是第一个对key的调用
-
- 不是:阻塞在c.wa上
- 是:创建call
接下来看makeCall:
func (g *flightGroup) makeCall(c *call, key string, fn func() (any, error)) {defer func() {g.lock.Lock()delete(g.calls, key)g.lock.Unlock()c.wg.Done()}()c.val, c.err = fn()
}
真正执行fn方法,执行完毕后:
- 将key从calls中删除,这样下一组并发请求到来时,会重新发起真正的请求,获取新值
- 调用wg.done(),这样之前阻塞在wg的协程都会获得结果,并返回
官方库
接下来看看go官方库对singleflight的实现
代码地址:https://cs.opensource.google/go/x/sync/+/036812b2:singleflight/singleflight.go
除了也实现了go-zero的Do方法外,官方库另外提供了DoChan的模式:
- 无论是第一个还是非第一个协程,都不阻塞在DoChan的调用中,而是返回一个channel,可以当需要读数据时才从channel中获取
- 也就是说将是否阻塞获取调用结果的权力交给调用方
看看详细过程:DoChan
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result {ch := make(chan Result, 1)g.mu.Lock()if g.m == nil {g.m = make(map[string]*call)}if c, ok := g.m[key]; ok {c.dups++c.chans = append(c.chans, ch)g.mu.Unlock()// 返回channelreturn ch}c := &call{chans: []chan<- Result{ch}}c.wg.Add(1)g.m[key] = cg.mu.Unlock()// 异步发起调用go g.doCall(c, key, fn)// 非阻塞的返回channelreturn ch
}
那什么时候往channel塞数据呢?在doCall调用成功后,将返回值挨个发送到等待的channel中
for _, ch := range c.chans {ch <- Result{c.val, c.err, c.dups > 0}
}